
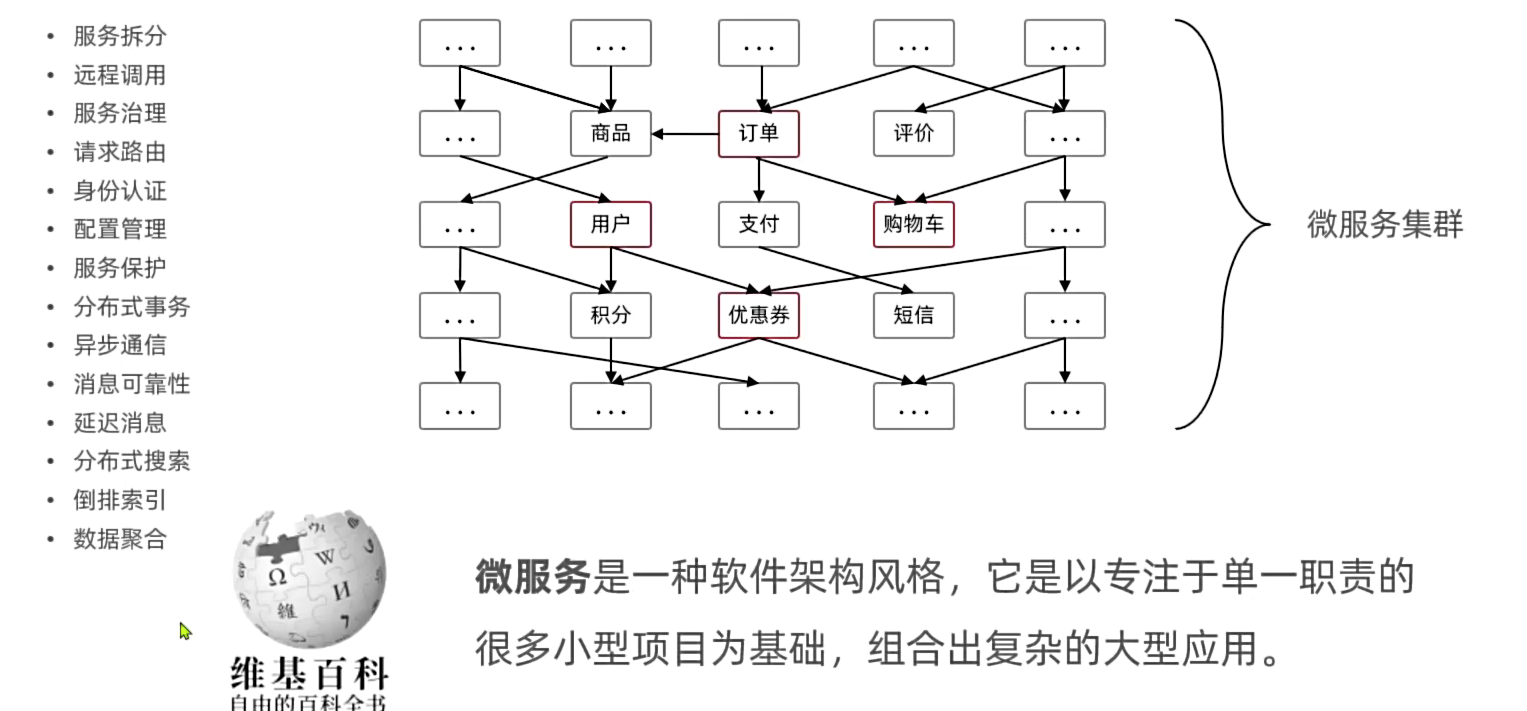
微服务的认识
- 微服务是一种软件架构风格,它是以专注于单一职责的很多小型项目为基础,组合出复杂的大型应用
- 单体架构不适合大型企业项目,但是适合小型项目
- 原先是代码分层解耦,现在是把项目按照功能需求也进行解耦,让多个团队可以同时进行独立开发,独立去部署,独立去运行,互不干扰。
MybaitsPlus
初识
MybaitsPlus的链接:https://www.baomidou.com/
用法
1.特点
Plus并不是Mybaits的替代品
两者是可以一起使用的,是搭档,MybaitsPlus对于Mybaits无侵害性的。
引入依赖的时候,可以只引入Plus的依赖,因为MyBatisPlus官方提供了starter,其中集成了Mybatis和MybatisPlus的所有功能,并且实现了自动装
配效果。而且 MyBatis-Plus 本身就提供了内置的分页插件,同时也支持单表直接使用
因此我们可以用MybatisPlus的starter代替Mybatis的starter:
1
2
3
4
5
6<!--MybatisPlus-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.3.1</version>
</dependency>
2.自定义的Mapper继承MybatisPlus提供的BaseMapper接口:
(为什么要继承因为,BaseMapper已经提前写好了大量的增删改查的SQL语句)
1 | public interface UserMapperextends BaseMapper<User> { |
3.Mapper.xml里面的语句都可以删掉了,直接调用Plus里面的方法
个人想法:
.xml文件语句以及Plus应该是怎么方便这么来,怎么符合需求这么来
Plus明显在单表操作方面十分方便,.xml语句在多表十分强大
常见注解
MyBatisPlus通过扫描实体类,并基于反射获取实体类信息作为数据库表信息。
Plus做的事(我们的实体类也要遵守这个约定):
- 类名驼峰转下划线作为表名
- 名为id的字段作为主键
- 变量名驼峰转下划线作为表的字段名
约定>配置,但是如果没有按照约定,还是可以通过配置去使用的
- @TableName:用来指定表名
- @Tableld:用来指定表中的主键字段信息
- @TableField:用来指定表中的普通字段信息
1.IdType枚举
| 枚举值 | 说明 |
|---|---|
| AUTO | 数据库自增长(依赖数据库的AUTO_INCREMENT) |
| INPUT | 通过set方法自行输入ID(需手动为实体对象赋值ID) |
| ASSIGN_ID | 分配ID,调用IdentifierGenerator接口的nextId方法生成ID,默认实现类为DefaultIdentifierGenerator(雪花算法) |
2.使用@TableField的常见场景:
- 成员变量名与数据库字段名不一致
- 成员变量名以is开头,且是布尔值
- 成员变量名与数据库关键字冲突
- 成员变量不是数据库字段
雪花算法:
雪花算法(Snowflake) 就像一个给数据生成“身份证号”的机器,它能快速、不重复地给每个数据分配一个唯一的ID。它的原理很简单:
分段拼凑ID:
生成的ID是一个数字(比如 485154634240),由4部分
拼成:
- 第1段:时间戳(毫秒级)—— 保证ID随时间增大。
- 第2段:机器ID —— 比如服务器编号,避免多台机器冲突。
- 第3段:序列号 —— 同一毫秒内多个ID的序号(从0递增)。
1 | | 时间戳 | 机器ID | 序列号 | |
- 特点:
- 不重复:机器ID和时间戳保证唯一性。
- 按时间排序:ID越新,数字越大。
- 高性能:本地生成,无需网络调用。
举个栗子🌰: 假设你在电商系统下单,雪花算法会给你的订单生成一个ID,比如 123456789012345678。即使同一秒有1万人下单,每个人的ID也绝不重复。
适用场景: 分布式系统(如订单、用户ID、消息等)需要快速生成唯一ID的场景。
例如:
名称:tb_user 注释:用户表
| # | 名称 | 数据类型 | 注释 | 默认值 |
|---|---|---|---|---|
| 1 | id | BIGINT | 用户id | AUTO_INCREMENT |
| 2 | username | VARCHAR | 用户名 | 无默认值 |
| 3 | is_married | BIT | 密码 | 0 |
| 4 | order | TINYINT | 序号 | NULL |
1 |
|
个人想法
- 第一要遵守约定,这样可以少掉很多麻烦
- 第二要记住一定要设置@TableId的type属性,即是否自增。除非你已经在.yml文件配置mp的全局id-type属性
- 第三字段的类型也要一致
常见配置
MyBatisPlus的配置项继承了MyBatis原生配置和一些自己特有的配置。例如:
1 | mybatis-plus: |
一些属性有默认值,可以不去设置
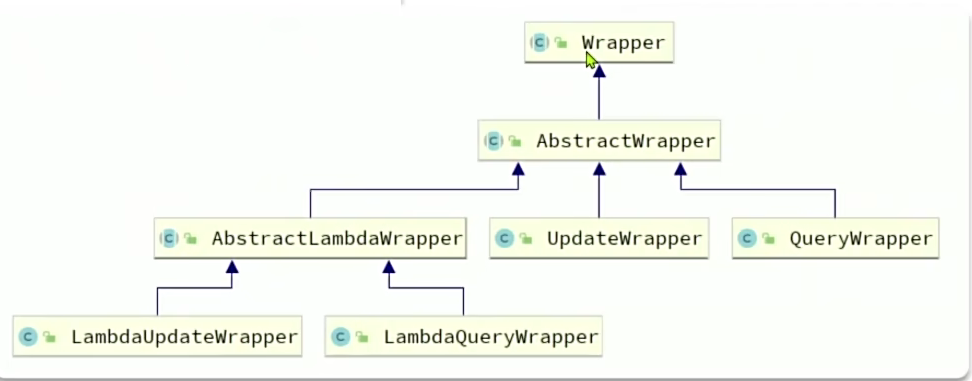
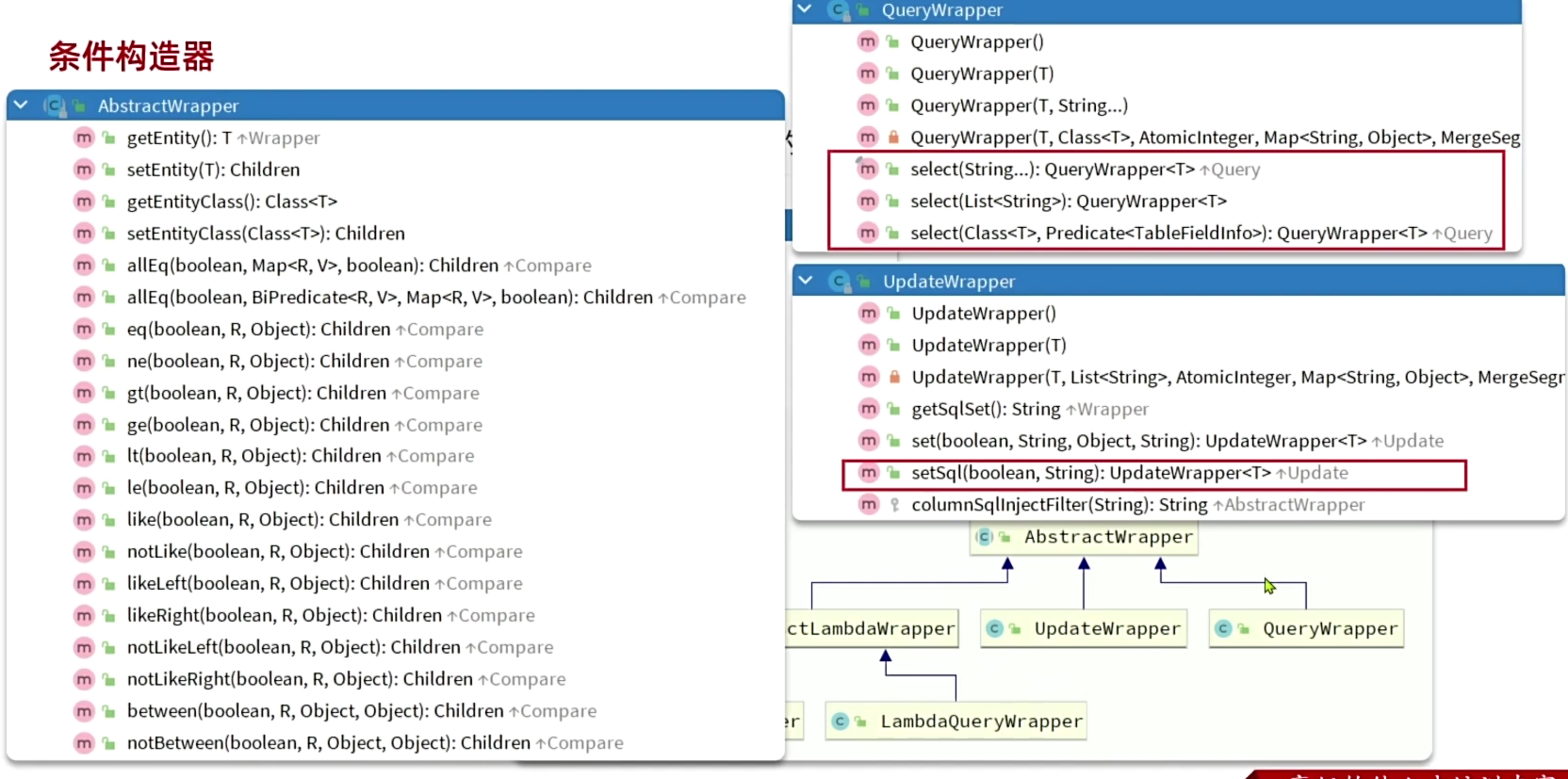
条件构造器
MyBatisPlus支持各种复杂的where条件,可以满足日常开发的所有需求。
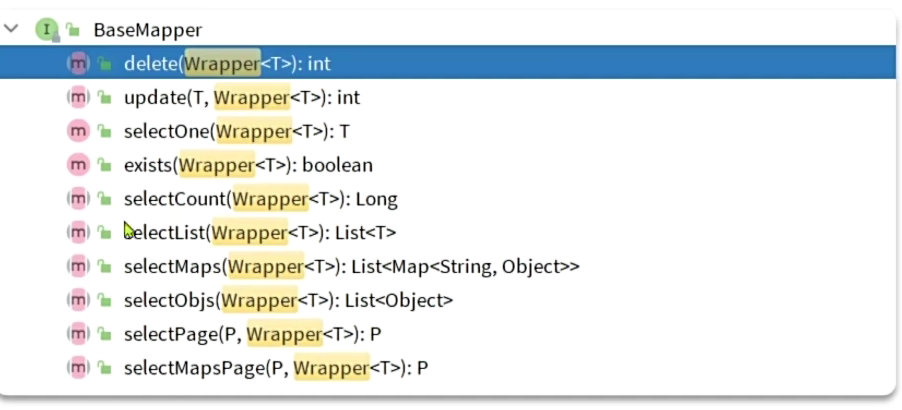
BaseMapper的方法
继承体系
各种构造SQL的方法
演示
基于QueryWrapper的查询
需求:
查询出名字中带o的,存款大于等于1000元的人的id、username、info、balance字段
1
2
3
4
5
6
7
8
9
10
11
12
13SELECT id,username,info,balance FROM user where username LIKE ? AND balance >=? //SQL
void testQueryWrapper() {
//1.构建查询条件
QueryWrapper <User> wrapper =new QueryWrapper<>()
.select("id","username","info","balance")
.like("username","o")
.ge("blance",1000);
//2.查询
List<User> users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}更新用户名为jack的用户的余额为2000
1
2
3
4
5
6
7
8
9
10
11
12UPDATE user SET balance =2000 WHERE (username ="jack") //SQL
void testUpdateBYQueryWrapper(){
//1.要更新的条件
User user =new User();
user.setBalance(2000);
//2.更新的条件
QueryWrapper<User> wrapper =new QueryWrapper<User>().eq("username","jack");
//3.执行更新
userMapper.update(user,wrapper);
}
这两个代码都是写死的,不太好,毕竟是测试代码
基于updateWrapper的更新
需求:更新id为1,2,4的用户的余额,扣200
1 | UPDATE user SET balance = balance-200 WHERE id in(l,2,4) //SQL |
基于LambdaQueryWrapper的非硬编码
1 |
|
个人理解
- QueryWrapper和LambdaQueryWrapper通常用来构建select、delete、update的where条件部分
- UpdateWrapper和LambdaUpdateWrapper通常只有在set语句比较特殊才使用
- 尽量使用LambdaQueryWrapper和LambdaUpdateWrapper避免硬编码
自定义SQL
我们可以利用MyBatisPlus的Wrapper来构建复杂的where条件,然后自己定义SQL语句中剩下的部分。
之前没有额外条件的SQL都是mp的全自动方法
而现在有特定条件的SQL就是属于半自动
演示
需求:将id在指定范围的用户(例如1、2、4)的余额扣减指定值
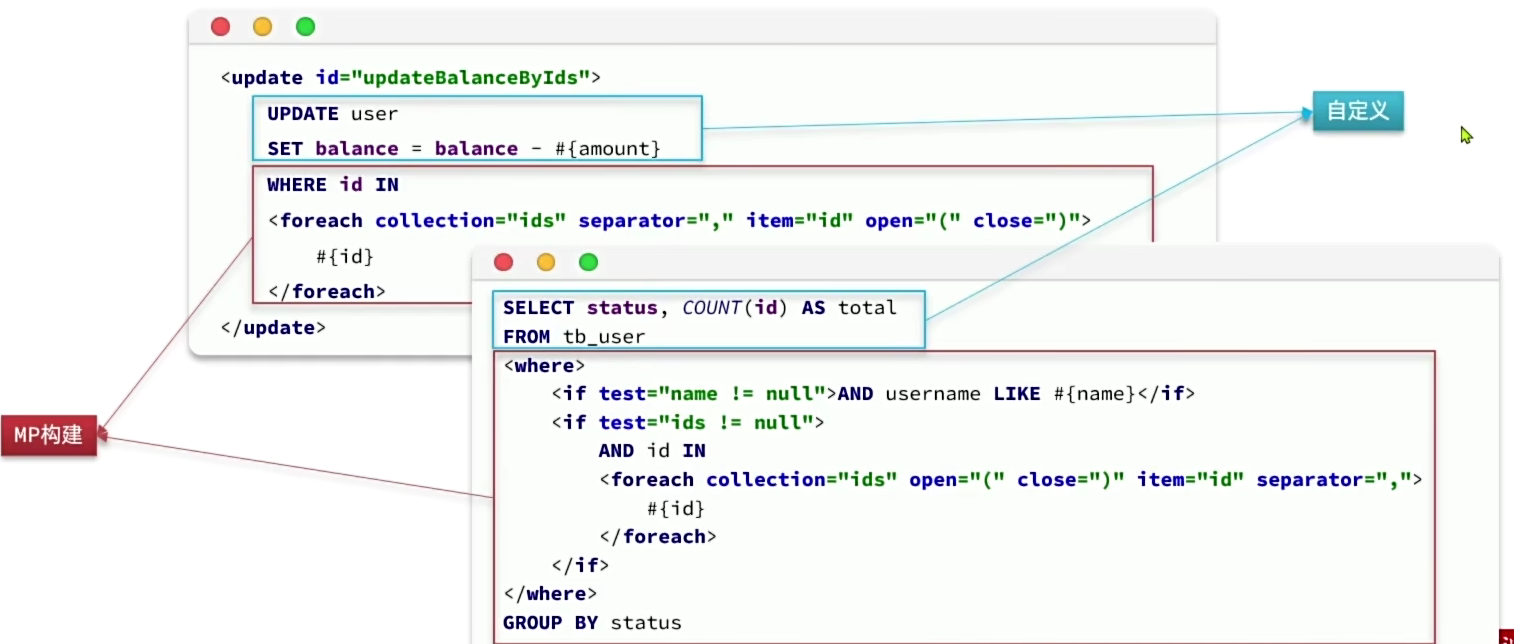
我们可以利用MyBatisPlus的wrapper来构建复杂的where条件,然后自己定义sQL语句中剩下的部分。
基于wrapper构建where条件(ServiceImpl)
1
2
3
4
5
6List<Long> ids =List.of(1L,2L,4L);
int amount = 200;
//1.构建条件
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<User>().in(User::getId,ids);
//2.自定义SQL方法调用
userMapper.updateBalanceByIds(wrapper,amount);在mapper方法参数中用Param注解声明wrapper变量名称,必须是ew(Mapper)
1
void updateBalanceByIds( LambdaQueryWrapper<User>wrapper, int amount);
自定义sQL,并使用wrapper条件(.xml)
1
2
3<updateid="updateBalanceByIds">
UPDATE tb_user SET balance = balance - #{amount} ${ew.customSqlSegment}
</update>
IService接口
方法
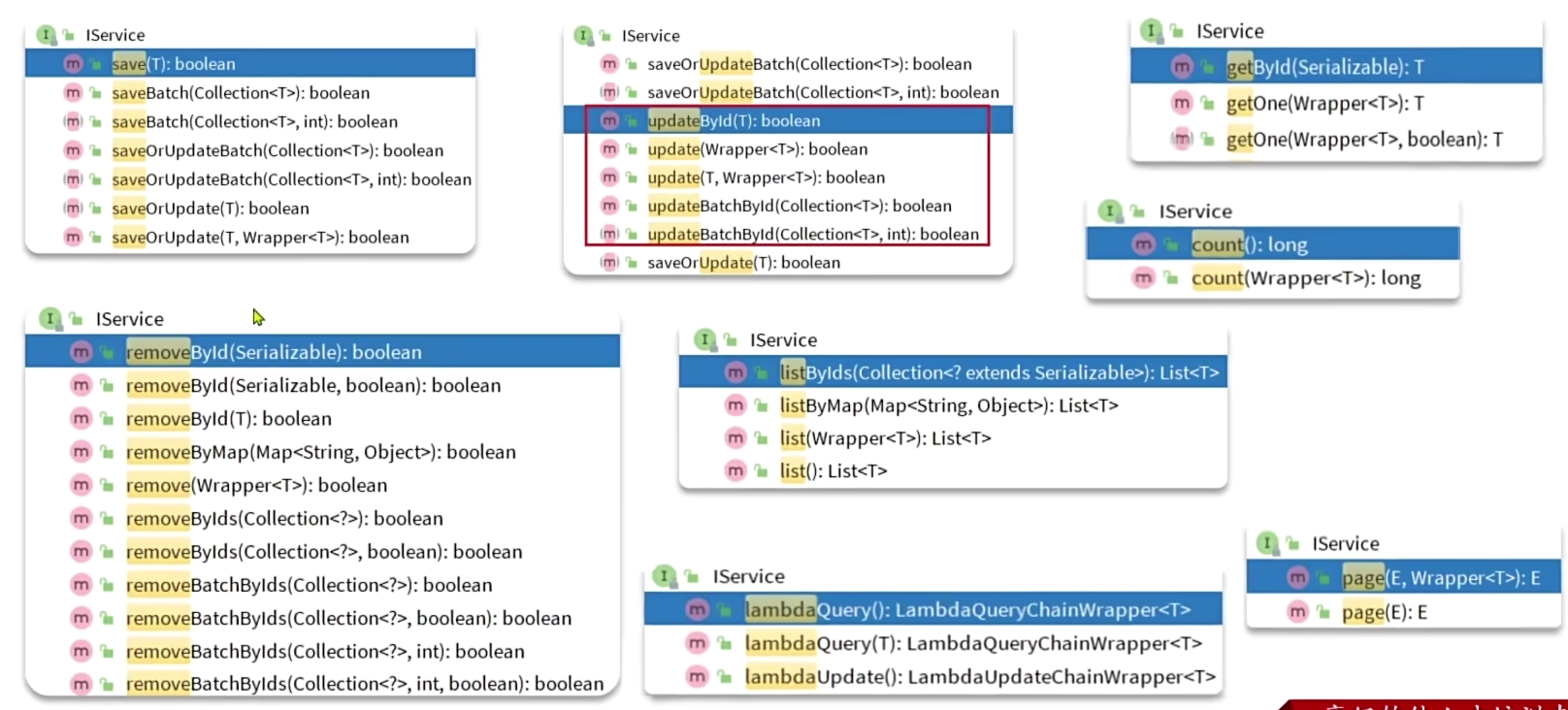
大部分情况都是传id的,如果是复杂情况就是构造Wrapper
- 传id的用各自的方法
- 需要构造Wrapper就使用Lambda方法
- 删除比较特殊,只能使用自己的方法
使用
1 | public interface IUserService extends IService <User> { |
IService的简单接口,非复杂逻辑
需求:基于Restful风格实现下面的接口:
| 编号 | 接口 | 请求方式 | 请求路径 | 请求参数 | 返回值 |
|---|---|---|---|---|---|
| 1 | 新增用户 | POST | /users | 用户表单实体 | 无 |
| 2 | 删除用户 | DELETE | /users/{id} | 用户id | 无 |
| 3 | 根据id查询用户 | GET | /users/{id} | 用户id | 用户VO |
| 4 | 根据id批量查询 | GET | /users | 用户id集合 | 用户VO集合 |
由于IUserService是继承自带的API,所以在注入的时候,Spring会推荐去构造函数,但是还可以这样
1 | @RequiredArgsConstructor |
IService的复杂逻辑使用
| 5 | 根据id扣减余额 | PUT | /users/{id}/deduction/{money} | - 用户id- 扣减金额 | 无 |
|---|
1 |
|
IService的Lambda
查询
需求:实现一个根据复杂条件查询用户的接口,查询条件如下:
- name:用户名关键字,可以为空
- status:用户状态,可以为空
- minBalance:最小余额,可以为空
- maxBalance:最大余额,可以为空
原本的查询:
1 | <select id="queryUsers"resultType="com.itheima.mp.domain.po.User"> |
Lambda查询
1 |
|
更新
需求:改造根据id修改用户余额的接口,要求如下
- 完成对用户状态校验
- 完成对用户余额校验
- 如果扣减后余额为0,则将用户status修改为冻结状态(2)
Lambda更新
1 |
|
IService的批量新增
需求:批量插入10万条用户数据,并作出对比:
- 普通for循环插入
- IService的批量插入
1 | private User buildUser(int i) { |
saveBatch是通过List集合的方式把大部分的插入写成一条SQL语句,这样几条的请求就变成一条,就会快很多
关键点在于开启rewriteBatchedStatements=true参数
在数据源 URL 中添加参数:
1 | # application.yml 配置 |
批处理方案:
- 普通for循环逐条插入速度极差,不推荐
- MP的批量新增,基于预编译的批处理,性能不错
- 配置jdbc参数,开rewriteBatchedStatements,性能最好
代码生成器(应该挺好用的)
使用MybatisPlus插件生成代码
步骤1:配置数据库连接
- 点击IDEA菜单栏的Tools → Config Database
- 在弹出的窗口中,填写您的数据库连接信息,包括地址、用户名和密码等
步骤2:选择要生成代码的数据库表
- 在数据库连接列表中,展开您的数据库
- 选中需要生成代码的表(可多选)
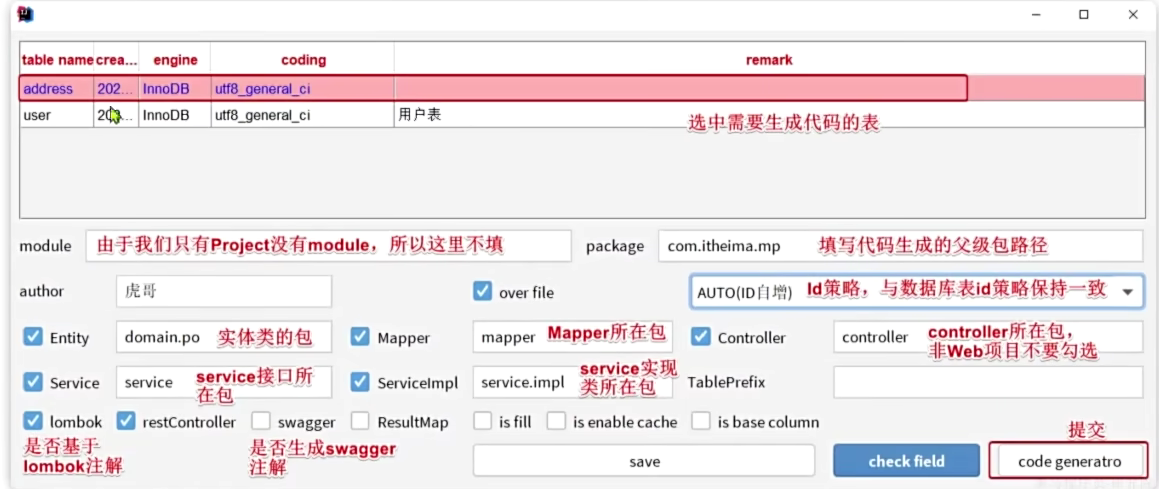
步骤3:配置代码生成选项
- 右键选中的表,选择”Code Generator”选项
- 在弹出的配置窗口中,您可以自定义各种生成选项,如包名、作者信息等
步骤4:生成代码
配置完成后,点击”OK”按钮,插件将自动为您生成所需的全套代码,包括:
- Controller层
- Service层
- ServiceImpl实现类
- Mapper接口
- XML映射文件
- 实体类(Entity)
生成代码的特点
使用此插件生成的代码具有以下优势:
- 符合MybatisPlus规范: 生成的代码完全遵循MybatisPlus的最佳实践。
- 包含必要注解: 自动添加常用注解,如Swagger文档注解,简化API文档编写。
- 结构清晰: 生成的代码层次分明,易于理解和维护。
- 可定制性强: 可根据项目需求自定义模板和生成选项
DB静态工具
方法
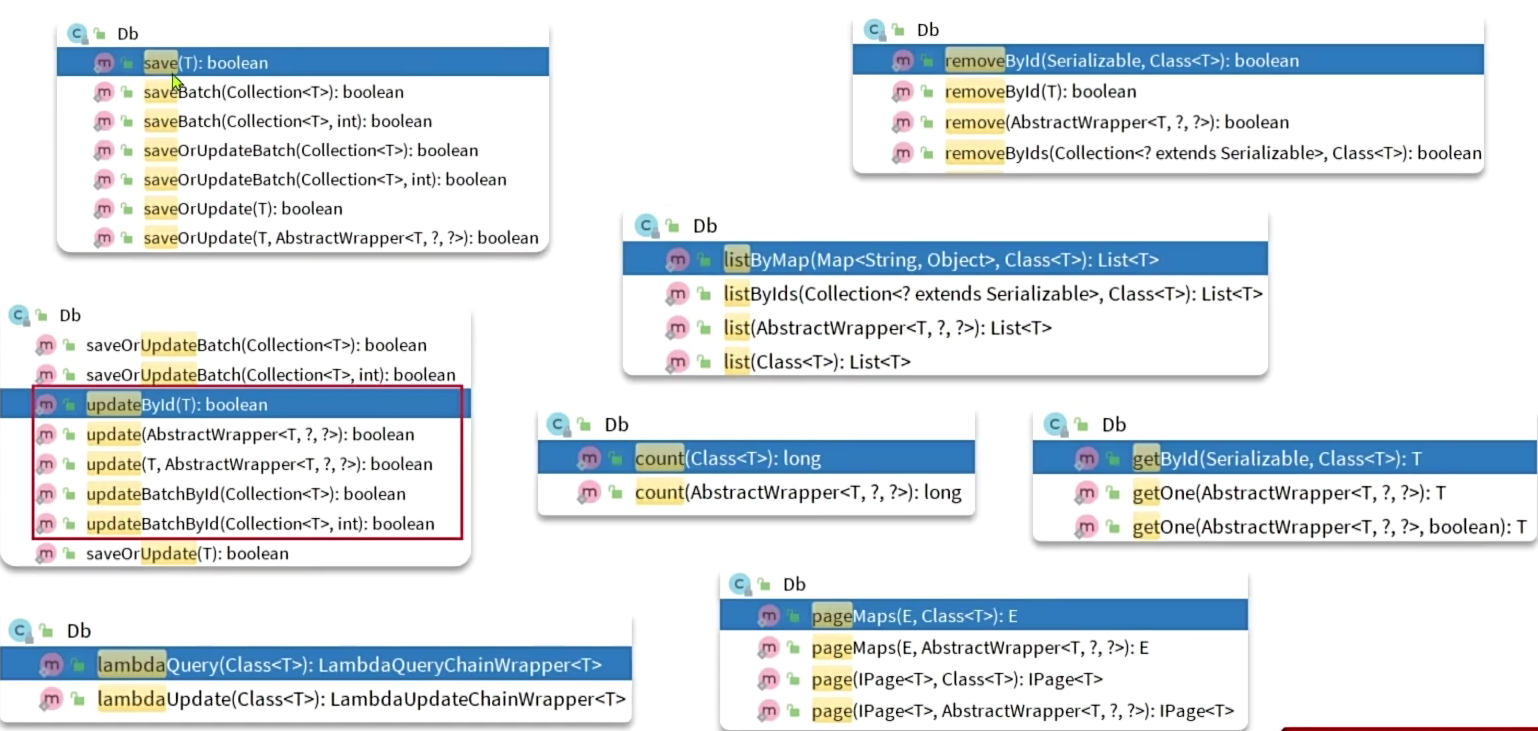
IService的方法是非静态的,而DB的方法是静态的,因为D的方法需要指定泛型,所以不会产生依赖循环
| 工具 | 适用场景 | 优势 |
|---|---|---|
| IService | Spring管理的类(如Controller、Service)、复杂业务逻辑(如事务、多表关联) | 支持事务、多表操作、Spring生态集成 |
| DB静态工具 | 非Spring管理的类(工具类、静态方法)、简单查询、泛型/动态实体、快速测试 | 无需注入、代码简洁、灵活便捷 |
查询
需求:
- 改造根据id查询用户的接口,查询用户的同时,查询出用户对应的所有地址
- 改造根据id批量查询用户的接口,查询用户的同时,查询出用户对应的所有地址
- 实现根据用户id查询收货地址功能,需要验证用户状态,冻结用户抛出异常(练习)
1 |
|
批量改造
1 |
|
逻辑删除(应该挺好用的)
逻辑删除就是基于代码逻辑模拟删除效果,但并不会真正删除数据。思路如下:
- 在表中添加一个字段标记数据是否被删除
- 当删除数据时把标记置为1
- 查询时只查询标记为0的数据
例如逻辑删除字段为deleted:
- 删除操作:
1 | UPDATE user SET deleted = 1 WHERE id = 1 AND deleted = 0 |
- 查询操作:
1 | SELECT * FROM user WHERE deleted = 0 |
MybatisPlus提供了逻辑删除功能,无需改变方法调用的方式,而是在底层帮我们自动修改CRUD的语句。我们要做的就是在application.yaml文件中配置逻辑删除的字段名称和值即可:
1 | mybatis-plus: |
注意
逻辑删除本身也有自己的问题,比如:
- 会导致数据库表垃圾数据越来越多,影响查询效率
- SQL中全都需要对逻辑删除字段做判断,影响查询效率
- 因此,我不太推荐采用逻辑删除功能,如果数据不能删除,可以采用把数据迁移到其它表的办法。
枚举处理器(和定义常量类有什么区别,但还是可以用的)
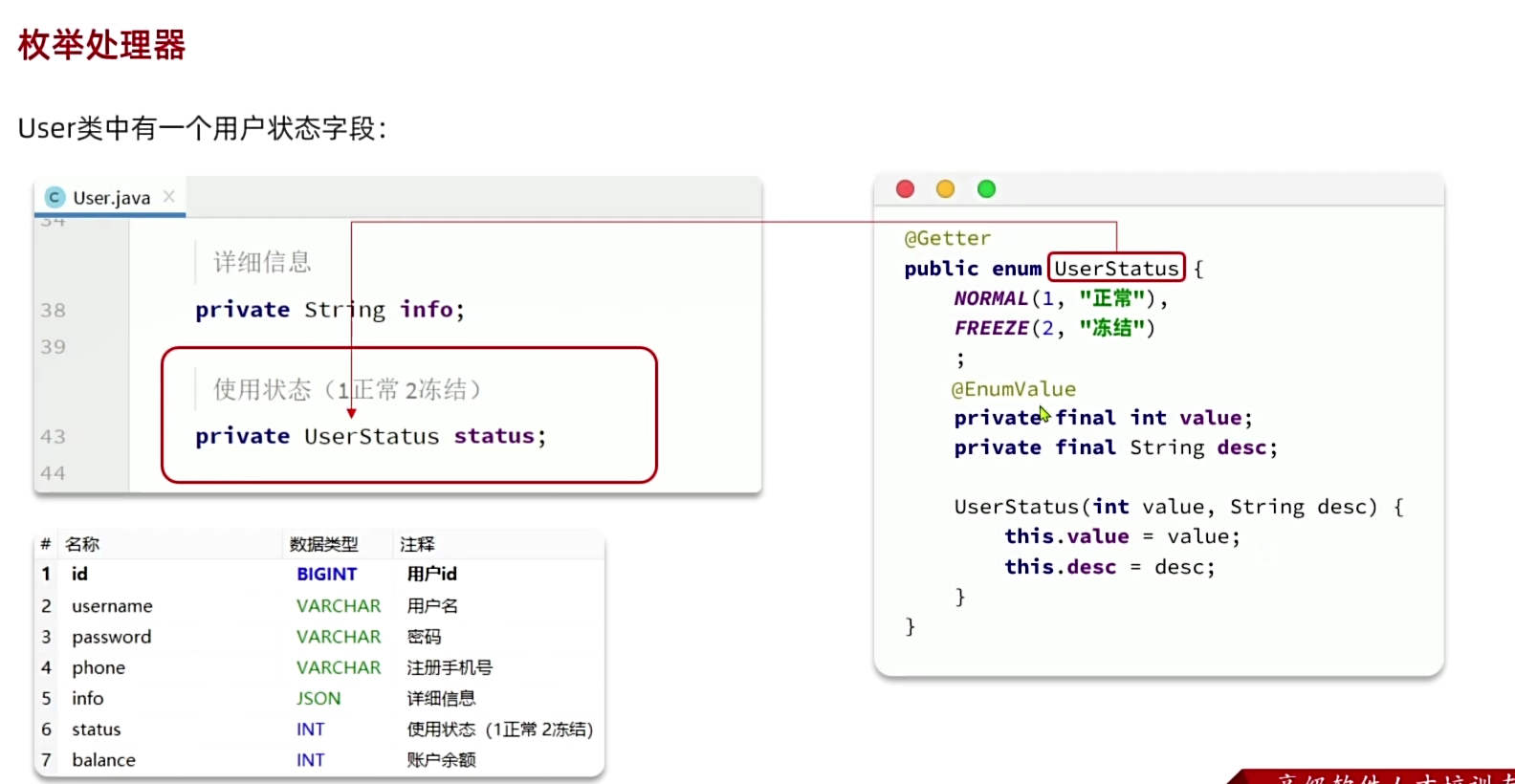
在application.yml中配置全局枚举处理器:
1 | mybatis-plus: |
1 |
|
优势
1、类型安全,避免无效值
枚举是强类型,方法参数或实体类字段使用枚举类型(如Status)时,无法传入无效的数字(如3),编译器会直接报错。而常量类无法限制,可能导致无效状态存入数据库(如user.setStatus(5))。
2、扩展性强,携带额外信息
枚举可存储更多信息(如描述、颜色、排序),并支持自定义方法,满足复杂需求。而常量类仅能存储键值对,扩展需新增静态方法。
JSON处理器(确实好用)

插件功能和分页插件
MyBatisPlus提供的内置拦截器有下面这些:
| 序号 | 拦截器 | 描述 |
|---|---|---|
| 1 | TenantLineInnerInterceptor | 多租户插件 |
| 2 | DynamicTableNameInnerInterceptor | 动态表名插件 |
| 3 | PaginationInnerInterceptor | 分页插件 |
| 4 | OptimisticLockerInnerInterceptor | 乐观锁插件 |
| 5 | IllegalSQLInnerInterceptor | SQL性能规范插件,检测并拦截垃圾SQL |
| 6 | BlockAttackInnerInterceptor | 防止全表更新和删除的插件 |
分页插件
首先,要在配置类中注册MyBatisPlus的核心插件,同时添加分页插件,添加其他插件要看官方文档:
1 |
|
接着,就可以使用分页的API了:
1 |
|
通用分页实体
需求:遵循下面的接口规范,编写一个UserController接口,实现User的分页查询
| 参数 | 说明 |
|---|---|
| 请求方式 | GET |
| 请求路径 | /users/page |
| 请求参数 | json<br>{<br> "pageNo": 1,<br> "pageSize": 5,<br> "sortBy": "balance",<br> "isAsc": false,<br> "name": "jack",<br> "status": 1<br>}<br> |
| 返回值 | 分页数据(示例):json<br>{<br> "total": 100,<br> "pages": 20,<br> "current": 1,<br> "size": 5,<br> "records": [<br> {"id": 1, "name": "jack", "balance": 1000, "status": 1},<br> // ... 其他记录<br> ]<br>}<br> |
| 特殊说明 | - 如果sortBy(排序字段)为空,默认按照updateTime(更新时间)降序排序- 如果sortBy不为空,则按照sortBy字段排序(isAsc控制升序/降序) |
1 |
|
然后再让其他的查询类去继承他就好了
返回结果
1 |
|
使用
1 |
|
封装通用方法,让业务层不会太臃肿
1 |
|
1 |
|
完成改造
1 |
|
高级的PO转VO
1 | public static <PO, VO> PageDTO<VO> of(Page<PO> p, Class<VO> clazz) { |
建议
单独把方法写到一个工具类里,解耦
Docker
介绍与安装
快速构建、运行、管理应用的工具
AlmaLinux安装链接[http://mirrors.nju.edu.cn/almalinux/10.0/isos/x86_64/]
卸载旧版
首先如果系统中已经存在旧的Docker,则先卸载:
1 | yum remove docker \ |
🔧 一、安装前准备
- 更新系统 确保系统包为最新状态:
1 | sudo dnf update -y |
- 安装依赖工具 安装管理 YUM 仓库的工具包:
1 | sudo dnf install -y yum-utils device-mapper-persistent-data lvm2 |
- yum-utils:提供共yum-config-manager 工具(关键)
- device-mapper-persistent-data&lvm2:Docker存储驱动依赖
二、添加 Docker 镜像仓库(国内推荐源)
- 替换为国内镜像仓库(解决官方源慢/404问题):
1 | # 阿里云源(首选) |
📌 注意:
- 避免直接使用download.docker.com(官方源在国内访问不稳定)
- 验证仓库是否添加成功::sudo dnf repolist
⚙️ 三、安装 Docker 引擎
安装核心组件:
1 | sudo dnf install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin |
- 包含Docker引警、CLl工具、容器运行时及多平台扩展
启动并设置开机自启:
1 | sudo systemctl enable --now docker |
验证服务状态:
1 | sudo systemctl status docker |
✅ 正常状态应为
active (running)
四、配置镜像加速与用户权限
1. 打开/创建daemon.json文件
使用nano编辑器(AlmaLinux预装),执行以下命令:
1 | sudo nano /etc/docker/daemon.json |
- 若文件不存在,
nano会自动创建新文件; - 若文件已存在,会打开现有内容(可覆盖或修改)。
2. 写入正确的配置内容
将以下JSON内容完整粘贴到nano编辑器中(注意格式正确性):
1 | { |
- 关键检查:
- 数组中的镜像地址用双引号包裹;
- 每个键值对后用逗号分隔(最后一个键值对无需逗号);
exec-opts中的字符串格式正确(native.cgroupdriver=systemd)。
3. 保存并退出nano
- 按
Ctrl + O(保存文件); - 按
Enter(确认文件名); - 按
Ctrl + X(退出编辑器)。
4. 重启Docker服务使配置生效
1 | sudo systemctl restart docker |
5. 验证配置是否成功
重启生效:
1 | sudo systemctl restart docker |
🔔 推荐源清单(选2-3个即可):
docker.m.daocloud.io(稳定首选)
docker.nju.edu.cn(南京大学源)
dockerproxy.com(社区维护)
- 允许非 root 用户操作 Docker:
1 | sudo usermod -aG docker $USER # 将当前用户加入 docker 组 |
⚠️ 仍需重新登录系统或重启终端使更改全局生效
✅ 五、验证安装
- 运行测试容器:
1 | docker run hello-world |
成功标志:输出HellofromDocker!及使用说明
- 检查版本信息:
1 | docker --version # 输出示例:Docker version 24.0.7, build 1110f01 |
部署MySQL
1. 下载 MySQL 官方镜像(推荐指定版本)
1 | Bash# 下载最新稳定版(当前为 MySQL 8.0) |
2. 创建并运行 MySQL 容器(生产环境推荐配置)
1 | docker run -d \ |
重要参数说明:
| 参数 | 说明 | 必需 |
|---|---|---|
-e MYSQL_ROOT_PASSWORD |
root用户密码 | ✅ |
-v mysql-data:/var/lib/mysql |
数据持久化卷 | ✅ |
-e MYSQL_DATABASE |
自动创建数据库 | 可选 |
-e MYSQL_USER |
自动创建非root用户 | 推荐 |
--restart=unless-stopped |
容器自动重启 | 生产推荐 |
3. 验证 MySQL 运行状态
1 | # 查看容器状态 |
4. 安全配置建议
- 永远不要使用默认密码:
1 | # 首次启动后修改root密码 |
- 创建专用应用用户(避免使用root):
1 | CREATE USER 'app_user'@'%' IDENTIFIED BY 'strong_app_password'; |
- 限制远程访问:
1 | # 启动时添加参数: |
5. 数据管理操作
备份数据库:
1 | docker exec mysql-server sh -c 'exec mysqldump --all-databases -uroot -p"$MYSQL_ROOT_PASSWORD"' > full-backup.sql |
恢复数据库:
1 | docker exec -i mysql-server sh -c 'exec mysql -uroot -p"$MYSQL_ROOT_PASSWORD"' < full-backup.sql |
查看数据卷位置:
1 | docker volume inspect mysql-data |
6. 常用管理命令
| 命令 | 说明 |
|---|---|
docker stop mysql-server |
停止容器 |
docker start mysql-server |
启动容器 |
docker restart mysql-server |
重启容器 |
docker rm -v mysql-server |
删除容器并移除数据卷 |
docker volume rm mysql-data |
手动删除数据卷 |
| docker ps -a |grep mysql-server | 验证容器状态 |
⚠️ 注意事项:
- 密码安全:避免在命令行中直接暴露密码,使用环境变量文件更安全:
1 | # 创建密码文件 |
- 版本选择:
- MySQL 8.0:新项目推荐(性能更好)
- MySQL 5.7:旧系统兼容
- 性能优化:添加内存限制
1 | --memory=2g --memory-swap=4g # 限制2GB内存+4GB交换 |
- 时区设置:
1 | -e TZ=Asia/Shanghai # 设置中国时区 |
唯一id
1 | [root@localhost ~]# docker run -d \ |
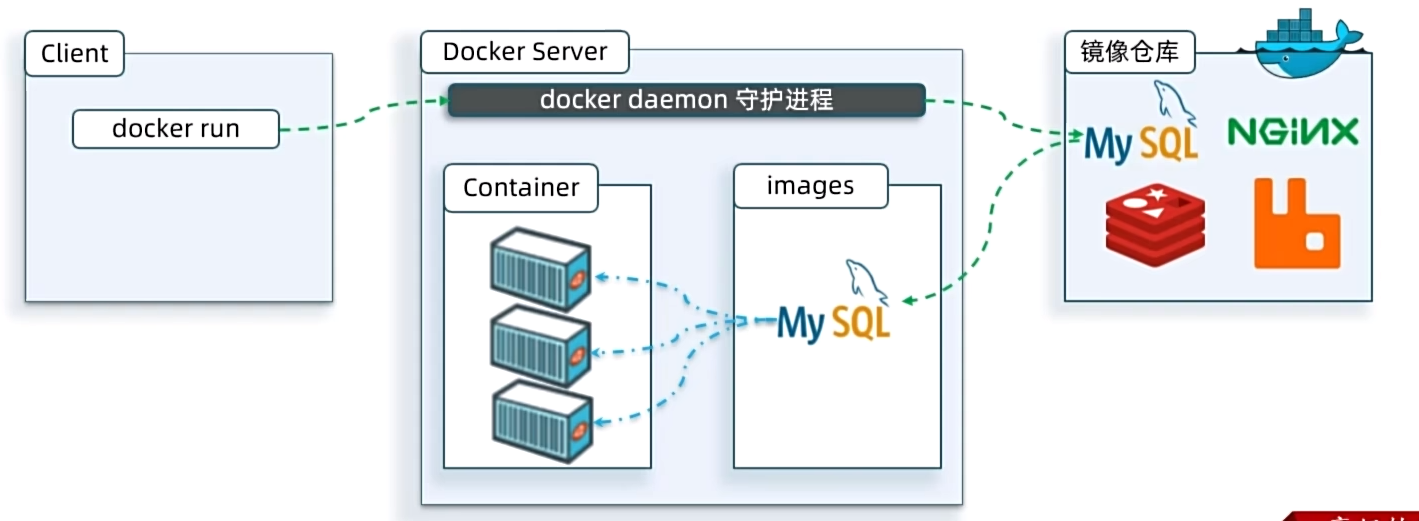
镜像与容器
当我们利用Docker安装应用时,Docker会自动搜索并下载应用镜像(image)。镜像不仅包含应用本身,还包含应用
运行所需要的环境、配置、系统函数库。Docker会在运行镜像时创建一个隔离环境,称为容器(container)。
镜像仓库:存储和管理镜像的平台,Docker官方维护了一个公共仓库:DockerHub。
- docker的镜像能够做到忽略操作系统的环境
- 多个环境使用同一个环境文件
命令解读
环境命令(run命令)
- docker run:创建并运行一个容器,-d是让容器在后台运行
- –name mysql:给容器起个名字,必须唯一
- -p 3306:3306:设置端口映射(前面为宿主机端口,后面是容器端口)(为什么要进行映射,因为docker的容器相当于一个小系统,但是不能对外,所以要通过映射来间接的访问容器)
- -e KEY=VALUE:是设置环境变量
- mysql:指定运行的镜像的名字
- 安装docker的机器叫做宿主机
- 可以在dockerhub里面搜索镜像
镜像命名规范
镜像名称一般分两部分组成:[repository]:[tag]。
- 其中repository就是镜像名
- tag是镜像的版本
- 在没有指定tag时,默认是latest,代表最新版本的镜像
常见命令
Docker最常见的命令就是操作镜像、容器的命令,详见官方文档:https://docs.docker.com/
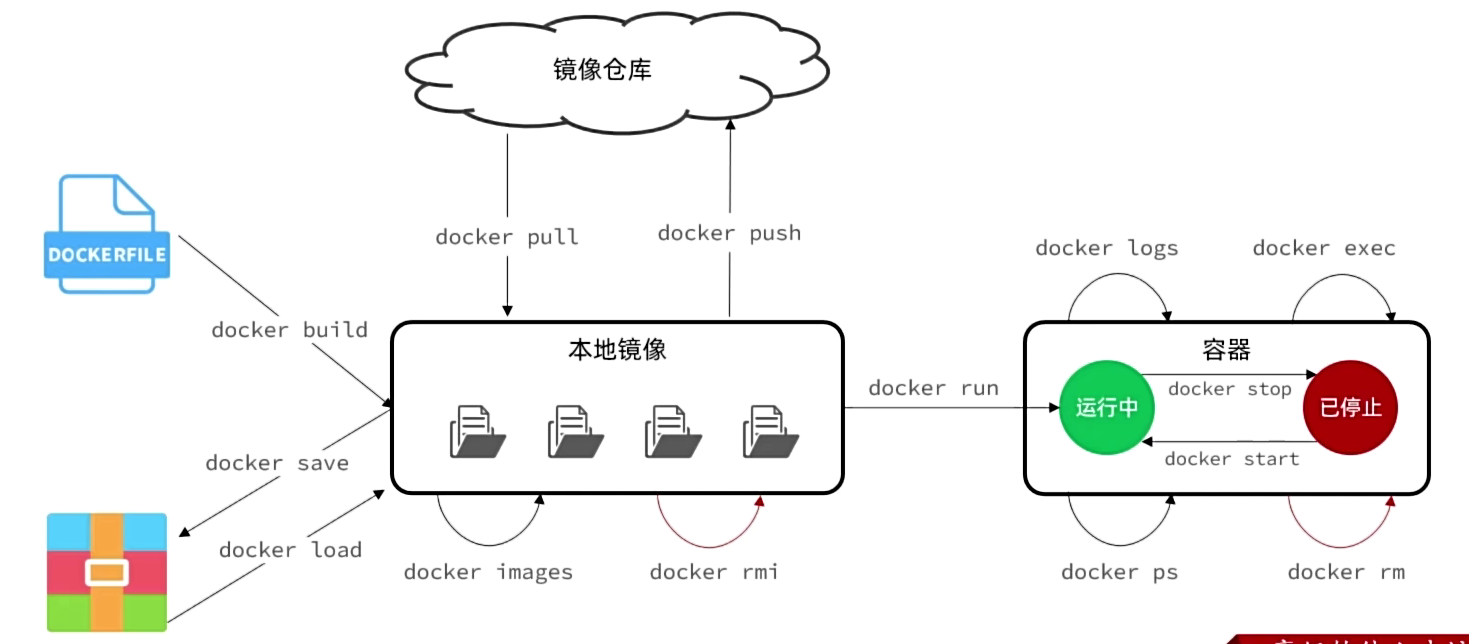
一、镜像相关(本地镜像的构建/获取/管理)
docker build:用Dockerfile(构建脚本)做本地镜像docker pull:从网上(镜像仓库)下镜像到本地docker push:把本地镜像传到网上(镜像仓库)docker images:看本地有哪些镜像(列表)docker rmi:删本地不用的镜像(需先删依赖它的容器)docker save:把本地镜像打成压缩包(方便传输)docker load:把压缩包中的镜像变回本地镜像(解压)
二、容器相关(容器的生命周期管理)
docker run:用本地镜像创建并启动容器(最常用)docker stop:停掉正在运行的容器docker start:启动已经停掉的容器docker ps:看正在运行的容器(加-a可看所有容器)docker logs:看容器运行时的日志(比如报错信息)docker exec:进入正在运行的容器,执行命令(比如改配置)docker rm:删不用的容器(需先停掉,或用-f强制删)
命令别名
1 | vi ~/.bashrc |
在里面可以为docker命令添加命令别名,加快命令输入
1 | # .bashrc |
配置完后,输入命令让其生效
1 | source ~/.bashrc |
数据卷挂载
案例1-利用Nginx容器部署静态资源
需求:
- 创建Nginx容器,修改nginx容器内的html目录下的index.html文件,查看变化
- 将静态资源部署到nginx的html目录
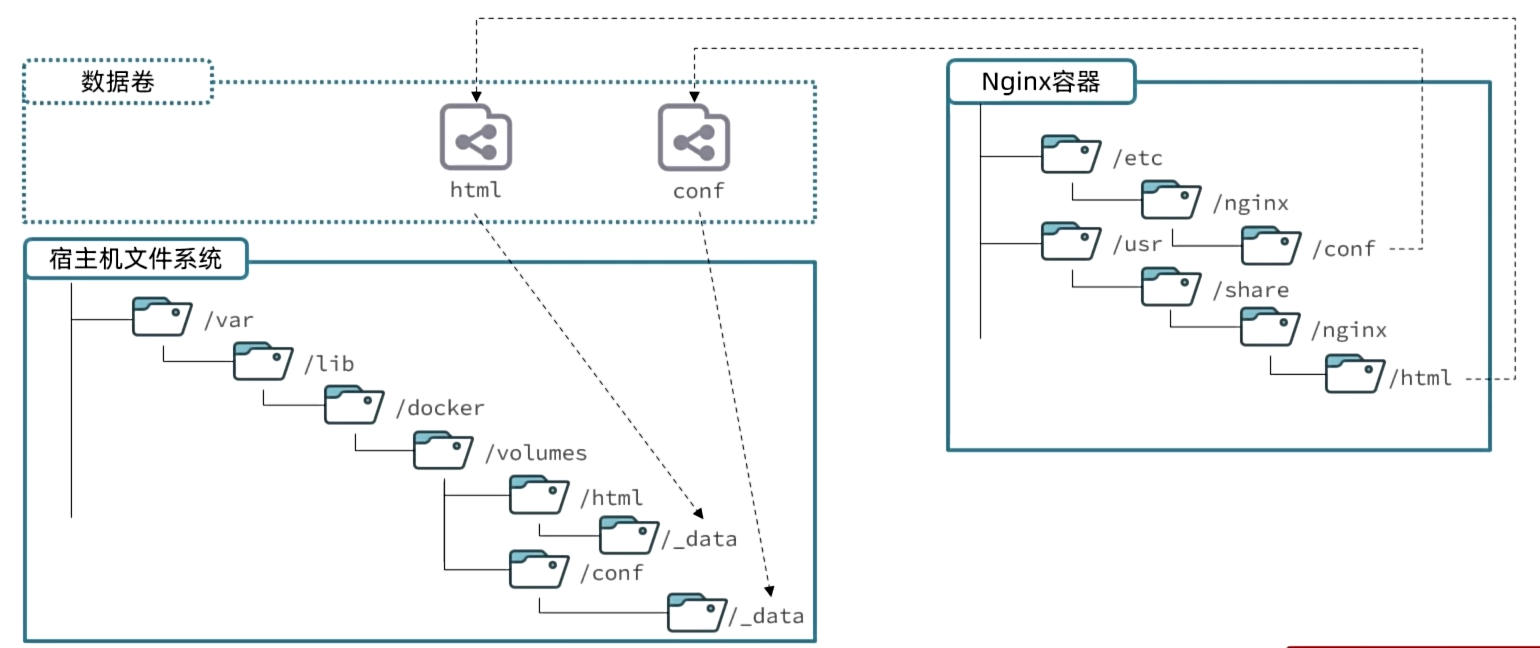
数据卷
数据卷(volume)是一个虚拟目录,是容器内目录与宿主机目录之间映射的桥梁。
- 在宿主机的数据卷目录下做修改,容器也会跟着修改
| 命令 | 说明 | 文档地址 |
|---|---|---|
docker volume create |
创建新的数据卷 | docker_volume_create |
docker volume ls |
列出所有本地数据卷 | docker_volume_ls |
docker volume rm |
删除指定数据卷 | docker_volume_rm |
docker volume inspect |
查看数据卷详细信息 | docker_volume_inspect |
docker volume prune |
清除未被使用的数据卷 | docker_volume_prune |
- 在执行dockerrun命令时,使用-v数据卷:容器内目录可以完成数据卷挂载
- 当创建容器时,如果挂载了数据卷且数据卷不存在,会自动创建数据卷
本地目录挂载
案例2-mysql容器的数据挂载
需求:
- 查看mysql容器,判断是否有数据卷挂载
- 基于宿主机目录实现MySQL数据目录、配置文件、初始化脚本的挂载(查阅官方镜像文档)
提示
- 在执行dockerrun命令时,使用-v本地目录:容器内目录可以完成本地目录挂载
- 本地目录必须以“7”或”.7”开头,如果直接以名称开头,会被识别为数据卷而非本地目录
- -v mysql:/var/lib/mysql会被识别为一个数据卷叫mysql
- v./mysql:/var/lib/mysql会被识别为当前目录下的mysql目录
Dockerfile语法
镜像就是包含了应用程序、程序运行的系统函数库、运行配置等文件的文件包。构建镜像的过程其实就是把上述文件打包的过程。
部署一个Java应用的步骤:
- 准备一个Linux服务器
- 安装JRE并配置环境变量
- 拷贝Jar包
- 运行Jar包
构建一个Java镜像的步骤:
- 准备一个Linux运行环境
- 安装JRE并配置环境变量
- 拷贝Jar包
- 编写运行脚本
镜像结构
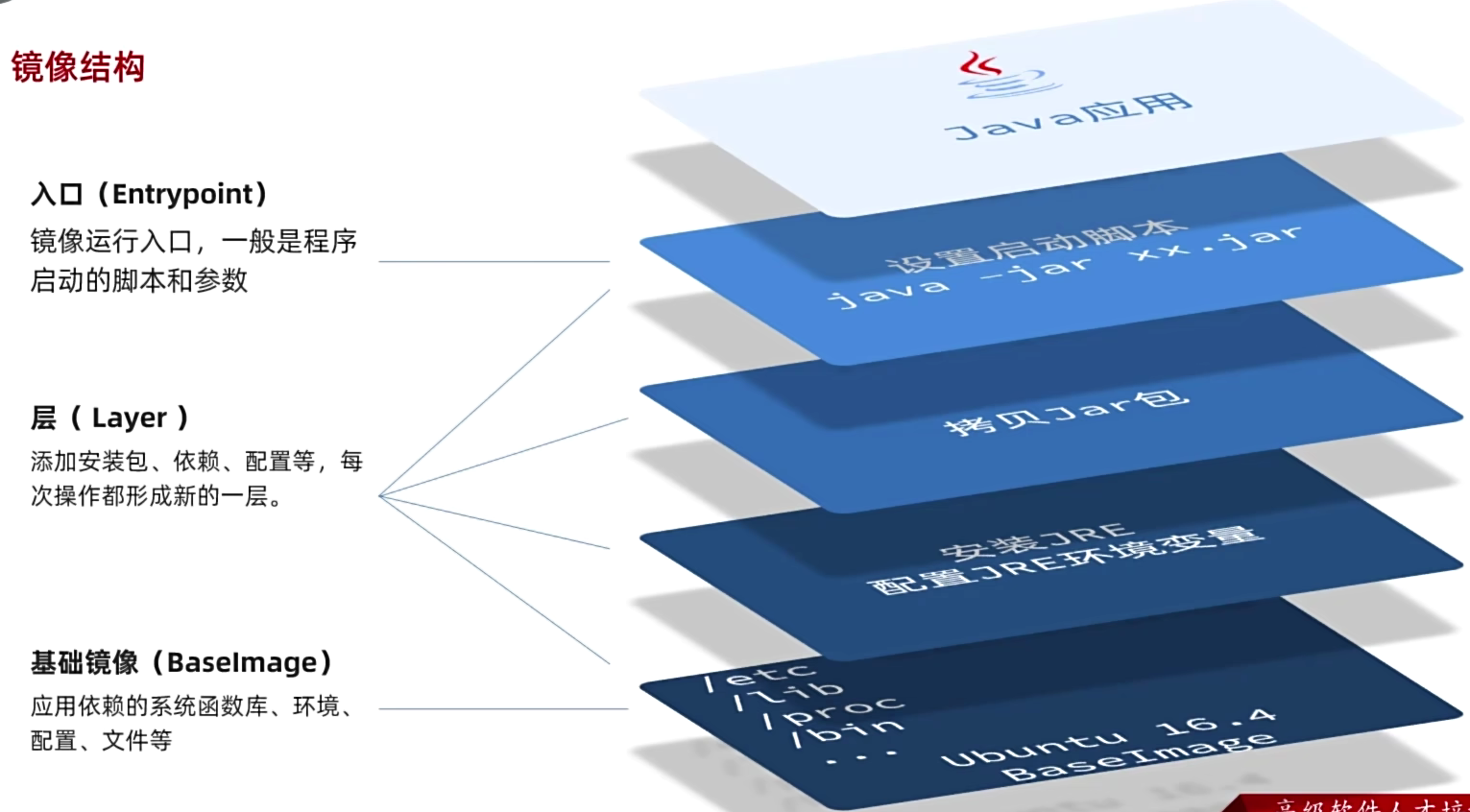
分层之后可以把你经常需要的镜像给保存下来,以方便以后使用
Dockerfile
Dockerfile就是一个文本文件,其中包含一个个的指令(Instruction),用指令来说明要执行什么操作来构建镜像。将来Docker可以根据Dockerfile帮我们构建镜像。常见指令如下:
| 指令 | 说明 | 示例 |
|---|---|---|
| FROM | 指定构建镜像的基础镜像(必须是第一个指令) | FROM centos:6(使用CentOS 6作为基础镜像) |
| ENV | 设置环境变量(可在后续指令中引用) | ENV JAVA_HOME /opt/jre11(定义JAVA_HOME变量,值为/opt/jre11) |
| COPY | 将本地文件/目录复制到镜像中的指定路径 | COPY ./jre11.tar.gz /tmp(复制当前目录的jre11.tar.gz到镜像的/tmp目录) |
| RUN | 执行Shell命令(用于安装软件、配置环境等) | RUN tar -zxvf /tmp/jre11.tar.gz -C /opt && export PATH=$JAVA_HOME/bin:$PATH(解压JRE并添加到PATH) |
| EXPOSE | 声明容器运行时监听的端口(仅文档作用) | EXPOSE 8080(告诉使用者容器会监听8080端口,需用-p映射到主机) |
| ENTRYPOINT | 定义容器启动时的默认命令(不可被docker run参数覆盖) |
ENTRYPOINT ["java", "-jar", "app.jar"](用exec格式启动Java应用,推荐) |
更新详细语法说明,请参考官网文档:https://docs.docker.com/engine/reference/builder
自定义镜像
我们可以基于Ubuntu基础镜像,利用Dockerfile描述镜像结构,也可以直接基于JDk为基础镜像,省略前面的步骤:
1 | #基础镜像 |
当编写好了Dockerfile,可以利用下面命令来构建镜像:
1 | docker build-t myImage:1.0 . |
- -t :是给镜像起名,格式依然是repository:tag的格式,不指定tag时,默认为latest
- · :是指定Dockerfile所在目录,如果就在当前目录,则指定为”.”
容器网络互连
默认情况下,所有容器都是以bridge方式连接到Docker的一个虚拟网桥上:
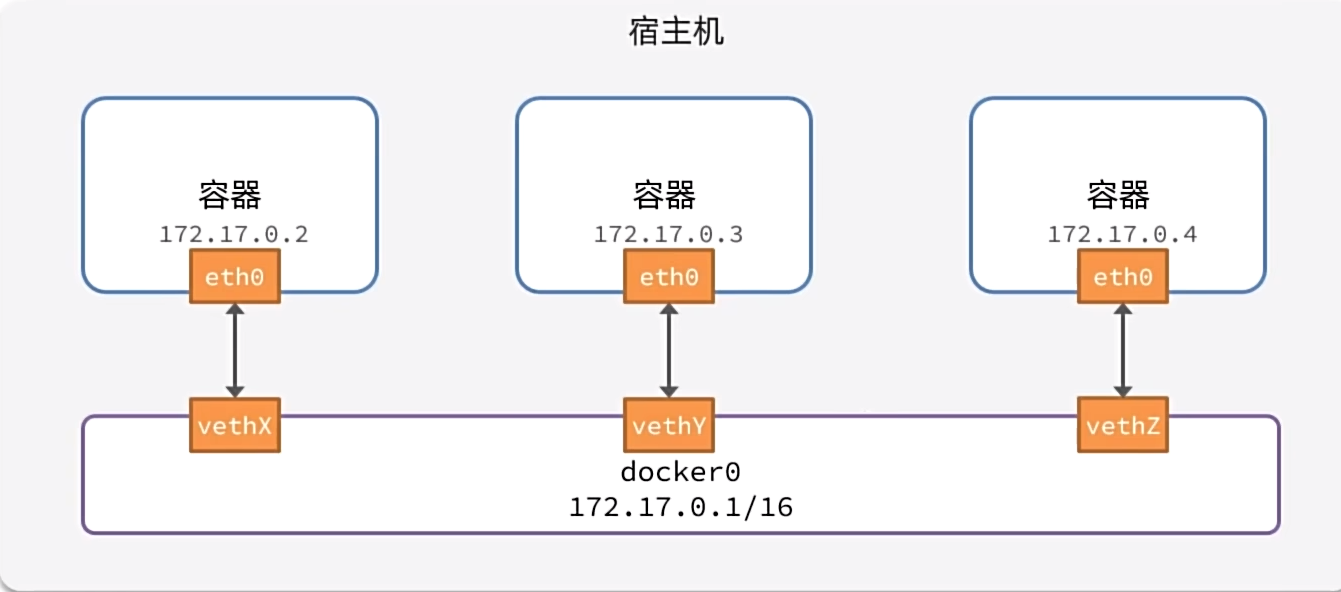
但是分配的网络地址会发生变化,这样会导致mysql与java程序的连接总是要更换
自定义网络
加入自定义网络的容器才可以通过容器名互相访问,Docker的网络操作命令如下:
| 命令 | 说明 | 文档地址 |
|---|---|---|
docker network create |
创建一个自定义网络 | docker_network_create |
docker network ls |
列出所有本地网络 | docker_network_ls |
docker network rm |
删除指定网络(需先断开关联容器) | docker_network_rm |
docker network prune |
清除所有未使用的网络(释放资源) | docker_network_prune |
docker network connect |
将指定容器连接到某个网络 | docker_network_connect |
docker network disconnect |
将指定容器从某个网络断开连接 | docker_network_disconnect |
docker network inspect |
查看某个网络的详细信息(如IP段、关联容器) | docker_network_inspect |
部署Java应用
放到自定义容器中
部署前端
- 视频展示的是本地卷挂载在新的nginx容器下
- 但是企业的做法是整体打包到新的nginx容器下
- 对于开发好的项目都要整体打包到自定义容器里面。而对于想hexo这种可能多次要进行上传新的博客内容的个人小项目是可以进行创建一个单独的nginx容器来通过本地卷挂载的方式来部署的
DockerCompose
DockerCompose通过一个单独的docker-compose.yml模板文件(YAML格式)来定义一组相关联的应用容器,帮助我们实现多个相互关联的Docker容器的快速部署。

docker run和docker-compose.yml的区别
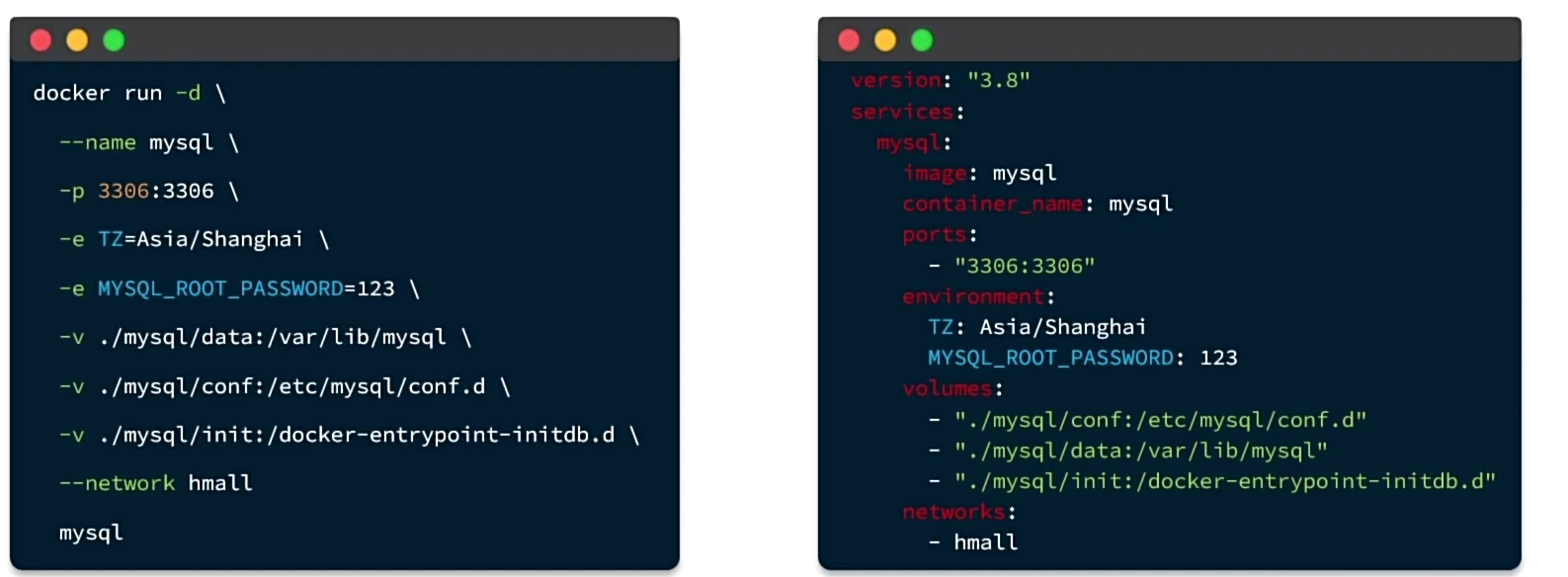
dockercompose的命令格式如下:
1 | docker compose [OPTIONS] [COMMAND] |
| 类型 | 参数或指令 | 说明 |
|---|---|---|
| Options(全局参数) | -f |
指定Docker Compose文件的路径和名称(如-f docker-compose.prod.yml) |
-p |
指定项目(Project)名称(如-p my-project,会作为容器/网络的前缀) |
|
| Commands(核心命令) | up |
创建并启动所有Service(服务)的容器(默认前台运行,-d后台运行) |
down |
停止并移除所有容器、网络(默认保留数据卷,--volumes可移除卷) |
|
ps |
列出Compose项目中所有服务的容器状态(包括未启动的) | |
logs |
查看指定服务的日志(如logs web,-f跟踪实时日志) |
|
stop |
停止指定服务的容器(如stop web) |
|
start |
启动指定服务的容器(如start web) |
|
restart |
重启指定服务的容器(如restart web) |
|
top |
查看指定服务容器中的运行进程(如top web) |
|
exec |
在指定服务的运行中容器中执行命令(如exec web bash,进入容器终端) |
微服务基础
启动小技巧
按下ALT + 8键打开services窗口,新增一个启动项:
在弹出窗口中鼠标向下滚动,找到Spring Boot:
点击后应该会在services中出现hmall的启动项:
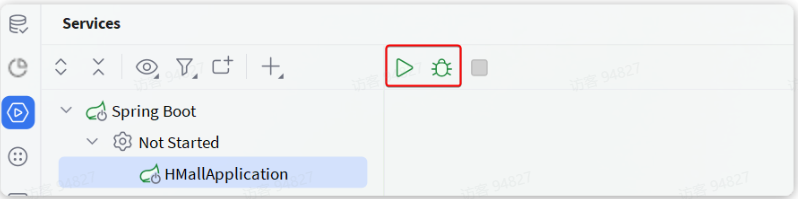
点击对应按钮,即可实现运行或DEBUG运行。
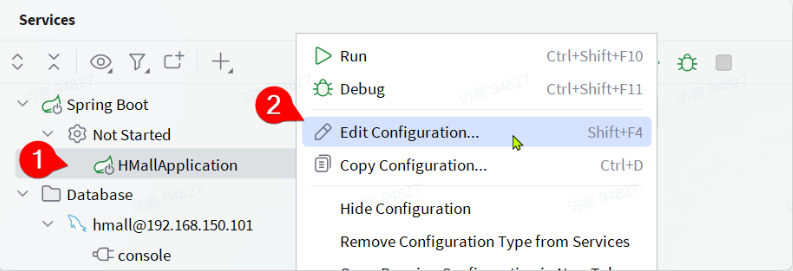
不过别着急!!
我们还需要对这个启动项做简单配置,在HMallApplication上点击鼠标右键,会弹出窗口,然后选择Edit Configuration:
在弹出窗口中配置SpringBoot的启动环境为local:
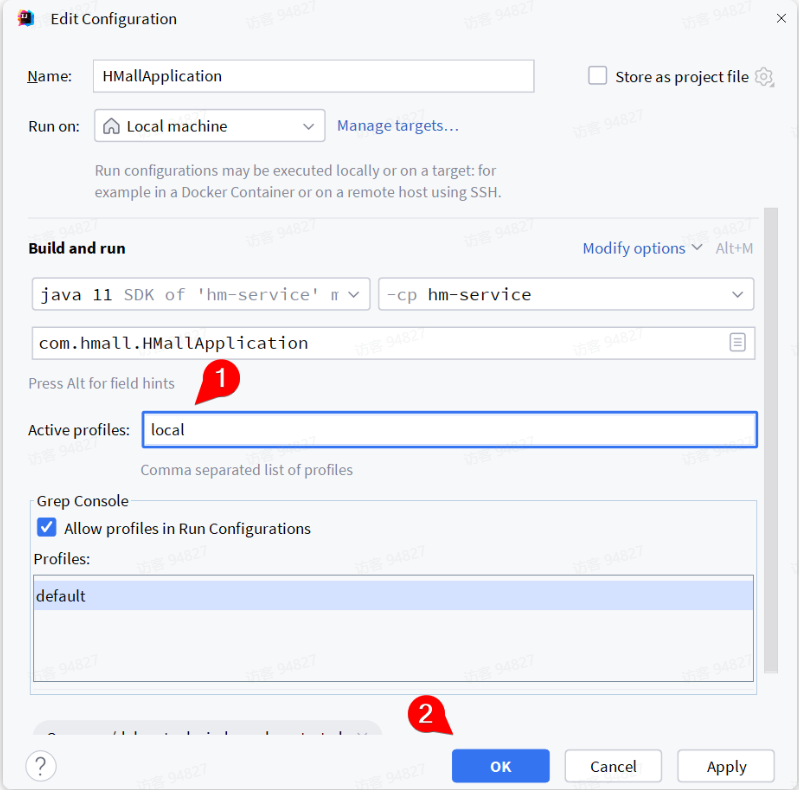
点击OK配置完成。接下来就可以运行了!
单体架构
**单体架构:**将业务的所有功能集中在一个项目中开发,打成一个包部署,
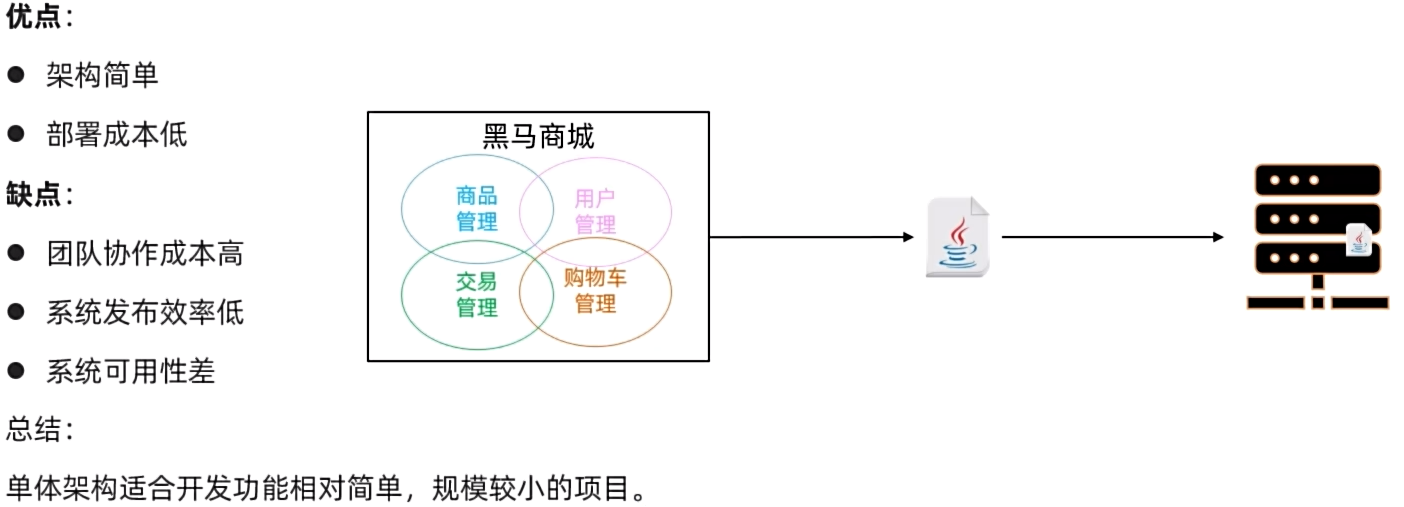
容易被多次调用的功能会因为高并发影响到其他功能
微服务架构
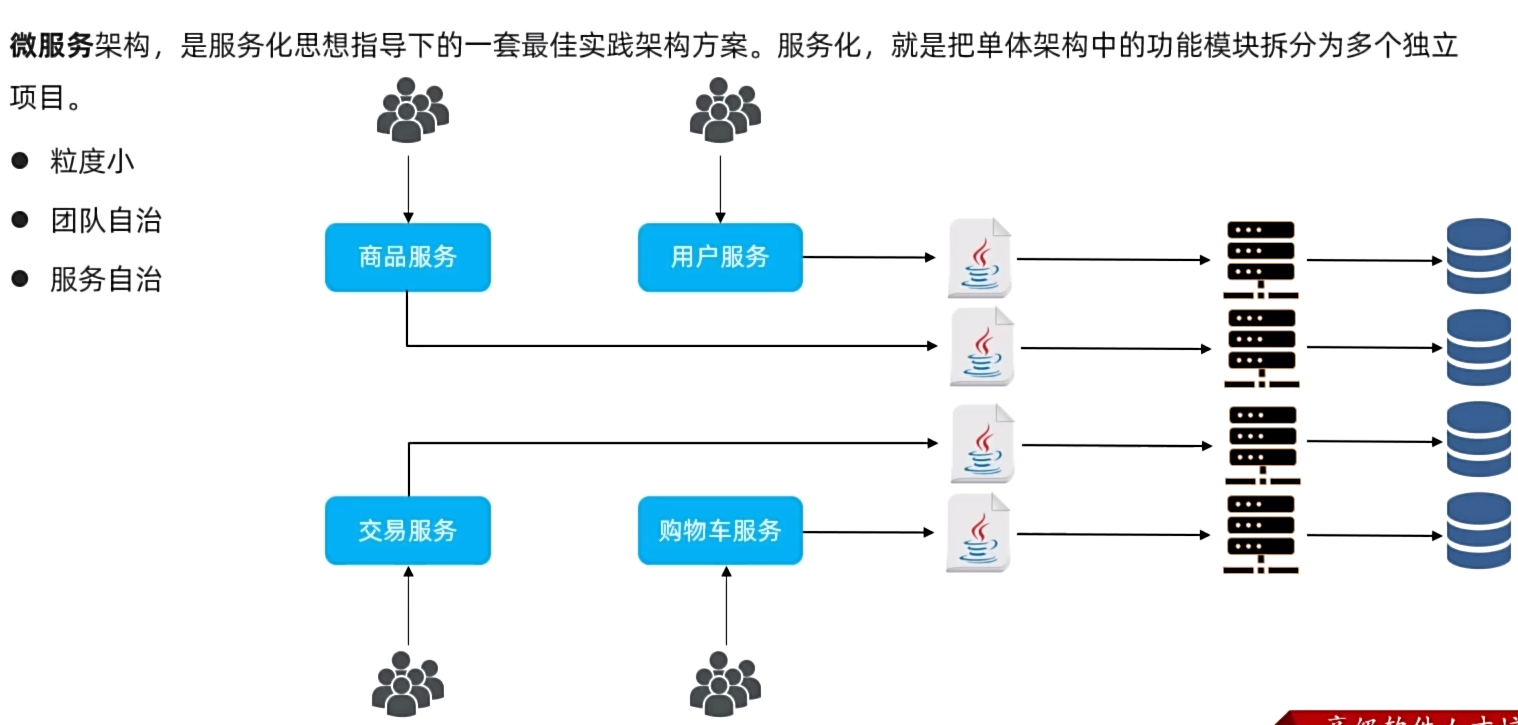
SpringCloud
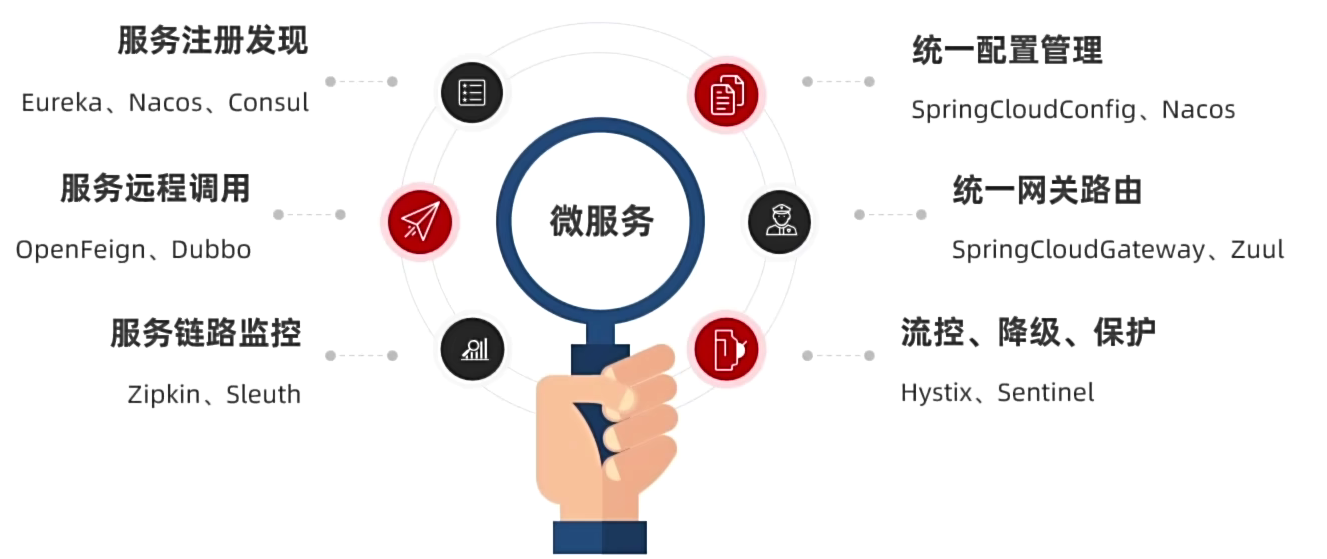
SpringCloud是目前国内使用最广泛的微服务框架。官网地址:https://spring.io/projects/spring-cloud。
SpringCloud集成了各种微服务功能组件,并基于SpringBoot实现了这些组件的自动装配,从而提供了良好的开箱即用体验:
 SpringCloud基于SpringBoot实现了微服务组件的自动装配,从而提供了良好的开箱即用体验。但对于SpringBoot的版本也有要求:
SpringCloud基于SpringBoot实现了微服务组件的自动装配,从而提供了良好的开箱即用体验。但对于SpringBoot的版本也有要求:
| Spring Cloud版本 | 别名 | 发布时间 | 支持Spring Boot版本 | 支持JDK版本 | 终止支持时间(EOL) | 推荐场景 |
|---|---|---|---|---|---|---|
| 2024.0.x | Nyholm | 2024-10 | 3.2.x, 3.3.x(从2024.0.1开始支持3.3.x) | 17/21+(3.3.x默认JDK 21) | 2026-04 | 最新稳定版,追求新特性(如虚拟线程、JDK 21支持) |
| 2023.0.x | Leyton | 2023-10 | 3.1.x, 3.2.x(从2023.0.3开始支持3.2.x) | 17+ | 2025-04 | 生产环境首选(LTS长期支持,稳定性高) |
| 2022.0.x | Kilburn | 2022-10 | 3.0.x | 17+ | 2024-04(已终止) | 旧项目维护,不推荐新启动项目 |
| 2021.0.x | Jubilee | 2021-10 | 2.6.x, 2.7.x(从2021.0.3开始支持2.7.x) | 8/11/17 | 2023-04(已终止) | 旧项目维护 |
| 2020.0.x | Ilford | 2020-10 | 2.4.x, 2.5.x(从2020.0.3开始支持2.5.x) | 8/11/17 | 2022-04(已终止) | 旧项目维护 |
| Hoxton(旧版本) | - | 2019-11 | 2.2.x, 2.3.x(从SR5开始支持2.3.x) | 8/11 | 2022-12(已终止) | legacy系统维护 |
| Greenwich(旧版本) | - | 2019-01 | 2.1.x | 8/11 | 2021-09(已终止) | legacy系统维护 |
| Finchley(旧版本) | - | 2018-06 | 2.0.x | 8 | 2020-06(已终止) | legacy系统维护 |
| Edgware(旧版本) | - | 2017-10 | 1.5.x | 7/8 | 2019-10(已终止) | legacy系统维护 |
| Dalston(旧版本) | - | 2017-05 | 1.5.x | 7/8 | 2019-05(已终止) | legacy系统维护 |
拆分模块
熟悉黑马商城
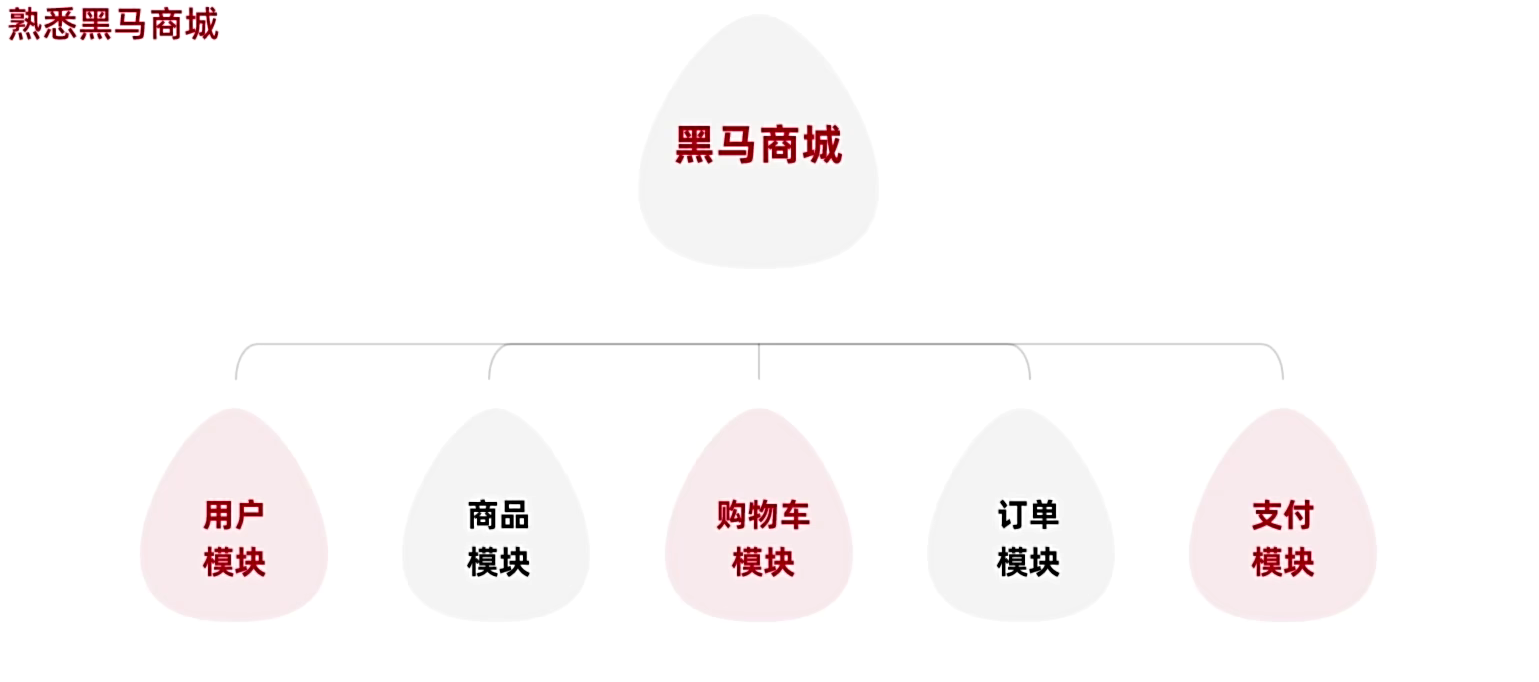
拆分原则
思考
什么时候拆分
- 创业型项目:先采用单体架构,快速开发,快速试错。随着规模扩大,逐渐拆分。
- 确定的大型项目:资金充足,目标明确,可以直接选择微服务架构,避免后续拆分的麻烦。
怎么拆分
从拆分目标来说,要做到:
- 高内聚:每个微服务的职责要尽量单一,包含的业务相互关联度高、完整度高。
- 低耦合:每个微服务的功能要相对独立,尽量减少对其它微服务的依赖。
从拆分方式来说,一般包含两种方式:
- 纵向拆分:按照业务模块来拆分
- 横向拆分:抽取公共服务,提高复用性
微服务项目结构说明
工程结构有两种:
- 独立Project
- 每一个功能一个项目,独立数据库,独立仓库,独立运维(大型项目,大型公司)
- Maven聚合
- 每一个项目通过Maven模块进行拆分就行(中小型企业)
拆分商品服务
需求:
- 将hm-service中与商品管理相关功能拆分到一个微服务module中,命名为item-service
- 将hm-service中与购物车有关的功能拆分到一个微服务module中,命名为cart-service
真实企业是一个服务一台mysql,但是现在为了方便,我们选择一台mysql装多个数据库
分离后,那报错就把缺少的类引进回来
拆分购物车服务
存在耦合,要修改
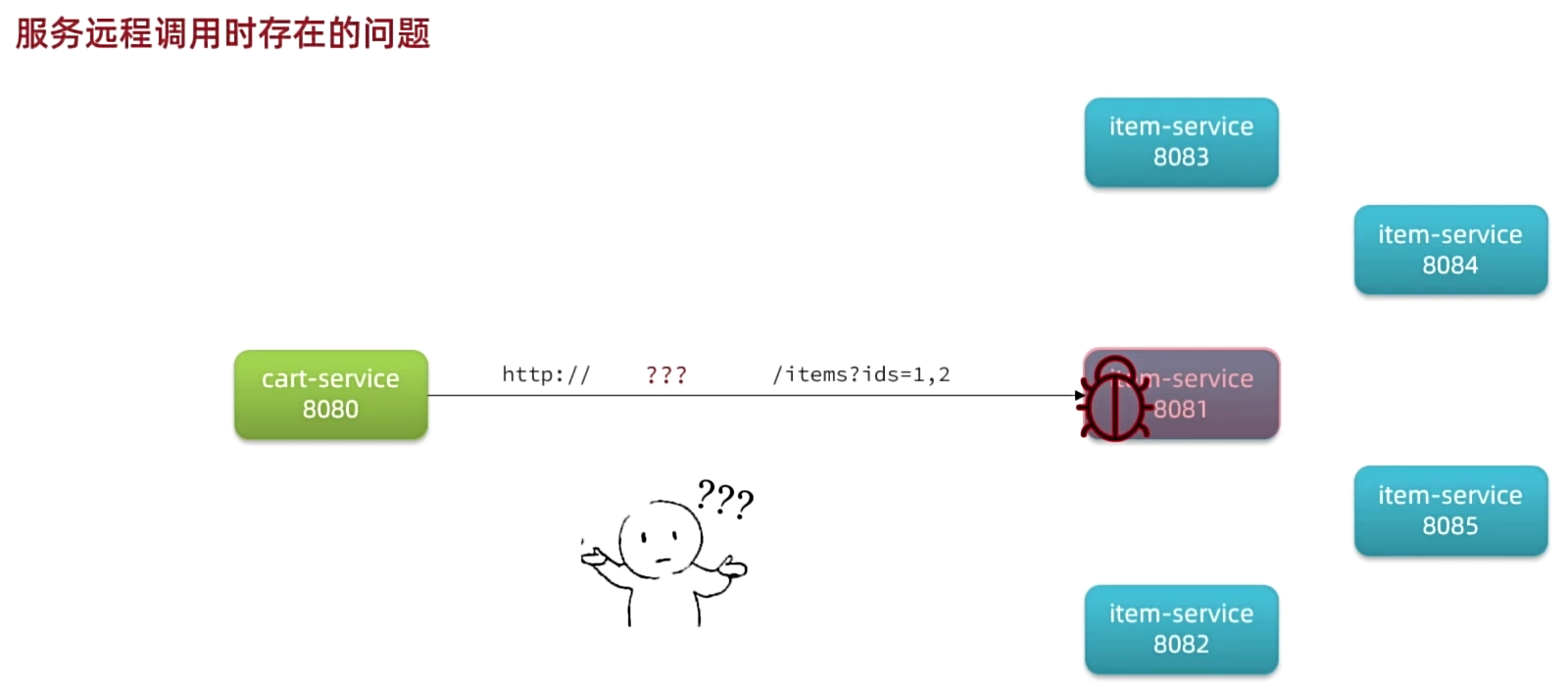
远程调用
解决耦合的方法–远程调用
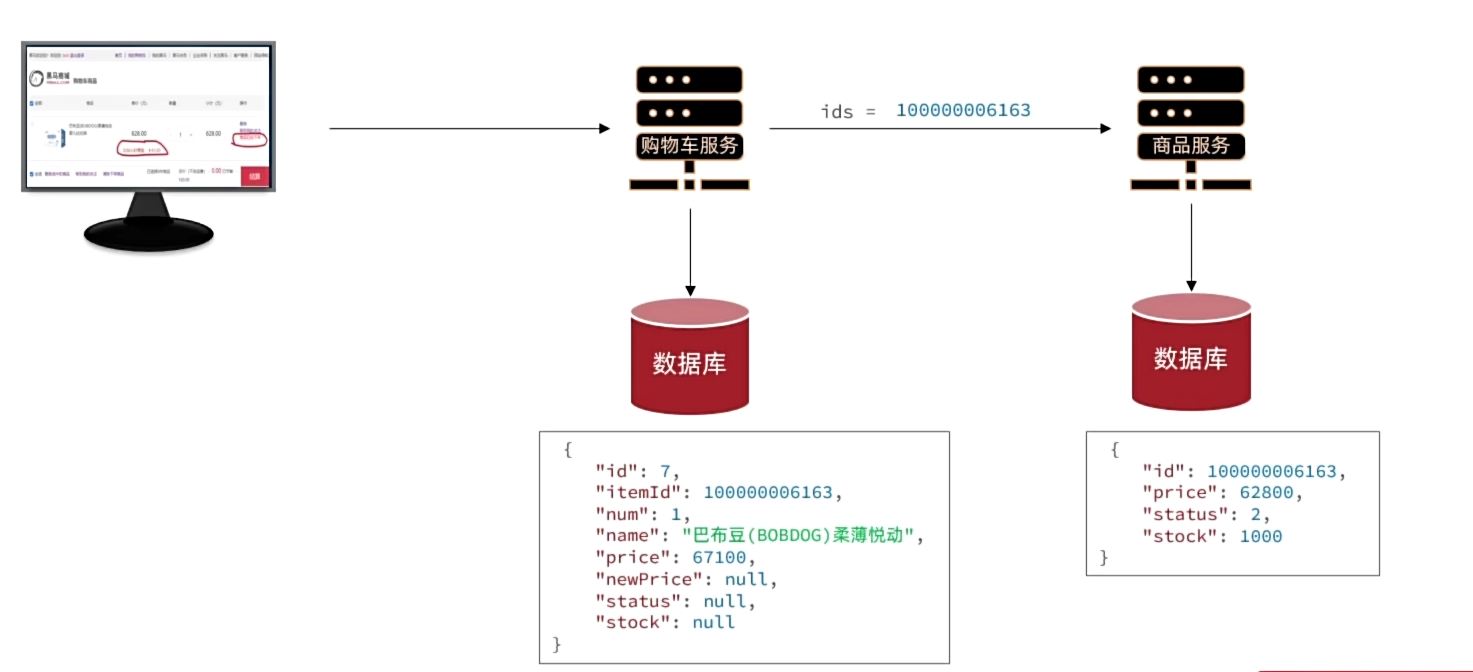
Spring给我们提供了一个RestTemplate工具,可以方便的实现Http请求的发送。使用步骤如下:
注入RestTemplate到Spring容器
1
2
3
4
public RestTemplate restTemplate(){
return new RestTemplate();
}发起远程调用
1
2
3
4
5
6
7public <T> ResponseEntity<T> exchange(
String url,//请求路径 "http://localhost:8081/items?id={id]"
HttpMethod method,//请求方式 HttpMethod.GET
HttpEntity<?> requestEntity,// 请求实体,可以为空
class<T> responseType,//返回值类型 User.class
Map<String,?> uriVariables//请求参数 Map.of("id","1")
)
代码:
1 |
|
1 |
|
注意
- RestTemplate不需要掌握,只要理解就行
- 有更好的技术
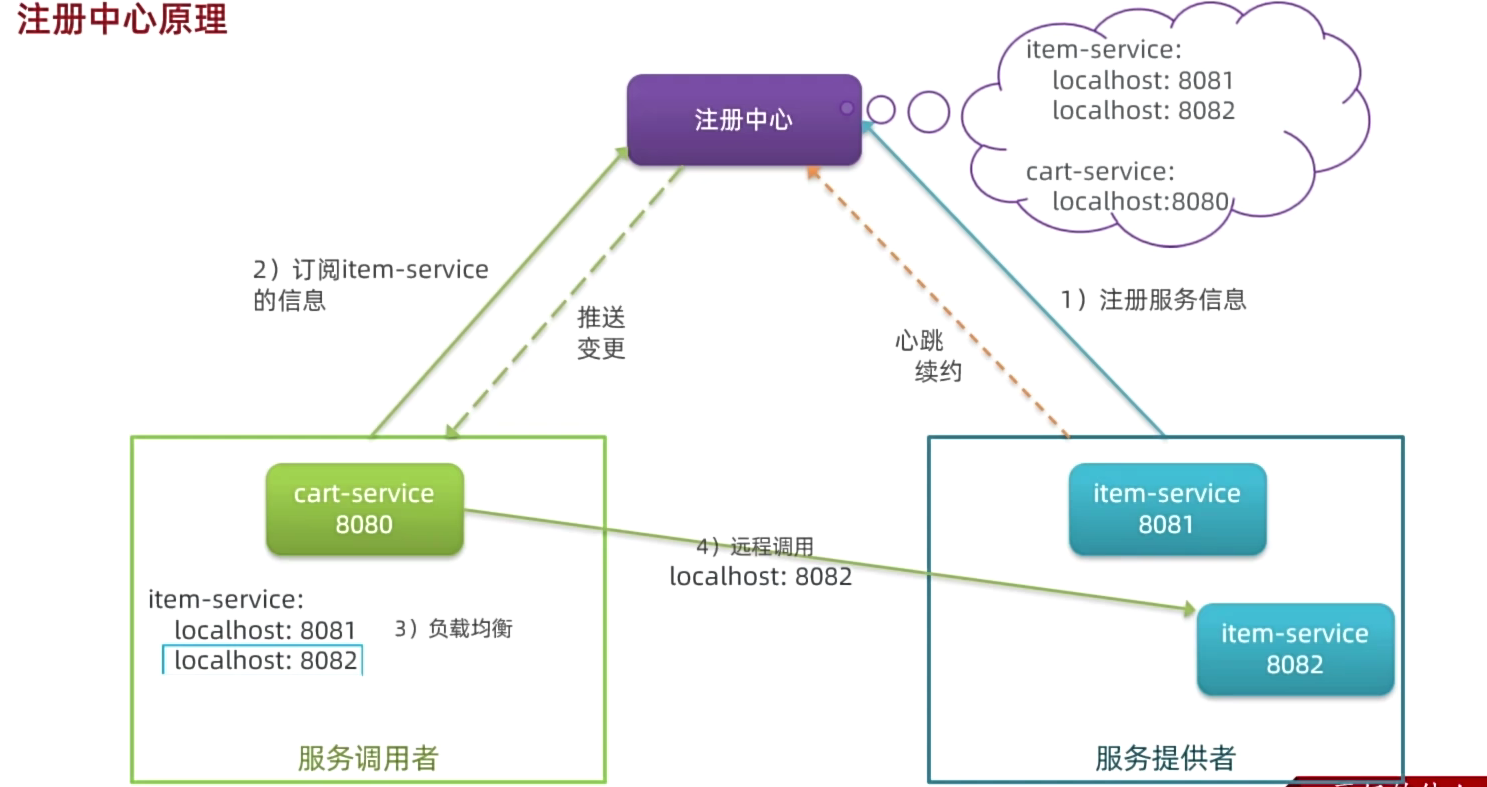
服务治理
注册中心原理
随机,轮询,区域内轮询,权重
服务治理中的三个角色分别是什么?
- 服务提供者:暴露服务接口,供其它服务调用
- 服务消费者:调用其它服务提供的接口
- 注册中心:记录并监控微服务各实例状态,推送服务变更信息
消费者如何知道提供者的地址?
- 服务提供者会在启动时注册自己信息到注册中心,消费者可以从注册中心订阅和拉取服务信息
消费者如何得知服务状态变更?
- 服务提供者通过心跳机制向注册中心报告自己的健康状态,当心跳异常时注册中心会将异常服务剔除,并通知订阅了该服务的消费者
当提供者有多个实例时,消费者该选择哪一个?
- 消费者可以通过负载均衡算法,从多个实例中选择一个
Nacos注册中心
目前开源的注册中心框架有很多,国内比较常见的有:
- Eureka:Netflix公司出品,目前被集成在SpringCloud当中,一般用于Java应用
- Nacos:Alibaba公司出品,目前被集成在SpringCloudAlibaba中,一般用于Java应用
- Consul:HashiCorp公司出品,目前集成在SpringCloud中,不限制微服务语言
Nacos是目前国内企业中占比最多的注册中心组件。它是阿里巴巴的产品,目前已经加入SpringCloudAlibaba中。

http://192.168.2.129:8848/nacos/
在 Nacos 2.2.0+ 版本中,除了 NACOS_AUTH_TOKEN 外,还需要设置两个额外的安全参数:
- NACOS_AUTH_IDENTITY_KEY - 身份验证密钥的名称
- NACOS_AUTH_IDENTITY_VALUE - 身份验证密钥的值
这是 Nacos 增强安全机制的一部分,三者必须同时配置才能正常启动。
如果不想配置安全参数,可以回退到旧版 Nacos(2.1.x)
服务注册
服务注册步骤如下:
引入nacos discovery依赖:
1
2
3
4
5<!--nacos服务注册发现-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>配置Nacos地址
1
2
3
4
5
6spring:
application:
name: item-service#服务名称
cloud:
nacos:
server-addr: 虚拟机IP地址:8848 #nacos地址
服务发现
消费者需要连接nacos以拉取和订阅服务,因此服务发现的前两步与服务注册是一样,后面再加上服务调用即可:
1 | private final DiscoveryClient discoveryClient; |
OpenFeign
认识
OpenFeign是一个声明式的http客户端,是SpringCloud在Eureka公司开源的Feign基础上改造而来。官方地址:
https://github.com/OpenFeign/feign
其作用就是基于SpringMVC的常见注解,帮我们优雅的实现http请求的发送。

OpenFeign 已集成 Spring Cloud 自动配置,实现服务调用非常简单:
① 引入依赖(含负载均衡)
需要引入 OpenFeign starter 和 Spring Cloud LoadBalancer(负载均衡组件):
1 | <!-- OpenFeign 核心依赖 --> |
② 启用 OpenFeign 功能
在 Spring Boot 启动类上添加 @EnableFeignClients 注解,开启 OpenFeign 支持:
1 | // 启用 OpenFeign 客户端 |
OpenFeign已集成Spring Cloud自动配置,实现远程服务调用非常简单,核心步骤如下:
③ 编写FeignClient(定义远程服务接口)
1 | // 指定目标服务名称(需与注册中心中的服务名一致) |
④ 使用FeignClient(发起远程调用)
1 | // 在业务类中注入FeignClient代理对象(Spring自动生成) |
OpenFeign与WebClient
- 核心业务服务间调用 - 首选 OpenFeign
- 高并发/异步场景 - 首选 WebClient
- 普通项目:OpenFeign(快速开发)
- 云原生/高并发:WebClient(面向未来)
连接池
每次访问都需要去创建一个新的请求,所以使用连接池优化!!!
OpenFeign对Http请求做了优雅的伪装,不过其底层发起http请求,依赖于其它的框架。这些框架可以自己选择,包括以下三种:
- HttpURLConnection:默认实现,不支持连接池
- Apache Httpclient:支持连接池
- OKHttp:支持连接池
具体源码可以参考FeignBlockingLoadBalancerClient类中的delegate成员变量。
| 微服务通信 | ✅ OkHttp | 高并发下性能优势明显,Feign/Spring Cloud 生态集成简单 |
|---|---|---|
| 企业级复杂应用 | ✅ HttpClient | 需 OAuth 认证、自定义重试策略等高级功能时更灵活 |
| Android 开发 | ✅ OkHttp | 官方推荐,深度优化移动网络(如弱网适应),体积小 |
| 传统 Java 项目 | ️ 两者均可 | HttpClient 无需额外依赖,OkHttp 需引入但性能更优 |
① 引入依赖
1 | <!--ok-http--> |
② 开启连接池功能
1 | feign: |
最佳实践
如果是每一个功能一个单独的文件夹和仓库的话,就用下面的模式
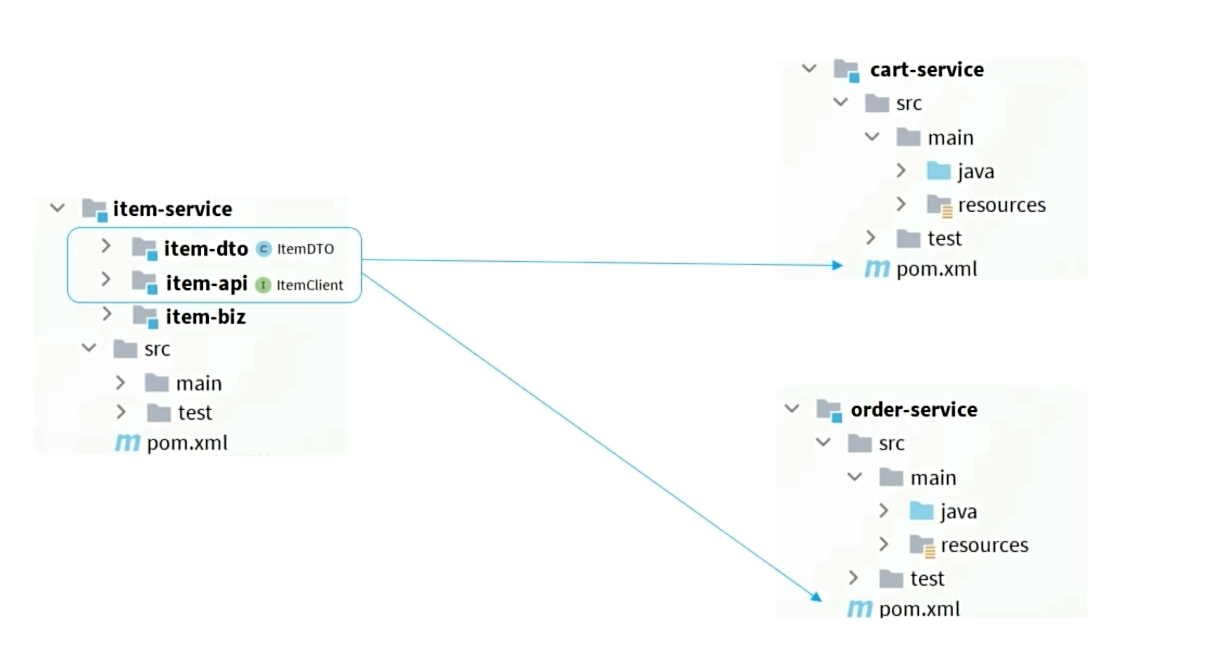
如果是使用Maven依赖的模式就使用下面的模式

当定义的FeignClient不在SpringBootApplication的扫描包范围时,这些FeignClient无法使用。有两种方式解决:
方式一:指定FeignClient所在包
1 |
方式二:指定FeignClient字节码
1 |
日志
OpenFeign只会在FeignClient所在包的日志级别为DEBUG时,才会输出日志。而且其日志级别有4级:
- NONE:不记录任何日志信息,这是默认值。
- BASIC:仅记录请求的方法,URL以及响应状态码和执行时间
- HEADERS:在BASIC的基础上,额外记录了请求和响应的头信息
- FULL:记录所有请求和响应的明细,包括头信息、请求体、元数据。
由于Feign默认的日志级别就是NONE,所以默认我们看不到请求日志。
要自定义日志级别需要声明一个类型为Logger.Level的Bean,在其中定义日志级别:
1 | package com.hmall.api.config; |
但此时这个Bean并未生效,要想配置某个FeignClient的日志,可以在@FeignClient注解中声明:
1 |
如果想要全局配置,让所有FeignClient都按照这个日志配置,则需要在@EnableFeignClients注解中声明:
1 |
调试时候,再使用,日常运行不要使用,会变慢
进一步拆分
拆分用户服务
拆分交易服务
拆分支付服务
网关
网关
网关:就是网络的关口,负责请求的路由、转发、身份校验
网关相当于看门大爷
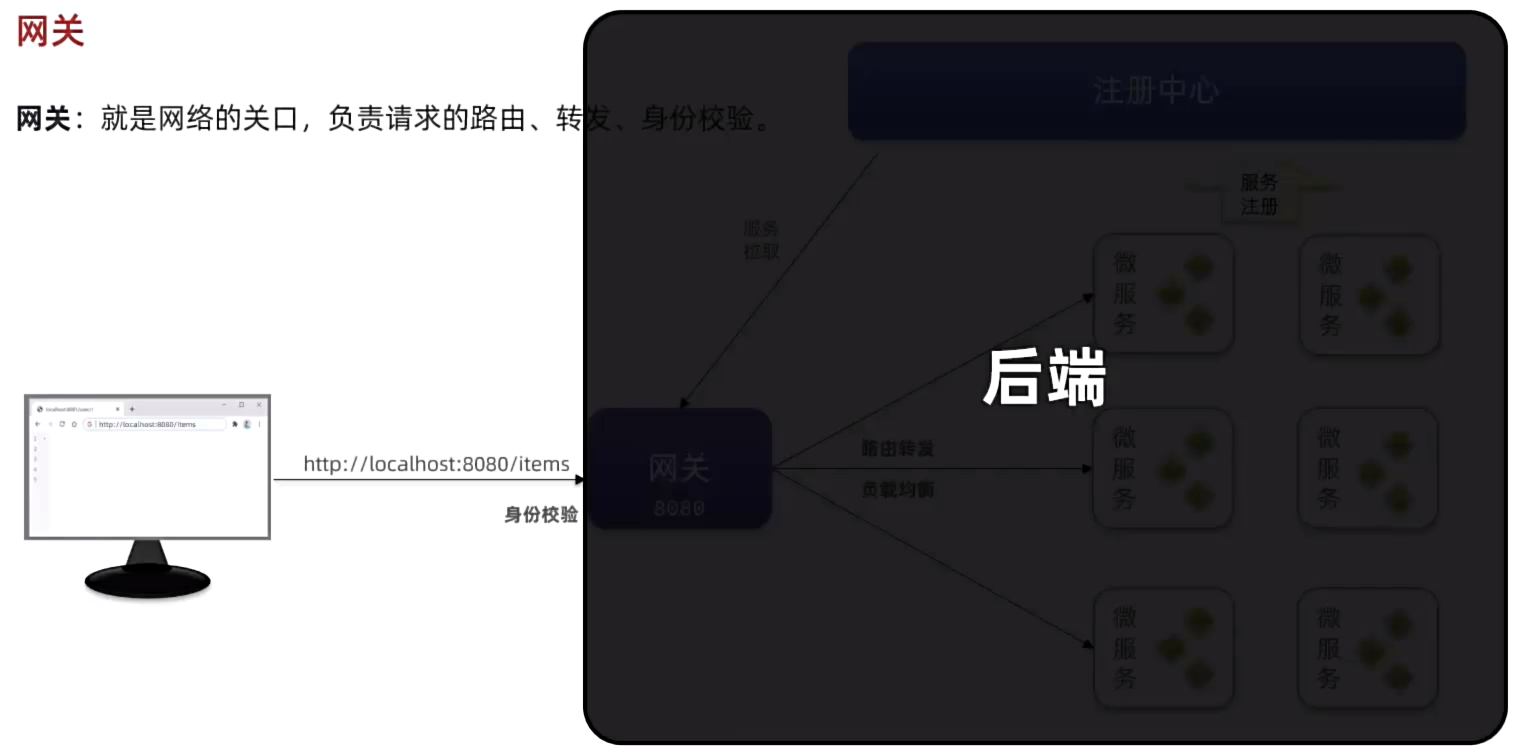
在SpringCloud中网关的实现包括两种:
Spring Cloud Gateway
- Spring官方出品
- 基于WebFlux响应式编程
- 无需调优即可获得优异性能
Netfilx Zuul
- Netflix出品
- 基于Servlet的阻塞式编程
- 需要调优才能获得与SpringCLoudGateway类似的性能
学习Spring Cloud Gateway就行
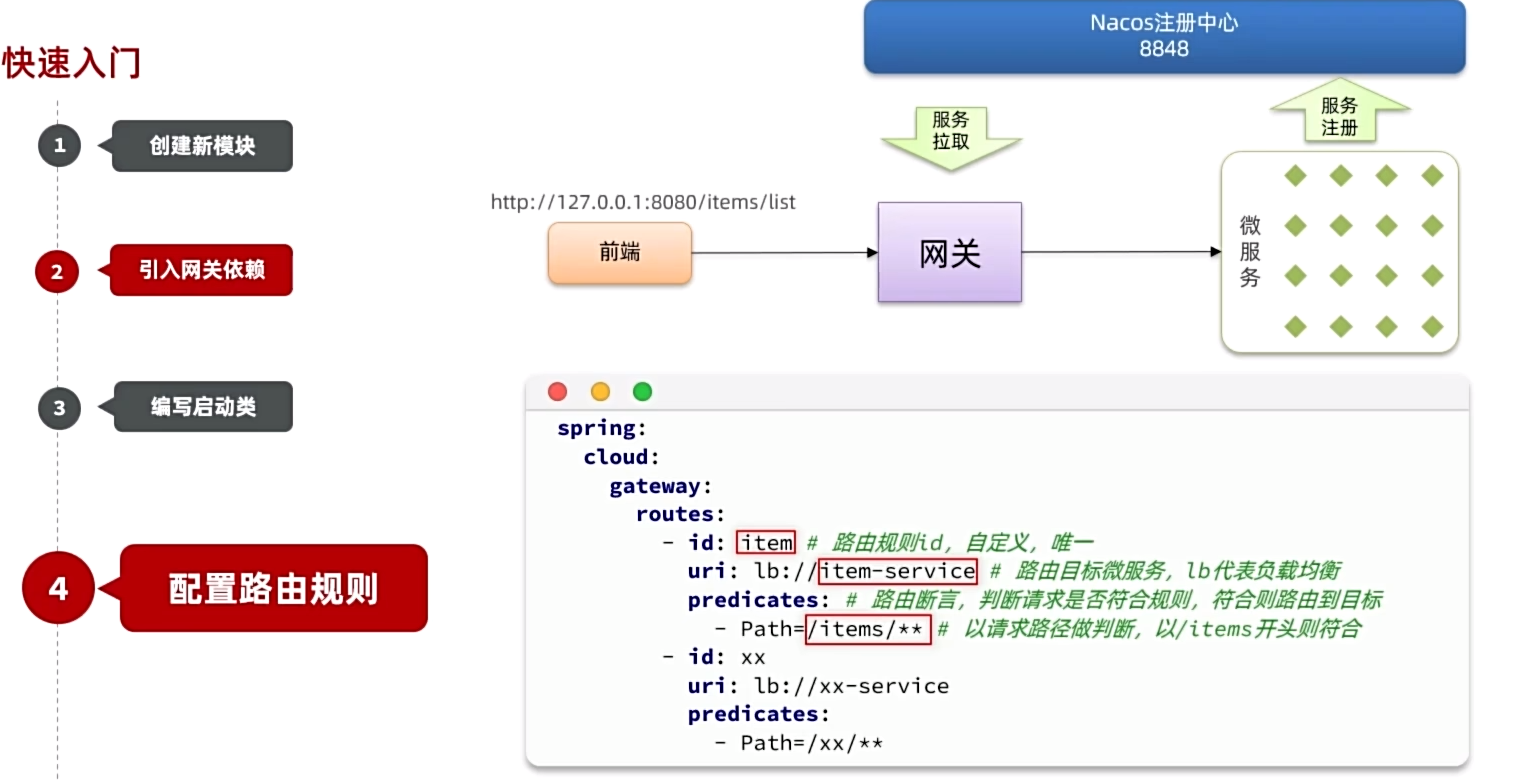
路由属性
网关路由对应的Java类型是RouteDefinition,其中常见的属性有:
- id:路由唯一标示
- uri:路由目标地址
- predicates:路由断言,判断请求是否符合当前路由。
- filters:路由过滤器,对请求或响应做特殊处理
路由断言
Spring提供了12种基本的RoutePredicateFactory实现:
| 名称 | 说明 | 示例 |
|---|---|---|
| After | 是某个时间点后的请求 | - After=2037-01-20T17:42:47.789-07:00[America/Denver] |
| Before | 是某个时间点之前的请求 | - Before=2031-04-13T15:14:47.433+08:00[Asia/Shanghai] |
| Between | 是某两个时间点之前的请求 | - Between=2037-01-20T17:42:47.789-07:00[America/Denver], 2037-01-21T17:42:47.789-07:00[America/Denver] |
| Cookie | 请求必须包含某些cookie | - Cookie=chocolate, ch.p |
| Header | 请求必须包含某些header | - Header=X-Request-Id, \d+ |
| Host | 请求必须是访问某个host(域名) | - Host=*.somehost.org, *.anotherhost.org |
| Method | 请求方式必须是指定方式 | - Method=GET,POST |
| Path | 请求路径必须符合指定规则 | - Path=/red/{segment}, /blue/** |
| Query | 请求参数必须包含指定参数 | - Query=name,Jack或者- Query=name |
| RemoteAddr | 请求者的ip必须是指定范围 | - RemoteAddr=192.168.1.1/24 |
| Weight | 权重处理 | - Weight=group1, 2 |
| XForwarded Remote Addr | 基于请求的来源IP做判断 | - XForwardedRemoteAddr=192.168.1.1/24 |
具体用法可以参考官网和AI
路由过滤器
网关中提供了33种路由过滤器,每种过滤器都有独特的作用。
| 名称 | 说明 | 示例 |
|---|---|---|
| AddRequestHeader | 给当前请求添加一个请求头 | AddrequestHeader=headerName,headerValue |
| RemoveRequestHeader | 移除请求中的一个请求头 | RemoveRequestHeader=headerName |
| AddResponseHeader | 给响应结果中添加一个响应头 | AddResponseHeader=headerName,headerValue |
| RemoveResponseHeader | 从响应结果中移除一个响应头 | RemoveResponseHeader=headerName |
| RewritePath | 请求路径重写 | RewritePath=/red/?( |
| StripPrefix | 去除请求路径中的N段前缀 | StripPrefix=1,则路径/a/b转发时只保留/b |
| …… |
网关登录校验
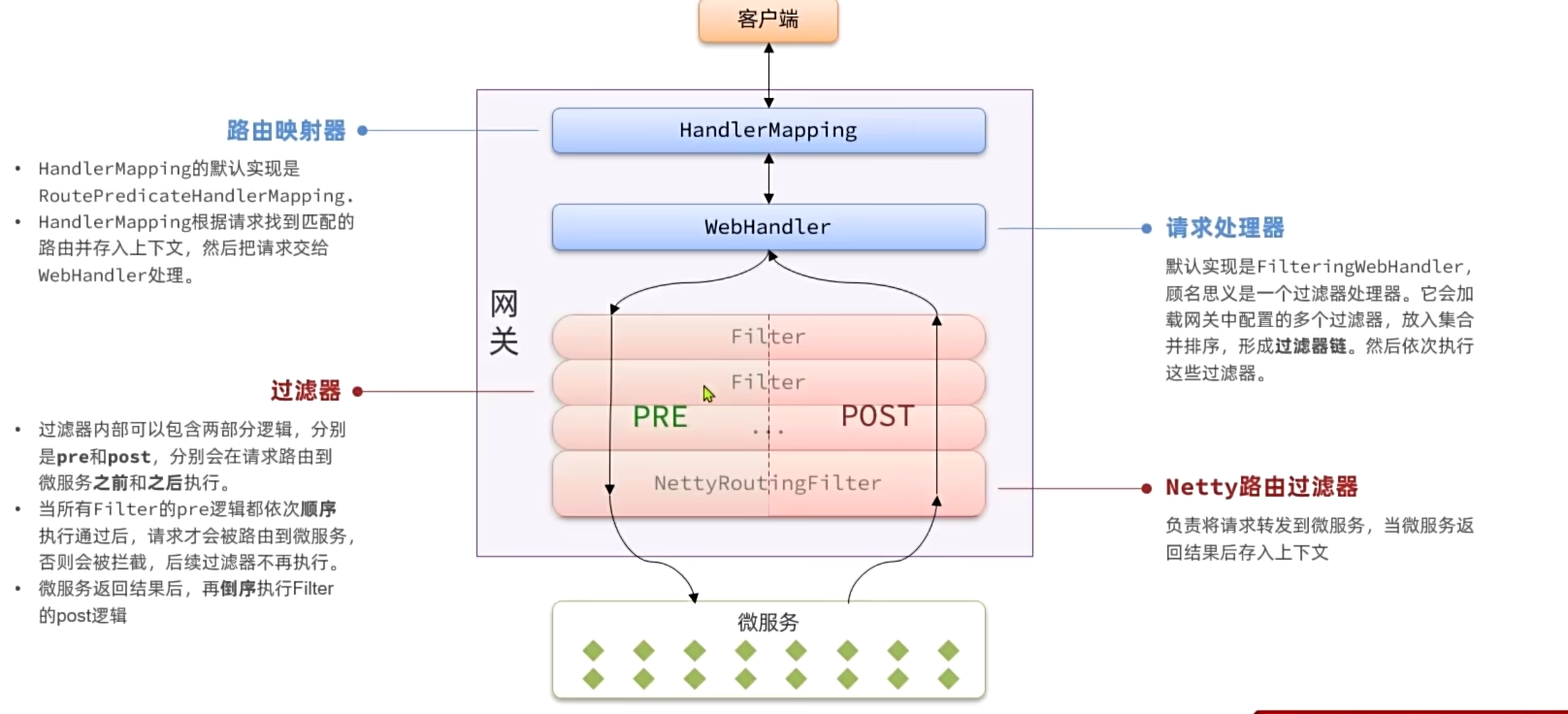
网关请求处理流程
自定义过滤器
介绍
网关过滤器有两种,分别是:
- GatewayFilter:路由过滤器,作用于任意指定的路由;默认不生效,要配置到路由后生效。
- GlobalFilter:全局过滤器,作用范围是所有路由;声明后自动生效。

自定义GlobalFilter
1 | public class MyGlobalFilter implements GlobalFilter , Ordered { |
自定义GatewayFilter
开发当中大部分情况都是使用GlobalFilter的
自定义GatewayFilter不是直接实现GatewayFilter,而是实现AbstractGatewayFilterFactory,示例如下:
实现登录校验
需求:在网关中基于过滤器实现登录校验功能
提示:黑马商城是基于JWT实现的登录校验,目前相关功能在hm-service模块。我们可以将其中的JWT
工具拷贝到gateway模块,然后基于GlobalFilter来实现登录校验。
1 |
|
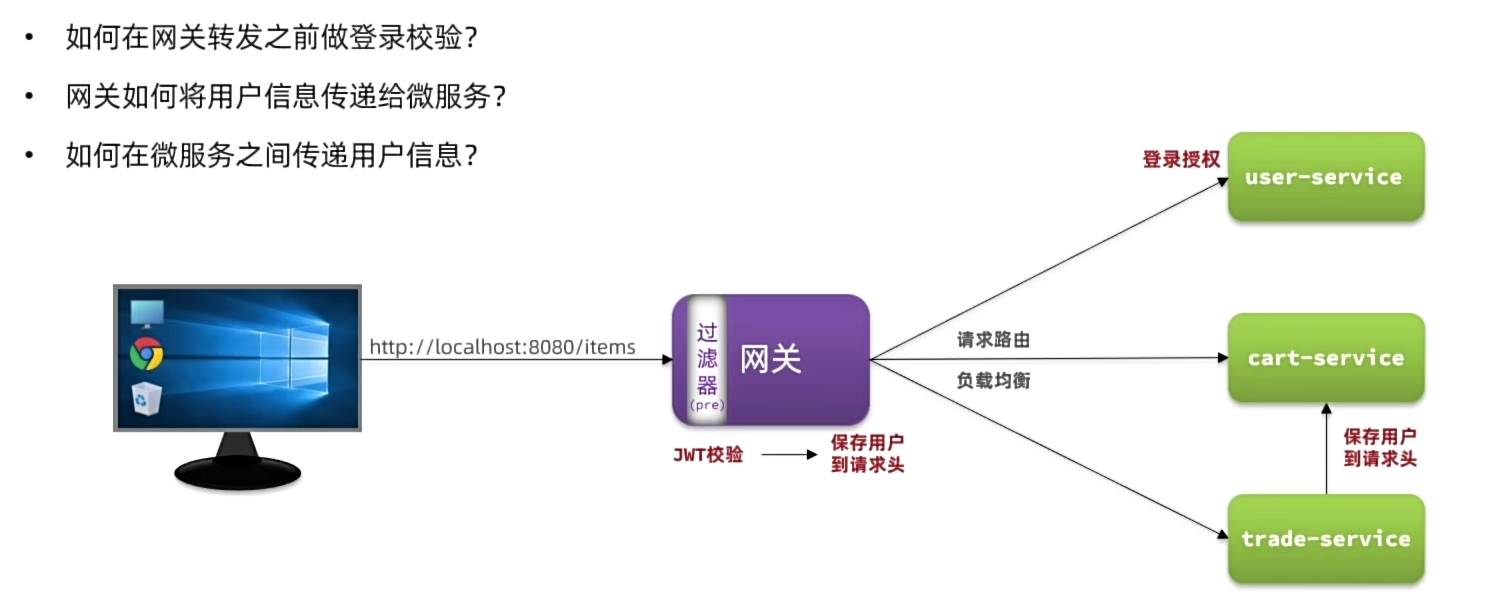
网关传递用户
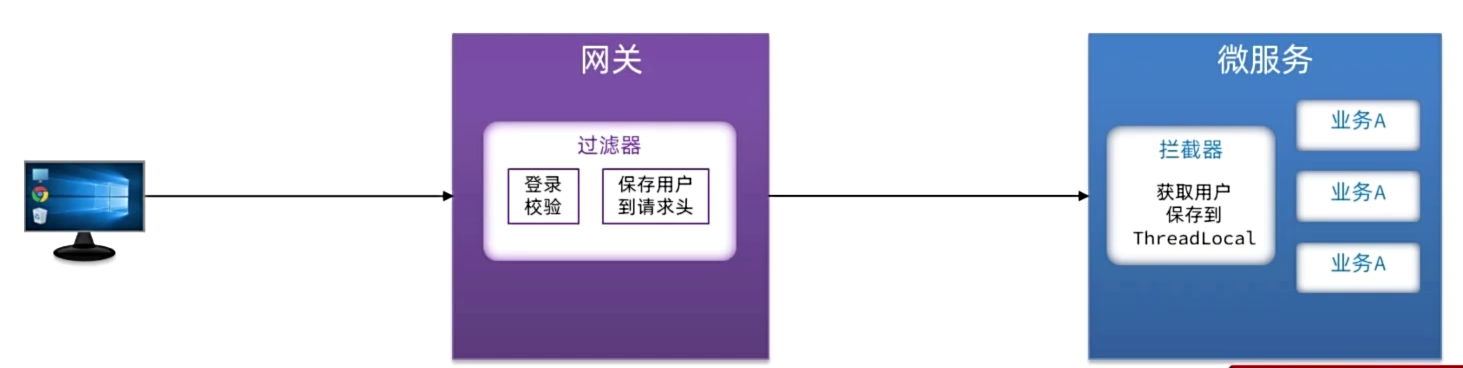
一、在网关的登录校验过滤器中,把获取到的用户写入请求头
需求:修改gateway模块中的登录校验拦截器,在校验成功后保存用户到下游请求的请求头中。
提示:要修改转发到微服务的请求,需要用到ServerWebExchange类提供的APl,示例如下:
1 | String userInfo = userId.toString(); |
二、在hm-common中编写SpringMVc拦截器,获取登录用户
需求:由于每个微服务都可能有获取登录用户的需求,因此我们直接在hm-common模块定义拦截器,这样微服务只需要引入依赖即可生效,无需重复编写。
1 | public class UserInfoInterceptor implements HandlerInterceptor{ |
编写spring.factories
1 |
存在 spring-boot-starter-web
确认接入MVC
1 |
OpenFeign传递用户
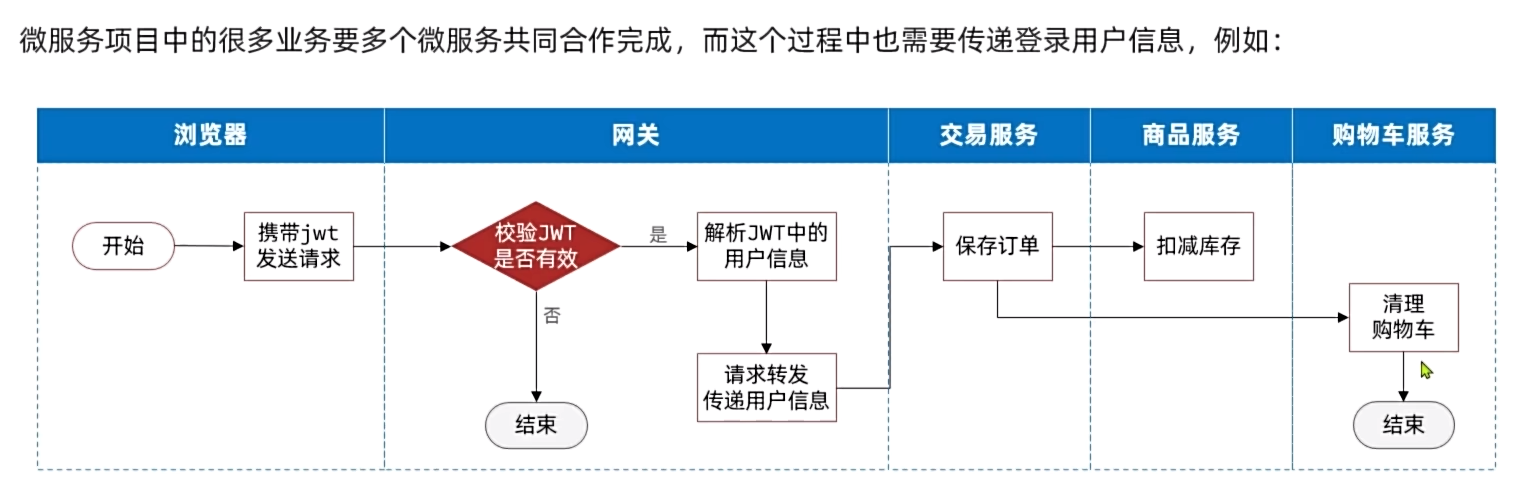
获取请求头的是网关的API,但是服务之间传递调用的是openFeign的API。所以还要在OpenFeign里面设置获取请求头
OpenFeign中提供了一个拦截器接口,所有由OpenFeign发起的请求都会先调用拦截器处理请求:
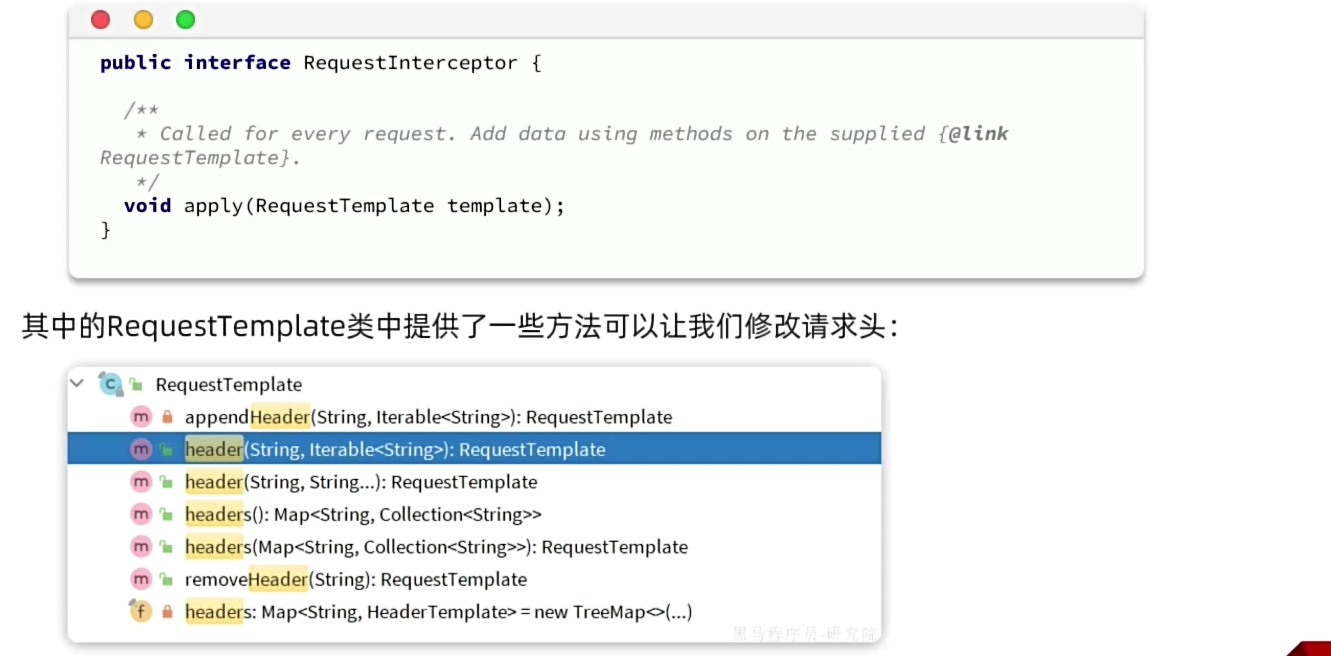
要把配置加在上游的启动类上
1 |
|
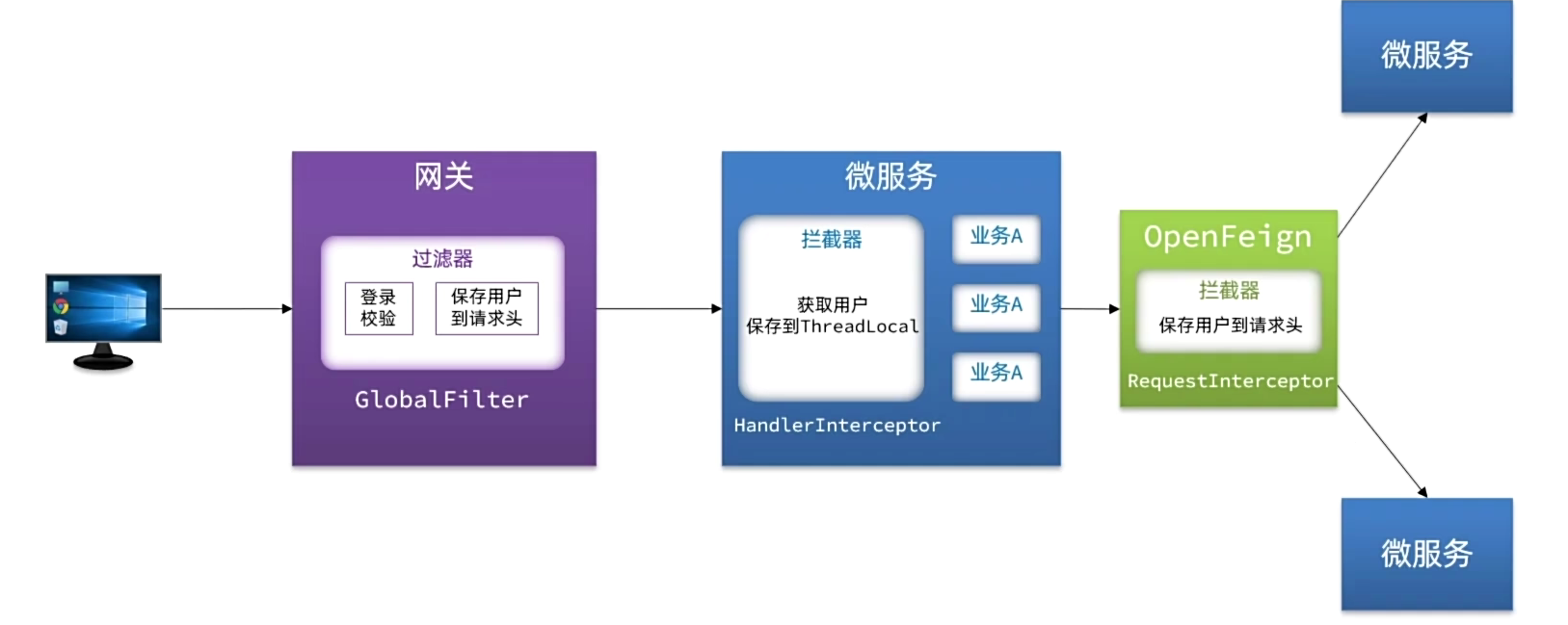
总结来说就是多次微服务之间进行调用,第一个微服务可以从网关中获取用户信息,而第二个则可以通过openFeign中的apply来获取,第三个是因为第二个已经获取用户信息了,所以也可以以此类推
网关->交易服务->api->最终服务 在API阶段获取到token传递到最终服务
每一次都拦截下来,就是为了给下个服务用
配置管理
介绍
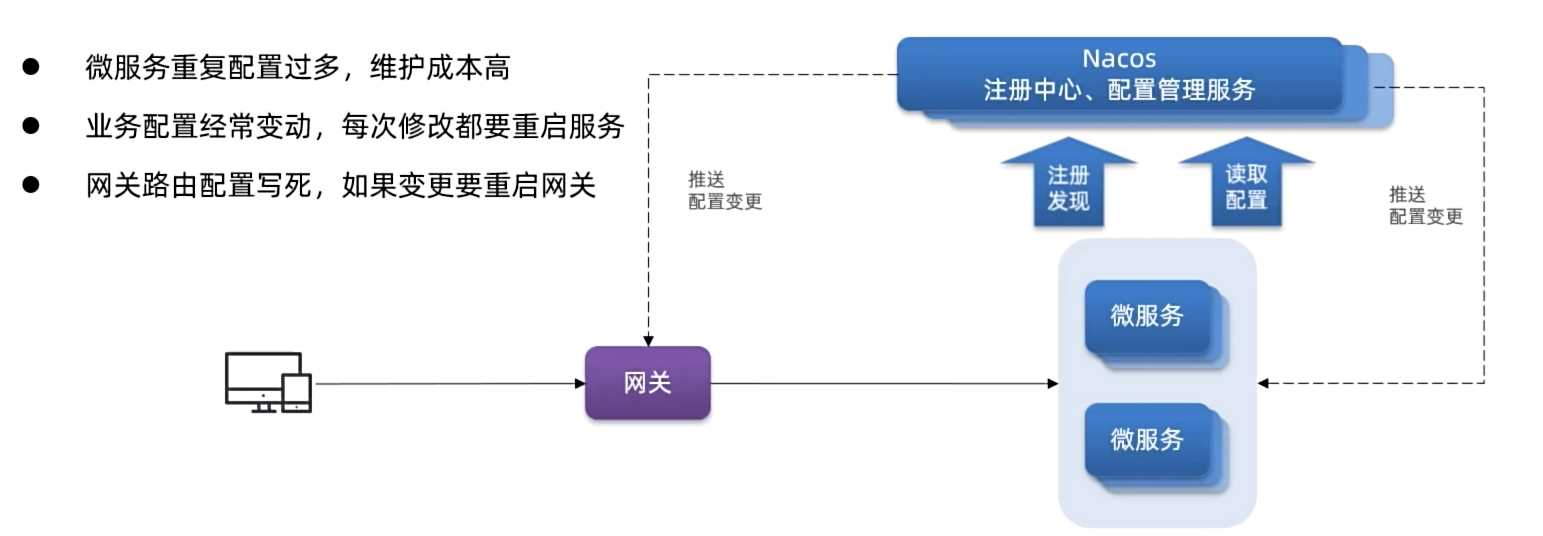
共享配置
一、添加配置到Nacos
添加一些共享配置到Nacos中,包括:Jdbc、MybatisPlus、日志、Swagger、OpenFeign等配置
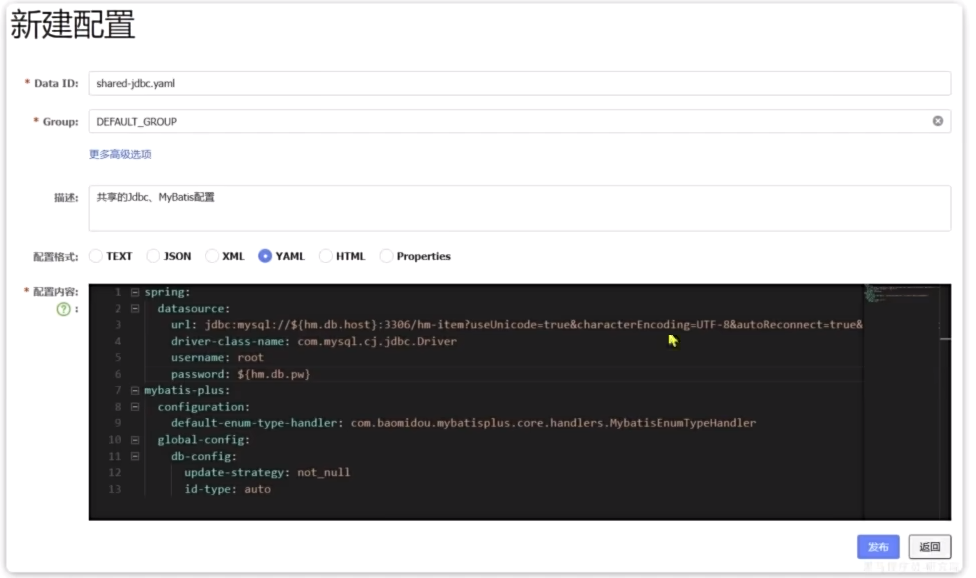
二.拉取共享配置
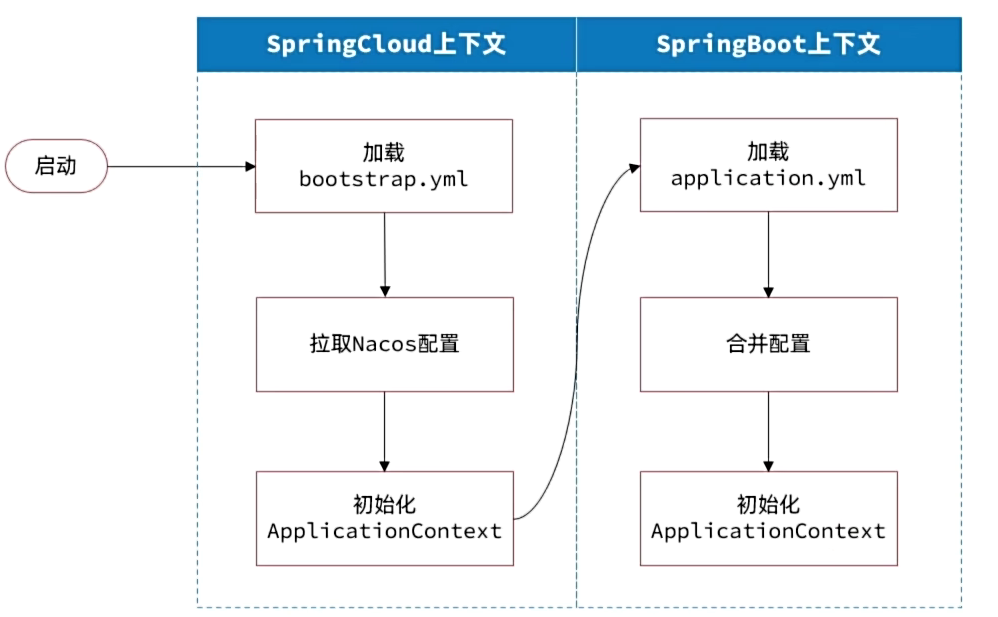
基于NacosConfig拉取共享配置代替微服务的本地配置。
引入依赖
1
2
3
4
5
6
7
8
9
10<!--nacos配置管理-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<!--读取bootstrap文件-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>新建bootstrap.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14spring:
application:
name: cart-service # 服务名称
profiles:
active: dev
cloud:
nacos:
server-addr: 192.168.150.101:8848 # nacos地址
config:
file-extension: yaml # 文件后缀名
shared-configs: # 共享配置
- dataId: shared-jdbc.yaml # 共享mybatis配置
- dataId: shared-log.yaml # 共享日志配置
- dataId: shared-swagger.yaml # 共享日志配置
配置热更新
配置热更新:当修改配置文件中的配置时,微服务无需重启即可使配置生效,
前提条件:
nacos中要有一个与微服务名有关的配置文件。

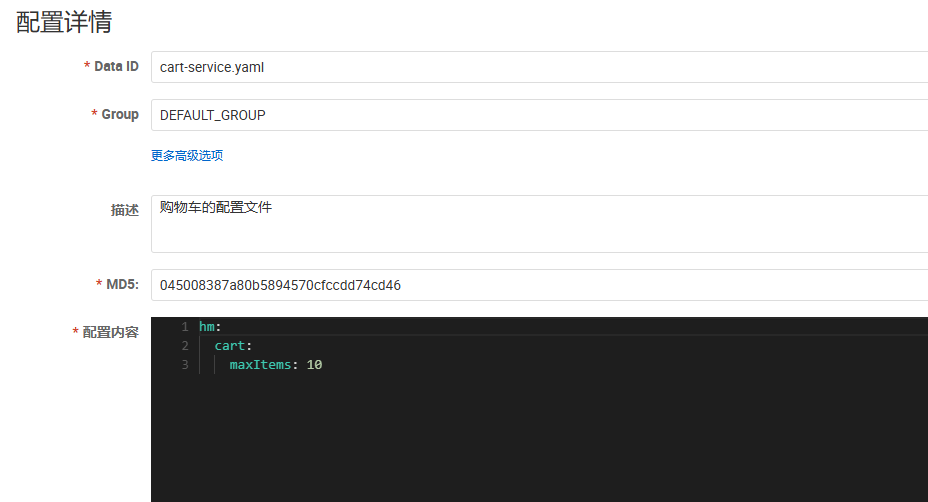
微服务中要以特定方式读取需要热更新的配置属性
1
2
3
4
5
6
7package com.hmall.cart.config;
public class CartProperties {
private int maxItems;
}1
2
3
4
5
6
7
8//不建议使用
publicclass CartProperties{
private int maxItems;
}
需求:购物车的限定数量目前是写死在业务中的,将其改为读取配置文件属性,并将配置交给NacOs管理,实现热更新。
动态路由
要实现动态路由首先要将路由配置保存到Nacos,当Nacos中的路由配置变更时,推送最新配置到网关,实时更新网关中的路由信息。
我们需要完成两件事情:
- 监听Nacos配置变更的消息
- 当配置变更时,将最新的路由信息更新到网关路由表
监听Nacos配置变更可以参考官方文档:https://nacos.io/zh-cn/docs/sdk.html如下
Java SDK
概述部分
Maven 坐标
1 | <dependency> |
1.X 版本最新java SDK为 1.4.4版本
配置管理
获取配置
描述
用于服务启动的时候从 Nacos 获取配置。
1 | public String getConfig(String dataId, String group, long timeoutMs) throws NacosException |
请求参数
| 参数名 | 参数类型 | 描述 |
|---|---|---|
| dataId | string | 配置 ID,采用类似 package.class(如com.taobao.tc.refund.log.level)的命名规则保证全局唯一性,class 部分建议是配置的业务含义。全部字符小写。只允许英文字符和 4 种特殊字符(”.”、”:”、”-“、”_”),不超过 256 字节。 |
| group | string | 配置分组,建议填写产品名:模块名(Nacos:Test)保证唯一性,只允许英文字符和4种特殊字符(”.”、”:”、”-“、”_”),不超过128字节。 |
| timeout | long | 读取配置超时时间,单位 ms,推荐值 3000。 |
返回值
| 参数类型 | 描述 |
|---|---|
| string | 配置值 |
请求示例
1 | try { |
异常说明
读取配置超时或网络异常,抛出 NacosException 异常。
简便做法
1 | private final NacosConfigManager nacosConfigManager; |
监听到路由信息后,可以利用RouteDefinitionWriter来更新路由表:
1 | /** |

微服务保护
雪崩问题
微服务调用链路中的某个服务故障,引起整个链路中的所有微服务都不可用,这就是雪崩。
雪崩问题产生的原因是什么?
- 微服务相互调用,服务提供者出现故障或阻塞。
- 服务调用者没有做好异常处理,导致自身故障。
- 调用链中的所有服务级联失败,导致整个集群故障
解决问题的思路有哪些?
1.尽量避免服务出现故障或阻塞。
- 保证代码的健壮性;
- 保证网络畅通;
- 能应对较高的并发请求;
2.服务调用者做好远程调用异常的后备方案,避免故障扩散
雪崩问题的解决方案
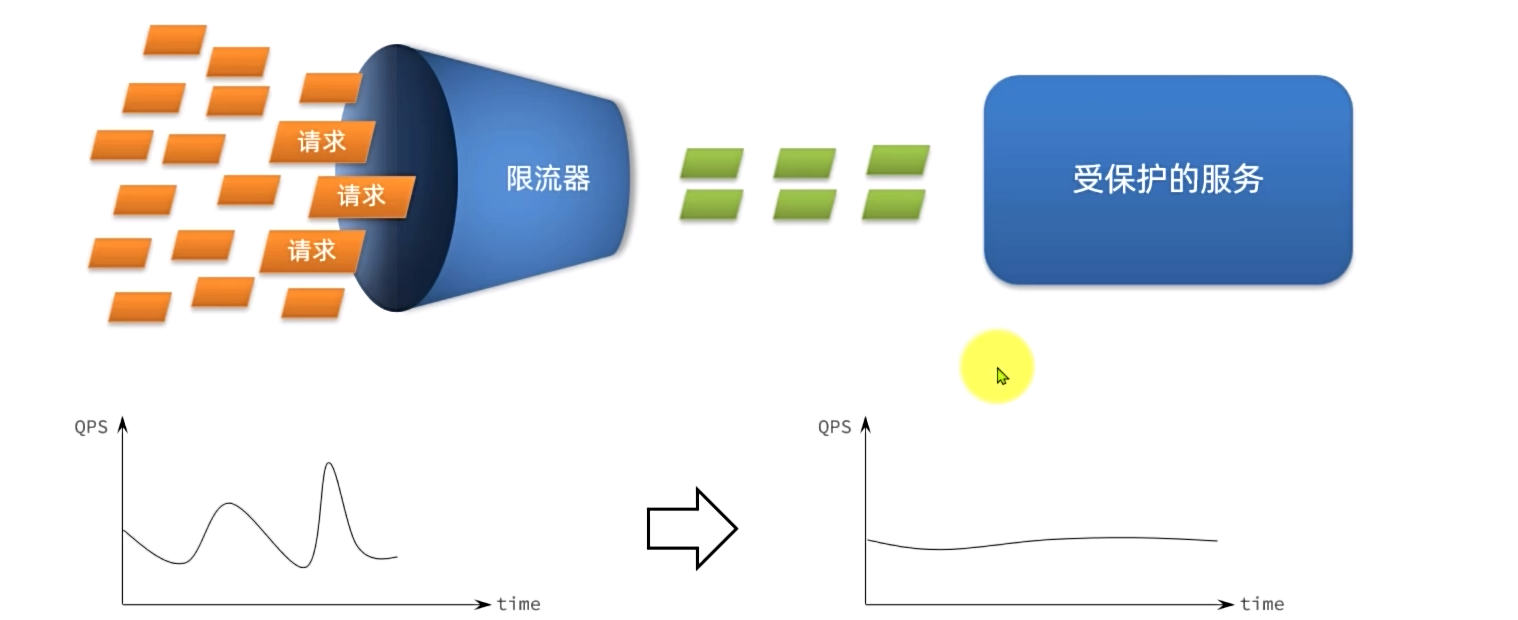
请求限流:限制访问微服务的请求的并发量,避免服务因流量激增出现故障
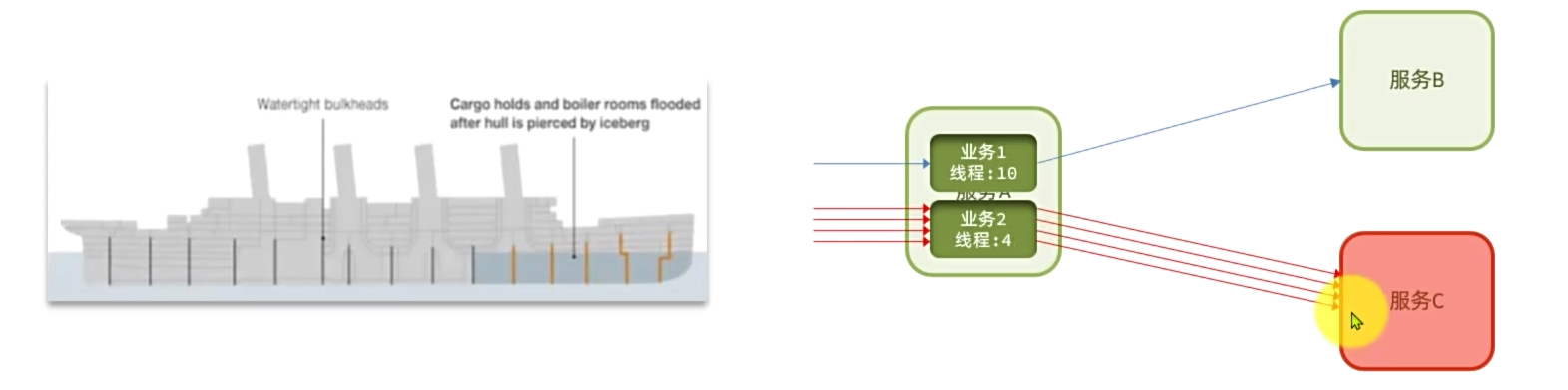
线程隔离
线程隔离:也叫做舱壁模式,模拟船舱隔板的防水原理。通过限定每个业务能使用的线程数量而将故障业务隔离,避免故障扩散。
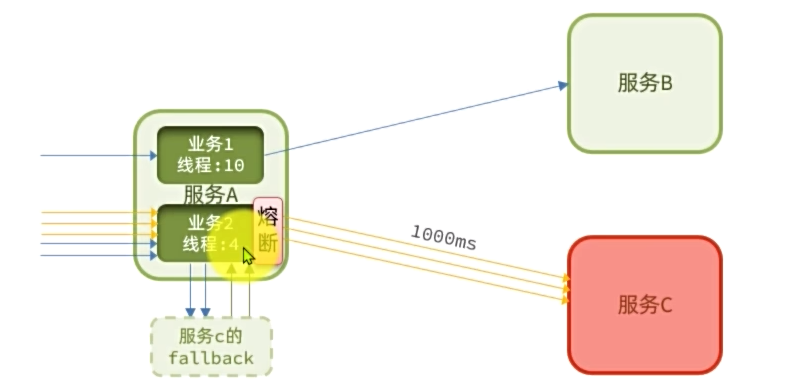
服务熔断
服务熔断:由断路器统计请求的异常比例或慢调用比例,如果超出阀值则会熔断该业务,则拦截该接口的请求。
熔断期间,所有请求快速失败,全都走fallback逻辑。
总结
- 请求限流:限制流量在服务可以处理的范围,避免因突发流量而故障
- 线程隔离:控制业务可用的线程数量,将故障隔离在一定范围
- 服务熔断:将异常比例过高的接口断开,拒绝所有请求,直接走fallback
- 失败处理:定义fallback逻辑,让业务失败时不再抛出异常,而是返回默认数据或友好提示
服务保护技术
| Sentinel | Hystrix | |
|---|---|---|
| 线程隔离 | 信号量隔离 | 线程池隔离/信号量隔离 |
| 熔断策略 | 基于慢调用比例或异常比例 | 基于异常比率 |
| 限流 | 基于 QPS,支持流量整形 | 有限的支持 |
| Fallback | 支持 | 支持 |
| 控制台 | 开箱即用,可配置规则、查看秒级监控、机器发现等 | 不完善 |
| 配置方式 | 基于控制台,重启后失效 | 基于注解或配置文件,永久生效 |
Sentinel
介绍
Sentinel是阿里巴巴开源的一款微服务流量控制组件。官网地址:https://sentinelguard.io/zh-cn/index.html
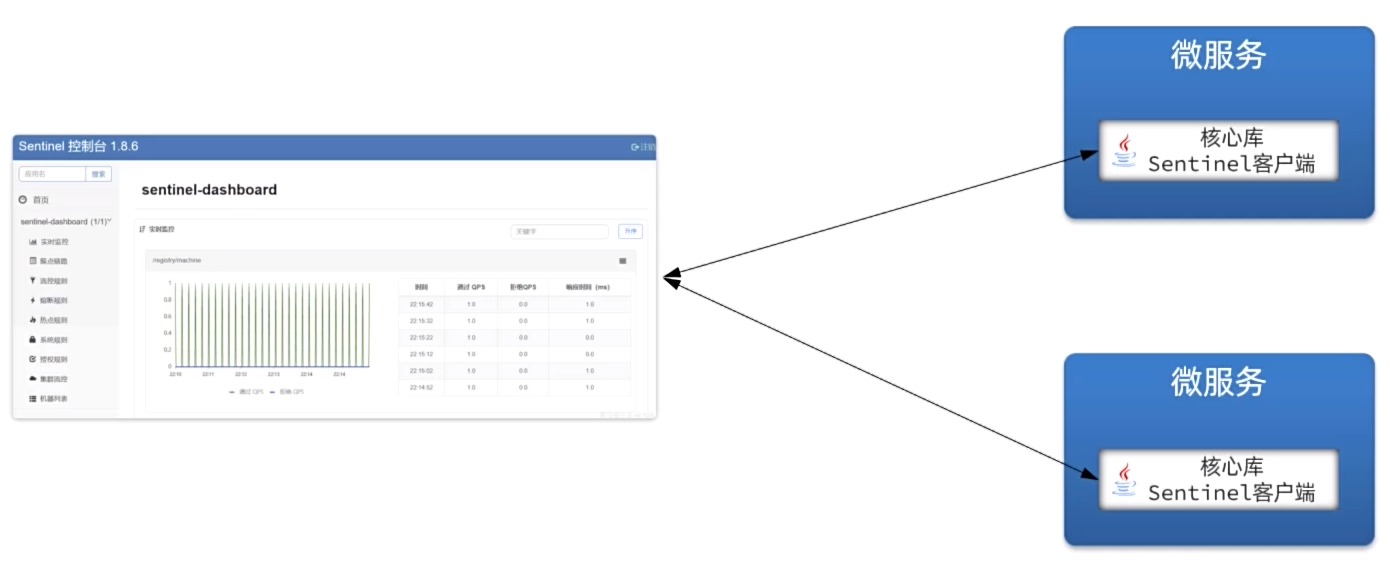
使用
运行
将jar包放在任意非中文、不包含特殊字符的目录下,重命名为sentinel-dashboard.jar:
然后运行如下命令启动控制台:
1 | java -Dserver.port=8090 -Dcsp.sentinel.dashboard.server=localhost:8090 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard.jar |
其它启动时可配置参数可参考官方文档:
https://github.com/alibaba/Sentinel/wiki/%E5%90%AF%E5%8A%A8%E9%85%8D%E7%BD%AE%E9%A1%B9
或者使用docker容器
1 | docker run --name sentinel -p 8090:8858 \ -p 8719:8719 -td bladex/sentinel-dashboard |
1 | sentinel: |
同时记得虚拟机是桥接模式,即要虚拟机和宿主机可以互相ping!!!!!!
记得和nacos一个网桥
3)访问
访问http://服务器IP:8090页面,就可以看到sentinel的控制台了:
使用默认凭证登录:
- 用户名:
sentinel - 密码:
sentinel
使用
1)我们在cart-service模块中整合sentinel,连接sentinel-dashboard控制台,步骤如下: 1)引入sentinel依赖
1 | <!--sentinel--> |
2)配置控制台
修改application.yaml文件,添加下面内容:
1 | spring: |
3)访问cart-service的任意端点
重启cart-service,然后访问查询购物车接口,sentinel的客户端就会将服务访问的信息提交到sentinel-dashboard控制台。并展示出统计信息:
簇点链路
簇点链路,就是单机调用链路。是一次请求进入服务后经过的每一个被Sentinel监控的资源链。默认Sentinel会监控SpringMVC的每一个Endpoint(http接口)。限流、熔断等都是针对簇点链路中的资源设置的。而资源名默认就是接口的请求路径:
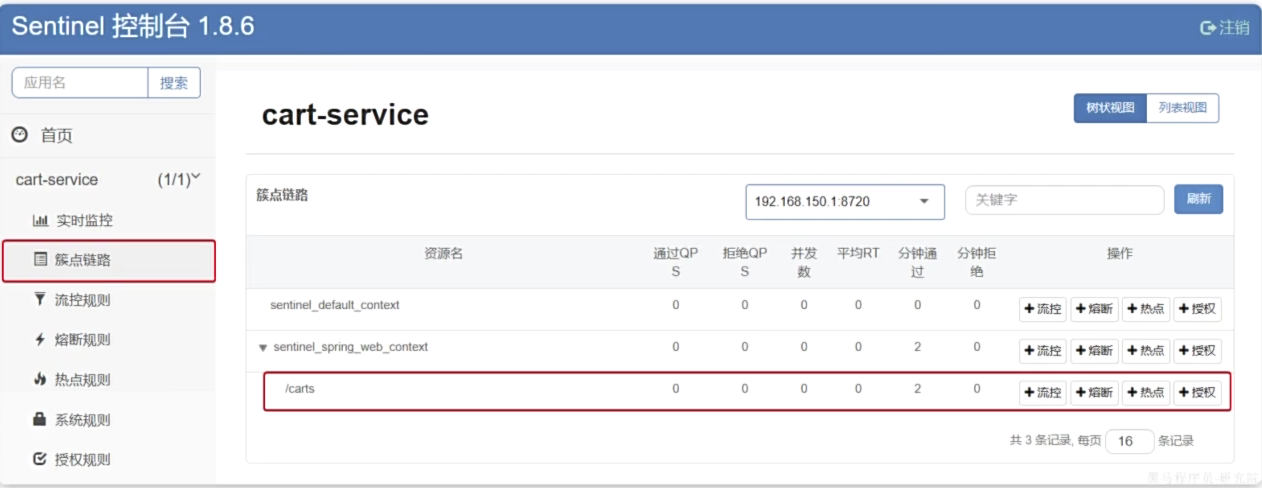
Resful风格的API请求路径一般都相同,这会导致簇点资源名称重复。因此我们要修改配置,把请求方式+请求路径作为簇点资源名称:
1 | sentinel: |
请求限流
QPS是每一个线程每一秒可以处理的请求次数
在簇点链路后面点击流控按钮,即可对其做限流配置:
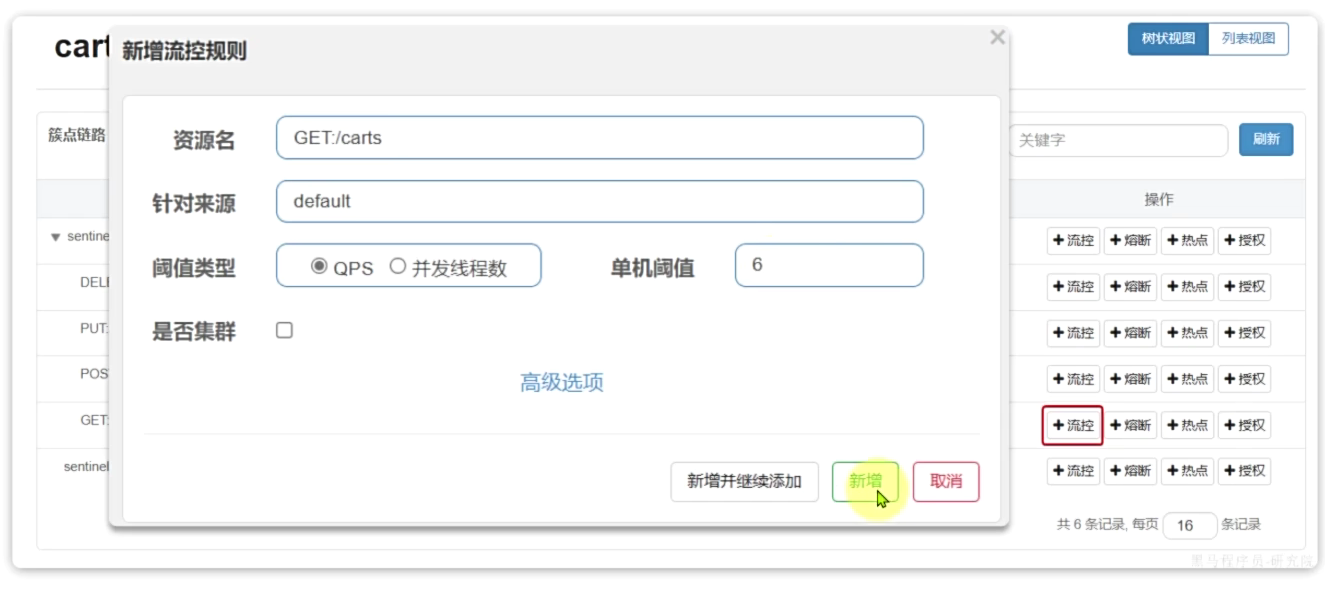
线程隔离
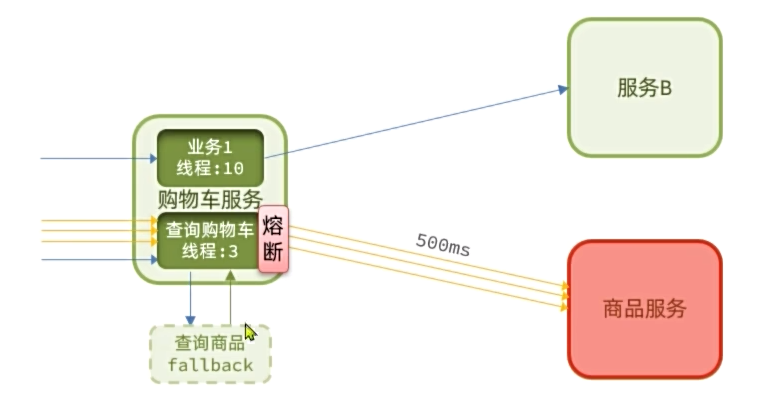
当商品服务出现阻塞或故障时,调用商品服务的购物车服务可能因此而被拖慢,甚至资源耗尽。所以必须限制购物车服务中查询商品这个业务的可用线程数,实现线程隔离。
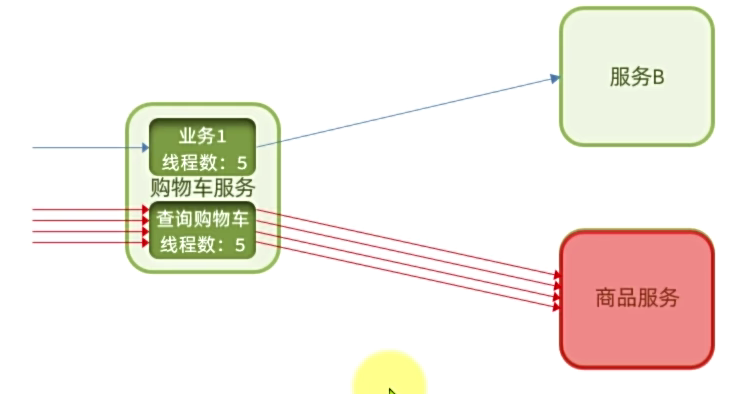
在sentinel控制台中,会出现Feign接口的簇点资源,点击后面的流控按钮,即可配置线程隔离:
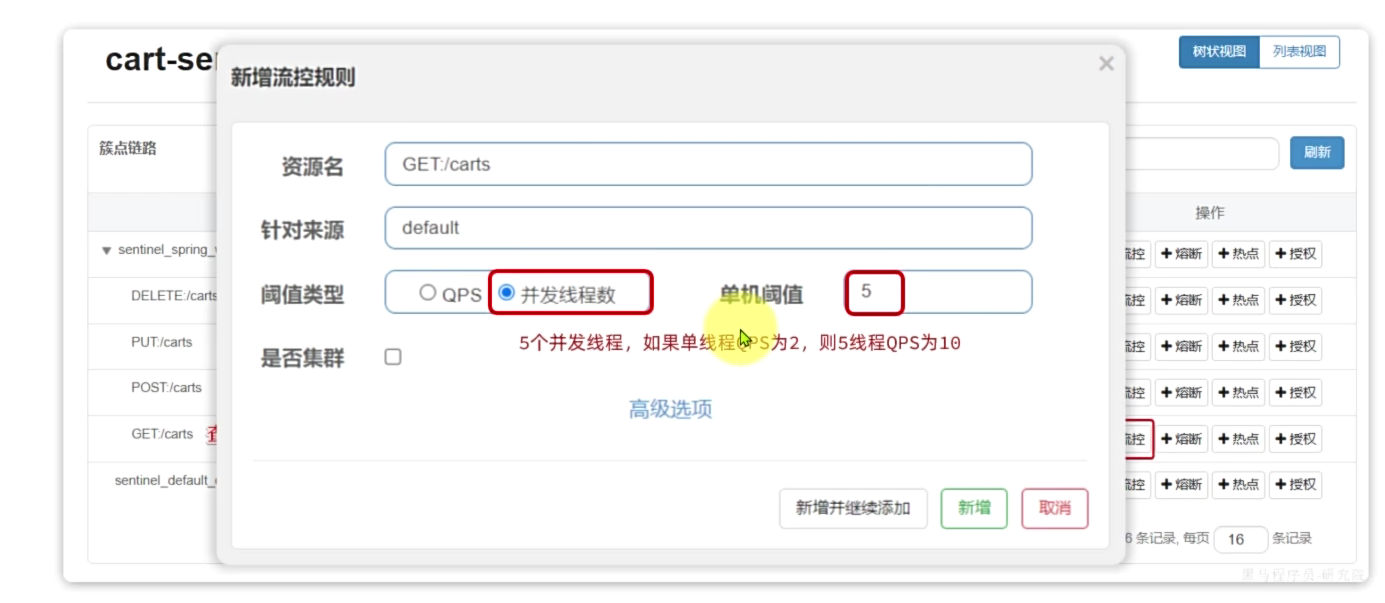
Fallback
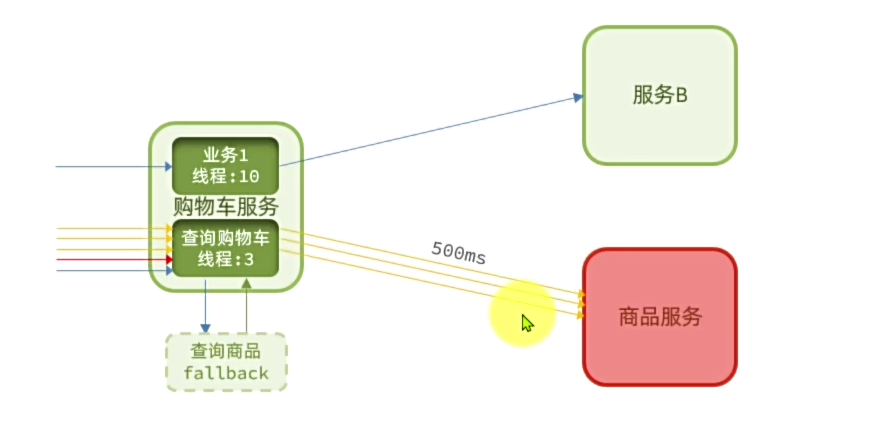
1.将FeignClient作为Sentinel的簇点资源:
1 | feign: |
2.FeignClient的Fallback有两种配置方式:
- 方式一:FallbackClass,无法对远程调用的异常做处理
- 方式二:FallbackFactory,可以对远程调用的异常做处理,通常都会选择这种
给FeignClient编写Fallback逻辑
假如我们有一个FeignClient如下:
1 |
|
为其编写Fallback逻辑
步骤一:自定义类,实现FallbackFactory,编写对某个FeignClient的fallback逻辑:
1 |
|
步骤二:将刚刚定义的UserClientFallbackFactory注册为一个Bean:
1 |
|
步骤三:在UserClient接口中使用UserClientFallbackFactory:
1 |
|
服务熔断
熔断是解决雪崩问题的重要手段。思路是由断路器统计服务调用的异常比例、慢请求比例,如果超出阈值则会熔断该服务。即拦截访问该服务的一切请求;而当服务恢复时,断路器会放行访问该服务的请求。
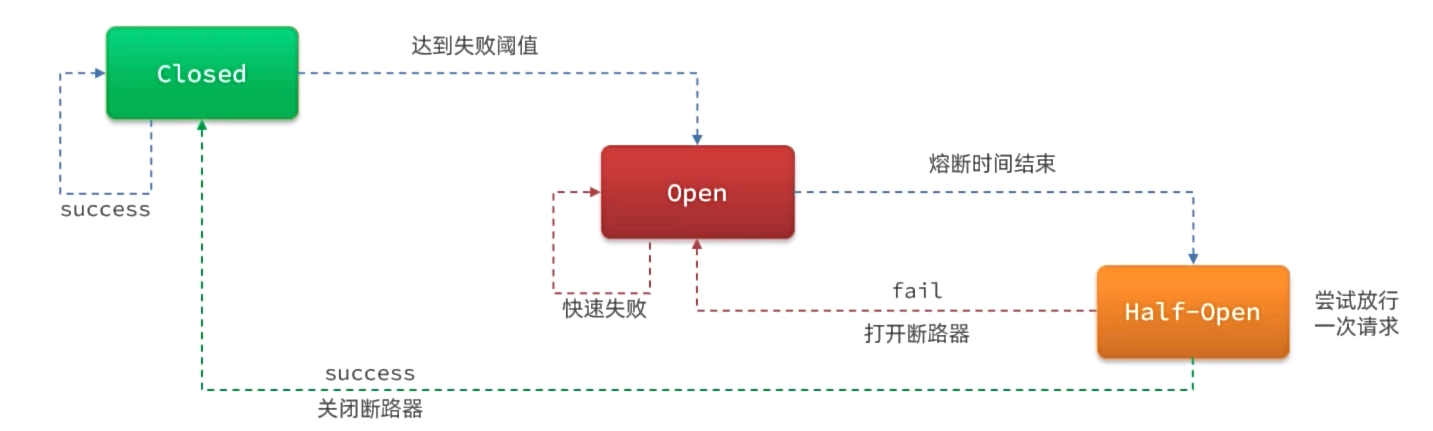
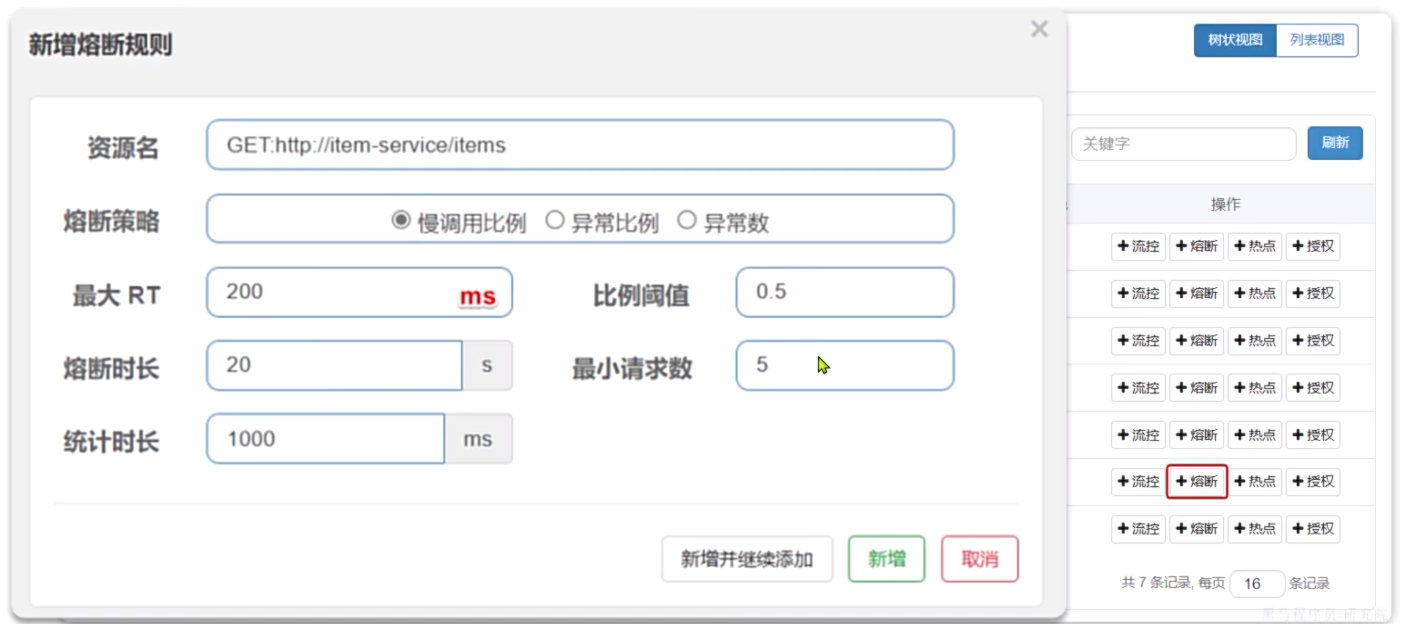
点击控制台中簇点资源后的熔断按钮,民即可配置熔断策略:
持久化服务保护
Jmeter
1.安装Jmeter
Jmeter依赖于JDK,所以必须确保当前计算机上已经安装了JDK,并且配置了环境变量。
1.1.下载
可以Apache Jmeter官网下载,地址:http://jmeter.apache.org/download_jmeter.cgi

当然,我们课前资料也提供了下载好的安装包:
1.2.解压
因为下载的是zip包,解压缩即可使用,目录结构如下:
其中的bin目录就是执行的脚本,其中包含启动脚本:
1.3.运行
双击即可运行,但是有两点注意:
- 启动速度比较慢,要耐心等待
- 启动后黑窗口不能关闭,否则Jmeter也跟着关闭了
2.快速入门
2.1.设置中文语言
默认Jmeter的语言是英文,需要设置:
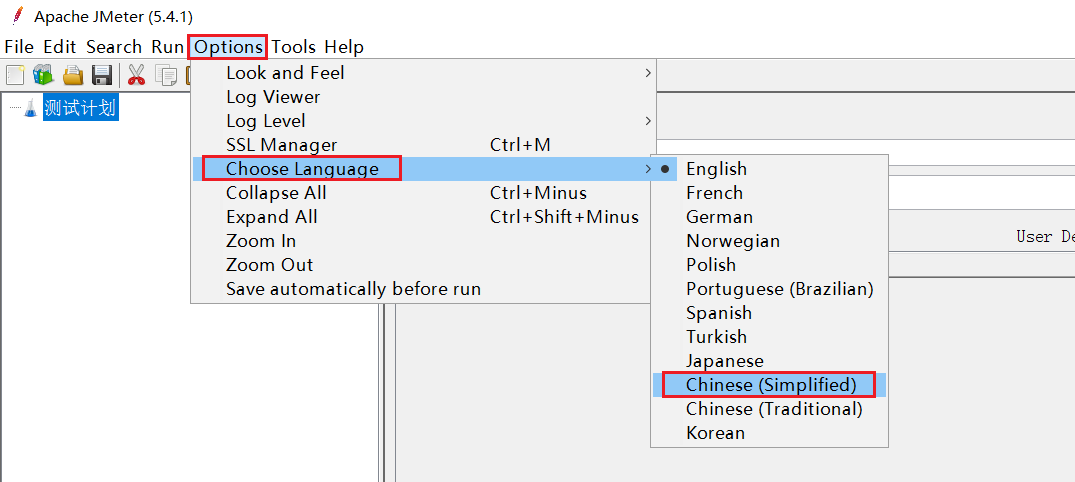
效果:
注意:上面的配置只能保证本次运行是中文,如果要永久中文,需要修改Jmeter的配置文件
打开jmeter文件夹,在bin目录中找到 jmeter.properties,添加下面配置:
1 | language=zh_CN |
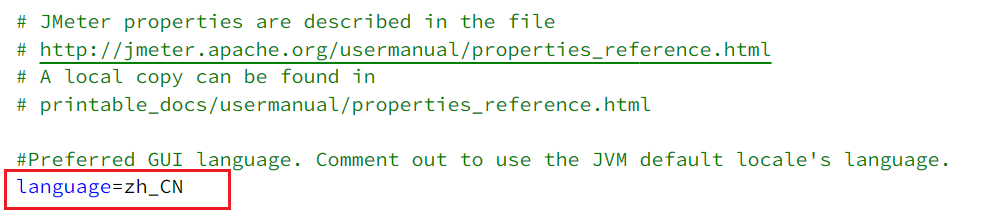
注意:前面不要出现#,#代表注释,另外这里是下划线,不是中划线
2.2.基本用法
在测试计划上点鼠标右键,选择添加 > 线程(用户) > 线程组:
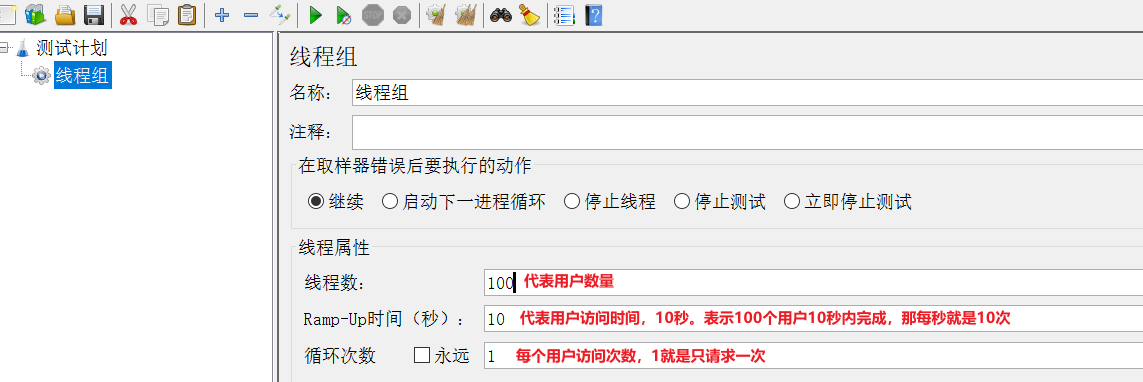
在新增的线程组中,填写线程信息:
给线程组点鼠标右键,添加http取样器:
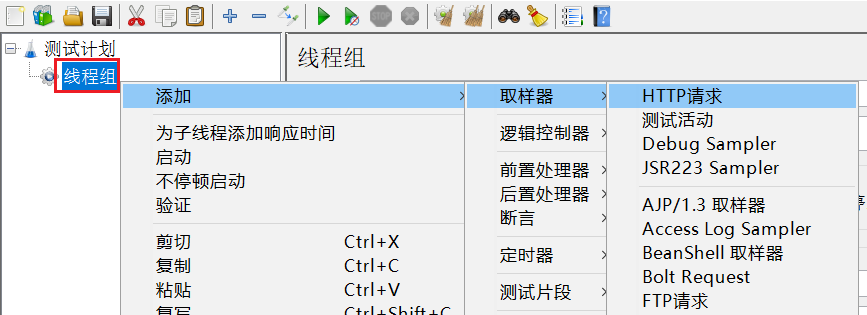
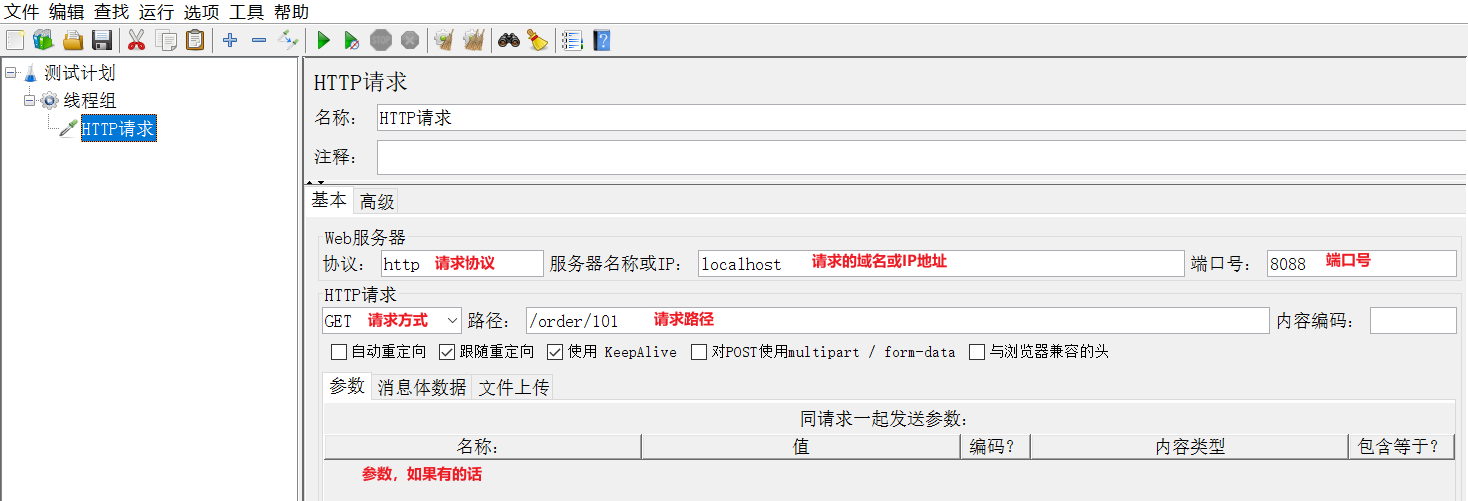
编写取样器内容:
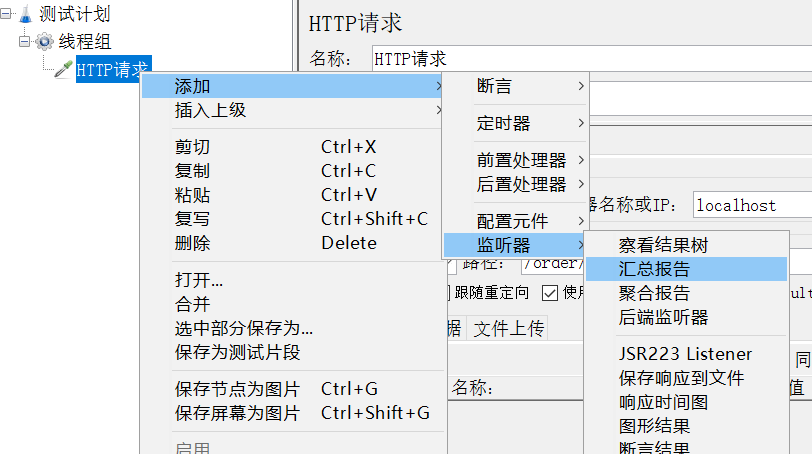
添加监听报告:
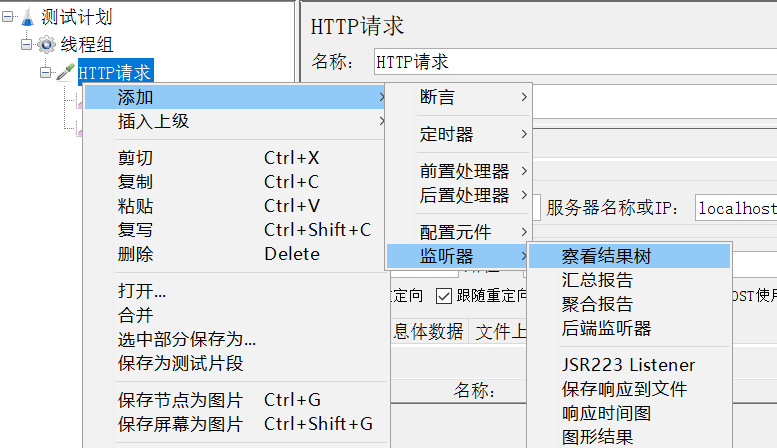
添加监听结果树:
汇总报告结果:

结果树:
分布式事务
原子性 一致性 隔离性 持久性
下单业务,前端请求首先进入订单服务,仓创建订单并写入数据库。多然后订单服务调用购物车服务和库存服务:
- 购物车服务负责清理购物车信息
- 库存服务负责扣减商品库存
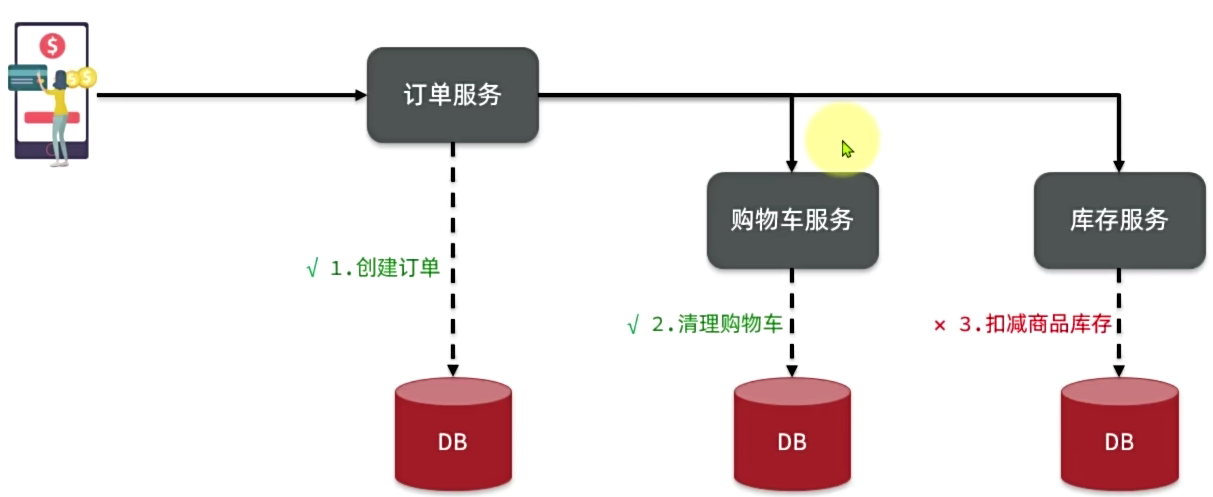
都不是一个service无法一起回滚
在分布式系统中,如果一个业务需要多个服务合作完成,而且每一个服务都有事务,多个事务必须同时成功或失败,这样的事务就是分布式事务。其中的每个服务的事务就是一个分支事务。整个业务称为全局事务。
初识Seata
Seata是2019年1月份蚂蚁金服和阿里巴巴共同开源的分布式事务解决方案。致力于提供高性能和简单易用的分布式
事务服务,为用户打造一站式的分布式解决方案。
官网地址:http://seata.io/,其中的文档、播客中提供了大量的使用说明、源码分析。
解决分布式事务,各个子事务之间必须能感知到彼此的事务状态,才能保证状态一致。
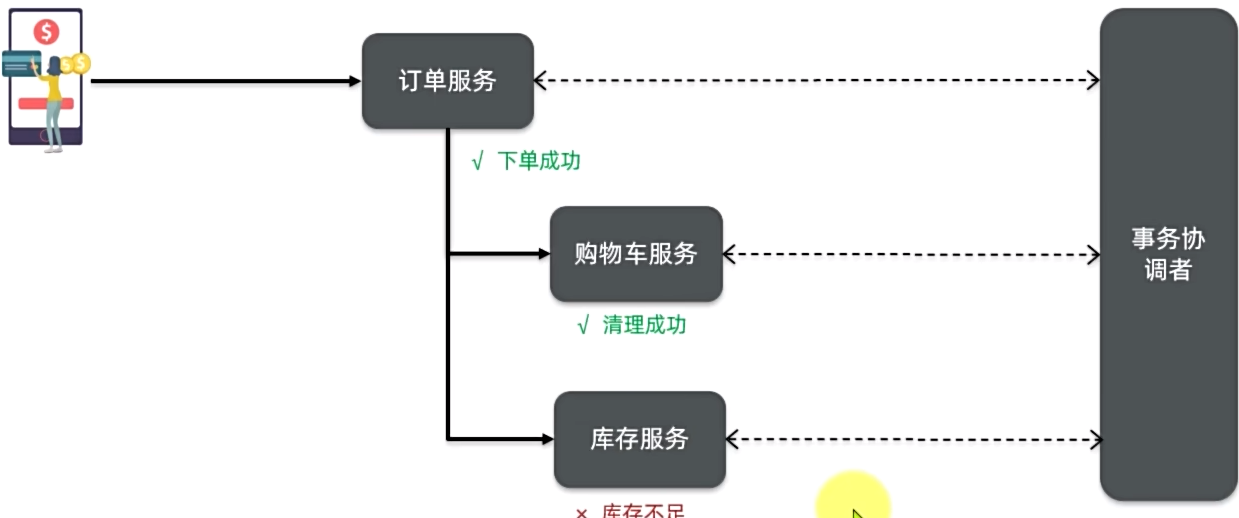
Seata架构
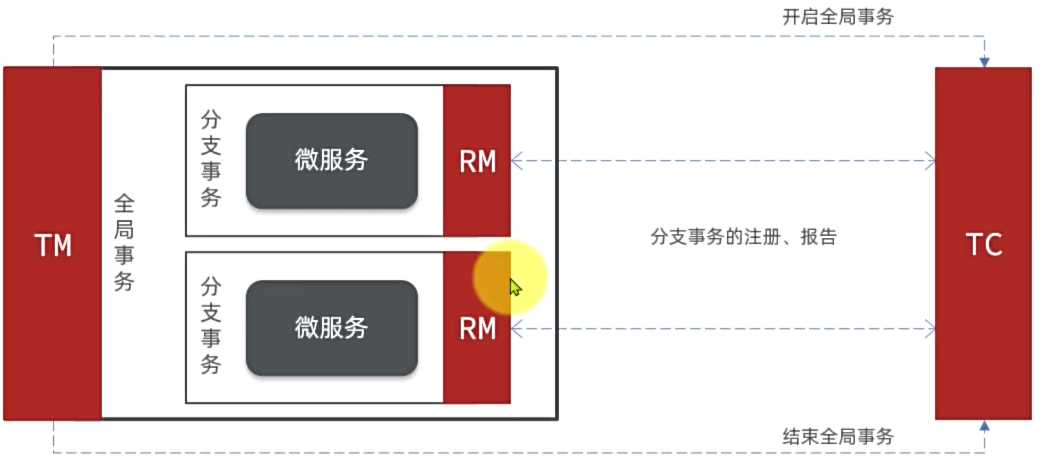
Seata事务管理中有三个重要的角色:
- TC(TransactionCoordinator)-事务协调者:维护全局和分支事务的状态,协调全局事务提交或回滚。
- TM(TransactionManager)-事务管理器:定义全局事务的范围、开始全局事务、提交或回滚全局事务。
- RM(ResourceManager)-资源管理器:管理分支事务,与TC交谈以注册分支事务和报告分支事务的状态
部署TC服务
微服务集成Seata
准备Seata
Seata支持多种存储模式,但考虑到持久化的需要,我们一般选择基于数据库存储。
seata运行时还需要配置文件
将整个seata文件夹拷贝到虚拟机的/root目录
需要注意,要确保nacos、mysql都在hm-net网络中。如果某个容器不再hm-net网络,可以参考下面的命令将某容器加入指定网络
1 | docker run --name seata \ |
出现out of memory,在run命令的network之前加上–ulimit nofile=65536:65536 \
微服务集成Seata
参与分布式事y的每一个微服务都需要集成Seata,我们以trade-service为例。
引入依赖
为了方便各个微服务集成seata,我们需要把seata配置共享到nacos,因此trade-service模块不仅仅要引入seata依赖,还要引入nacos依赖:
1 | <!--统一配置管理--> |
改造配置
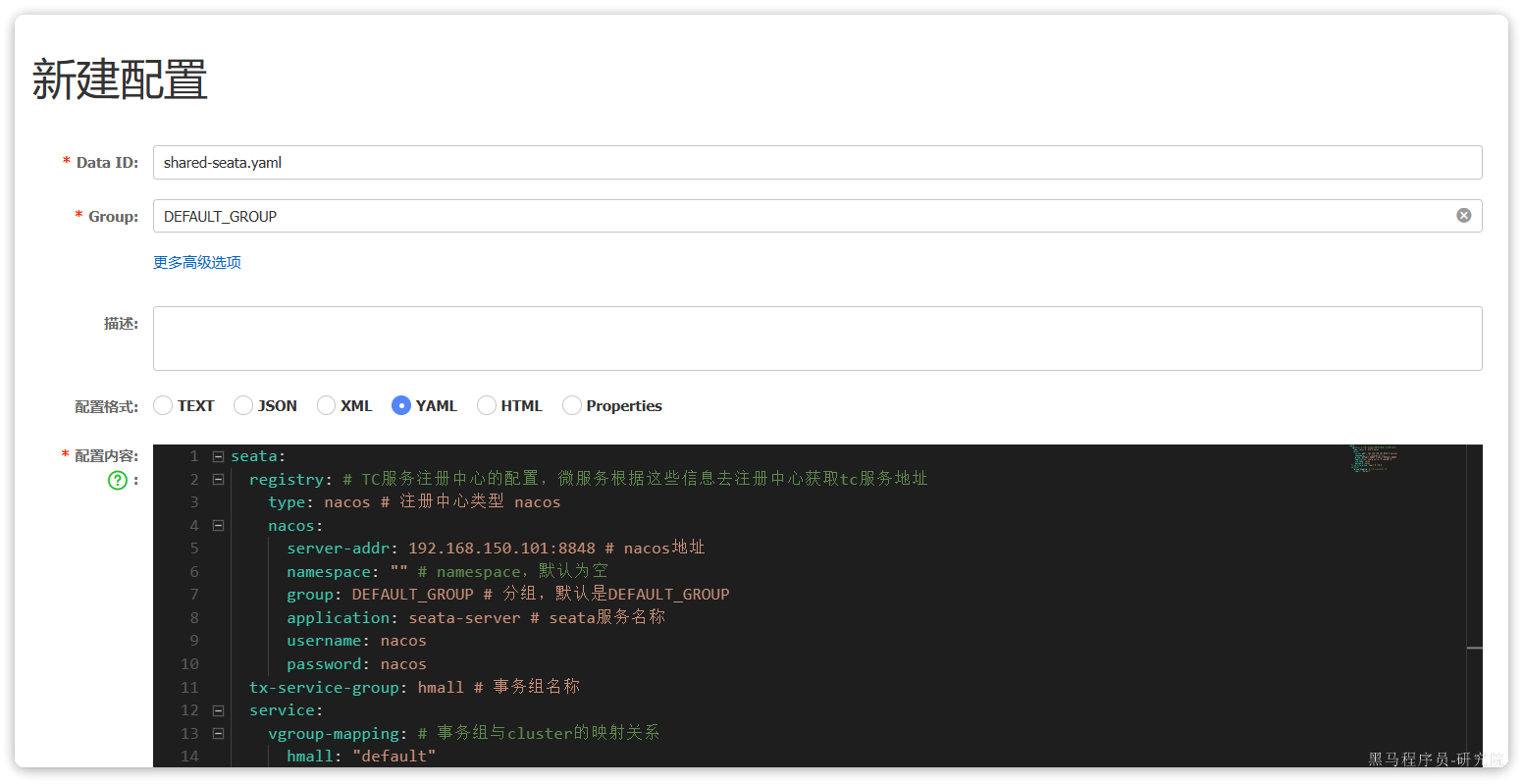
内容如下(他只是被nacos发现了,seata并没有发现nacos):
1 | seata: |
集群:若干个TC实例的集合
事务组:需要分布式事务的微服务和若干个TC实例的集合
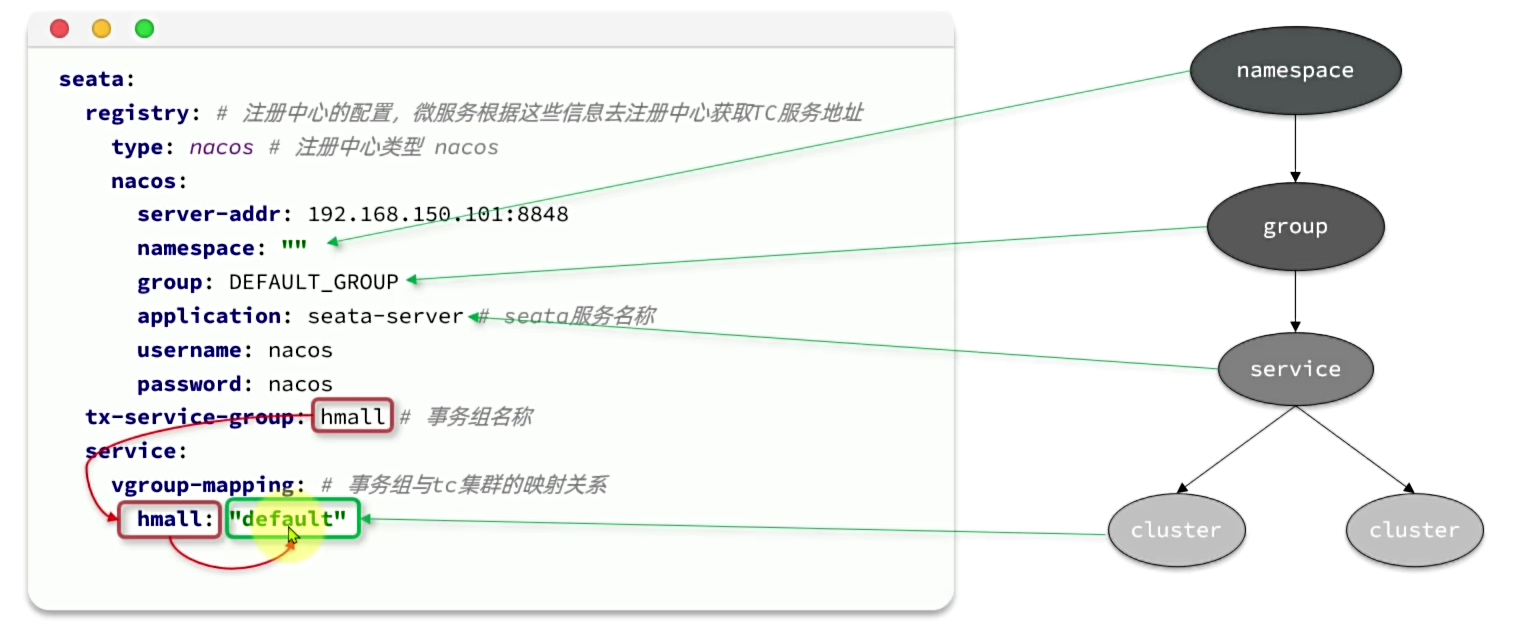
然后,改造trade-service模块,添加bootstrap.yaml:
内容如下:
1 | spring: |
可以看到这里加载了共享的seata配置。
然后改造application.yaml文件,内容如下:
1 | server: |
参考上述办法分别改造hm-cart和hm-item两个微服务模块。
seata的客户端在解决分布式事务的时候需要记录一些中间数据,保存在数据库中。因此我们要先准备一个这样的表。
将课前资料的seata-at.sql分别文件导入hm-trade、hm-cart、hm-item三个数据库中:
结果:
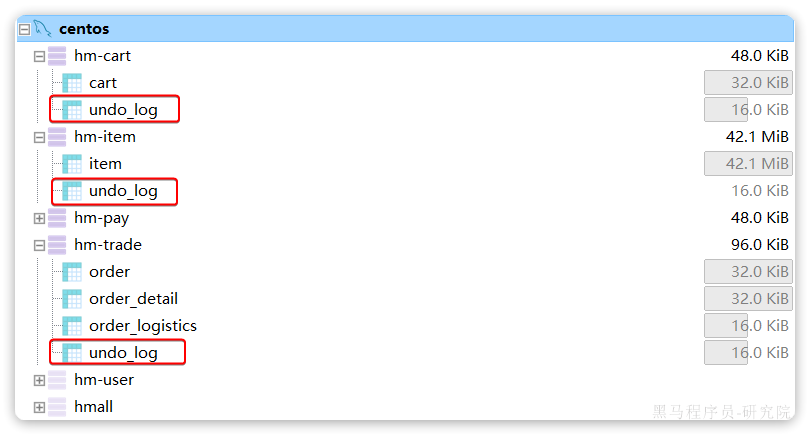
OK,至此为止,微服务整合的工作就完成了。可以参考上述方式对hm-item和hm-cart模块完成整合改造。
XA模式
介绍
XA规范是X/Open组织定义的分布式事务处理(DTP,DistributedTransactionProcessing)标准,XA规范描述了全局的TM与局部的RM之间的接口,几乎所有主流的关系型数据库都对XA规范提供了支持。Seata的XA模式如下:
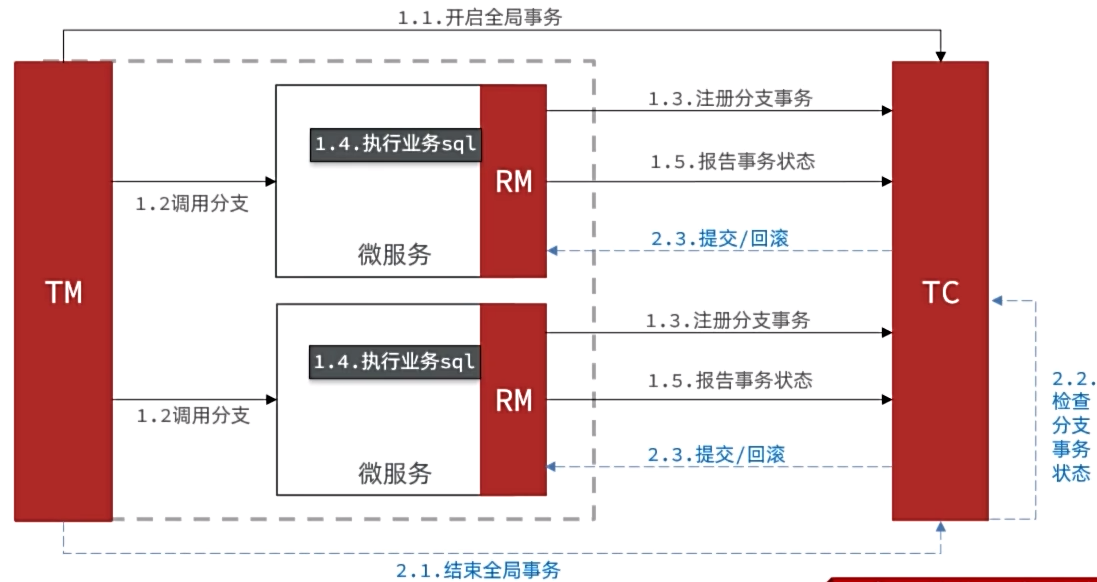
一阶段的工作:
- RM注册分支事务到TC
- RM执行分支业务sql但不提交
- RM报告执行状态到TC
二阶段的工作:
- TC检测各分支事务执行状态
- 如果都成功,通知所有RM提交事务
- 如果有失败,通知所有RM回滚事务
- RM接收TC指令,提交或回滚事务
优点:
- 事务的强一致性,满足ACID原则。
- 常用数据库都支持,实现简单,并且没有代码侵入
缺点:
- 因为一阶段需要锁定数据库资源,等待二阶段结束才释放,性能较差
- 依赖关系型数据库实现事务
实现XA模式
Seata的starter已经完成了xA模式的自动装配,实现非常简单,步骤如下:
修改application.yml文件(每个参与事务的微服务),开启xA模式:
1
2seata:
data-source-proxy-mode: XA # 核心配置:开启数据源代理的XA模式(实现分布式事务的原子性)给发起全局事务的入口方法添加@GlobalTransactional注解,本例中是OrderServicelmpl中的create方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// 可选:指定所有异常都回滚(更严谨)
public Long createOrder(OrderFormDTO order) {
// 1. 创建订单(本地事务)
Order entity = convertToEntity(order);
orderMapper.insert(entity);
// 2. 清理购物车(远程调用:调用购物车服务)
cartFeignClient.clearCart(order.getUserId());
// 3. 扣减库存(远程调用:调用库存服务)
inventoryFeignClient.reduceStock(order.getSkuId(), order.getQuantity());
return entity.getId(); // 返回订单ID
}重启服务并测试
AT模式(重要)
介绍
Seata主推的是AT模式,AT模式同样是分阶段提交的事务模型,不过缺弥补了XA模型中资源锁定周期过长的缺陷。
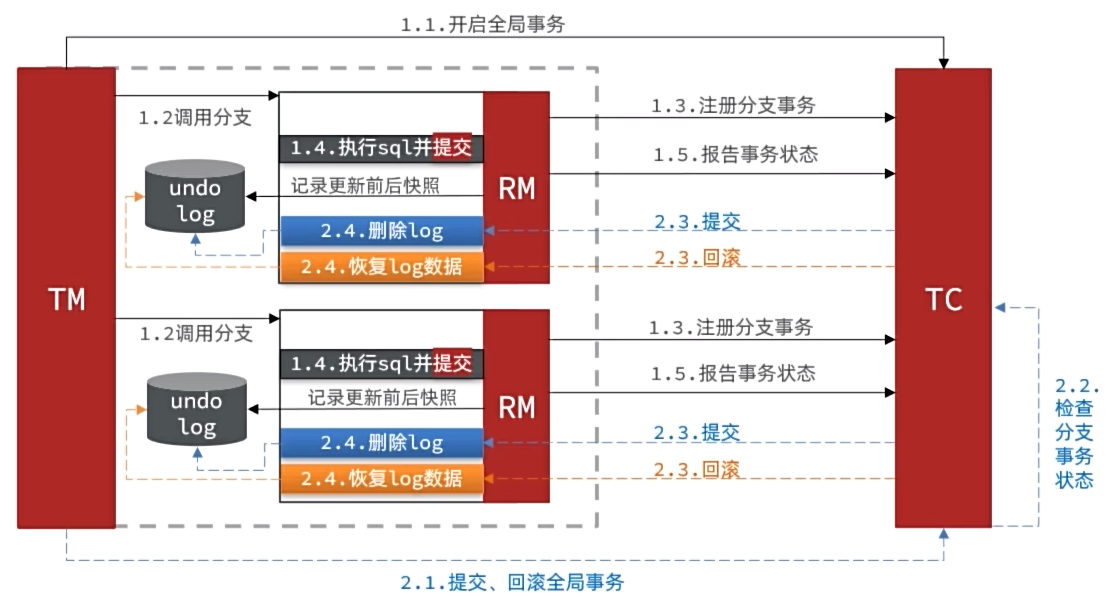
阶段一RM的工作:
- 注册分支事务
- 记录undo-log(数据快照)
- 执行业务sql并提交
- 报告事务状态
阶段二提交时RM的工作:
- 删除undo-log即可
阶段二回滚时RM的工作:
- 根据undo-log恢复数据到更新前
实现AT模式
首先,添加资料中的seata-at.sgl到微服务对应的数据库中:
1 | CREATE TABLE IF NOT EXISTS `undo_log` |
然后,修改application.yml文件,将事务模式修改为AT模式:
1 | seata: |
AT与XA的区别
- XA模式一阶段不提交事务,锁定资源;AT模式一阶段直接提交,不锁定资源。
- XA模式依赖数据库机制实现回滚;AT模式利用数据快照实现数据回滚。
- XA模式强一致;AT模式最终一致
MQ入门
初识MQ
介绍
同步调用优缺点
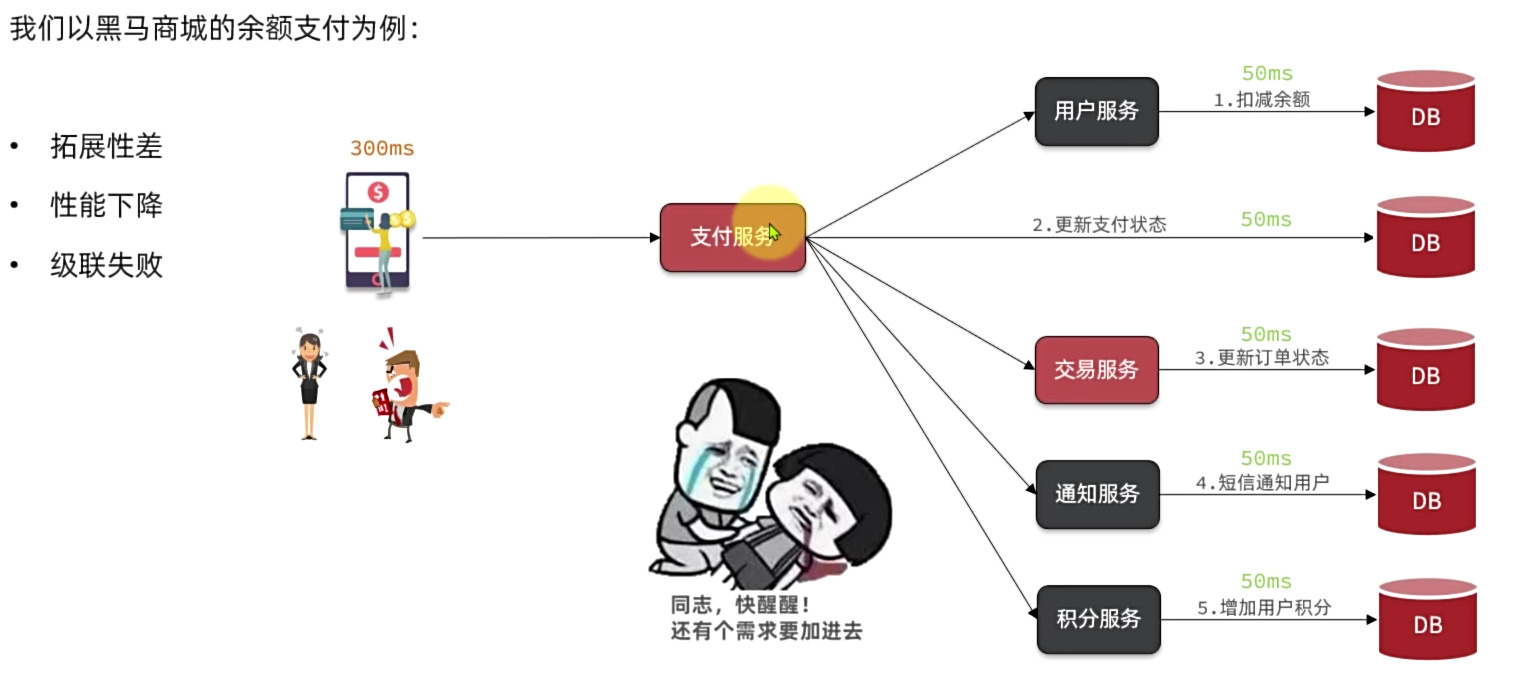
同步调用的优势是什么?
- 时效性强,等待到结果后才返回。
同步调用的问题是什么?
- 拓展性差
- 性能下降
- 级联失败问题
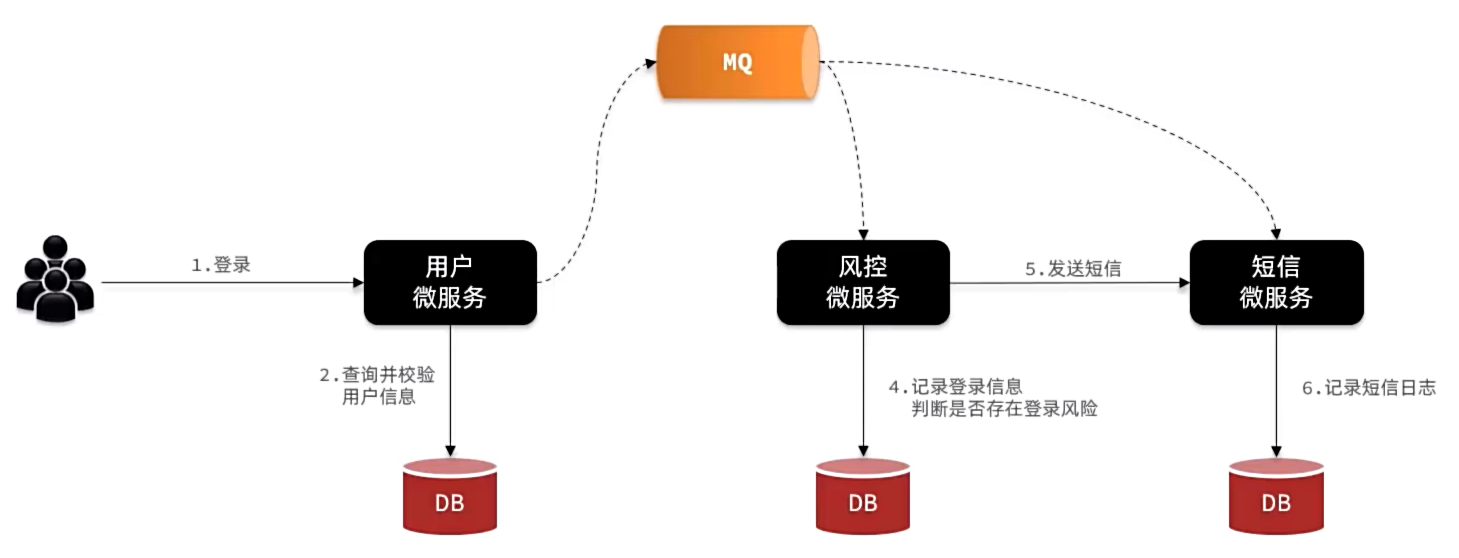
异步调用优缺点
(不需要考虑优先性的功能,可以采用异步)
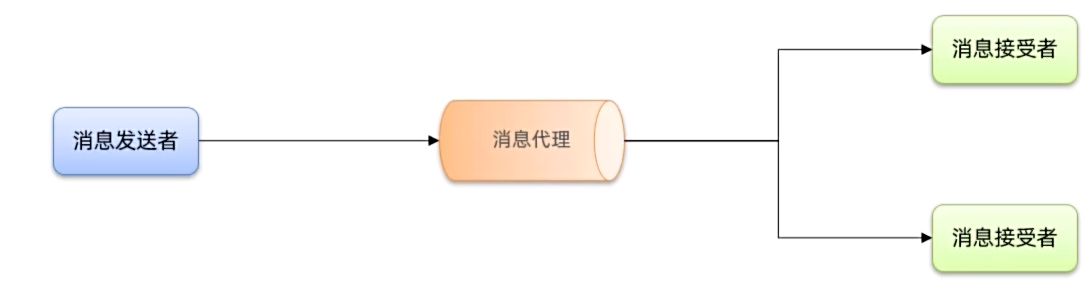
异步调用通常是基于消息通知的方式,包含三个角色:
消息发送者:投递消息的人,就是原来的调用者
消息接收者:接收和处理消息的人,就是原来的服务提供者
消息代理:管理、暂存、转发消息,你可以把它理解成微信服务器
支付服务不再同步调用业务关联度低的服务,而是发送消息通知到Broker。
具备下列优势:
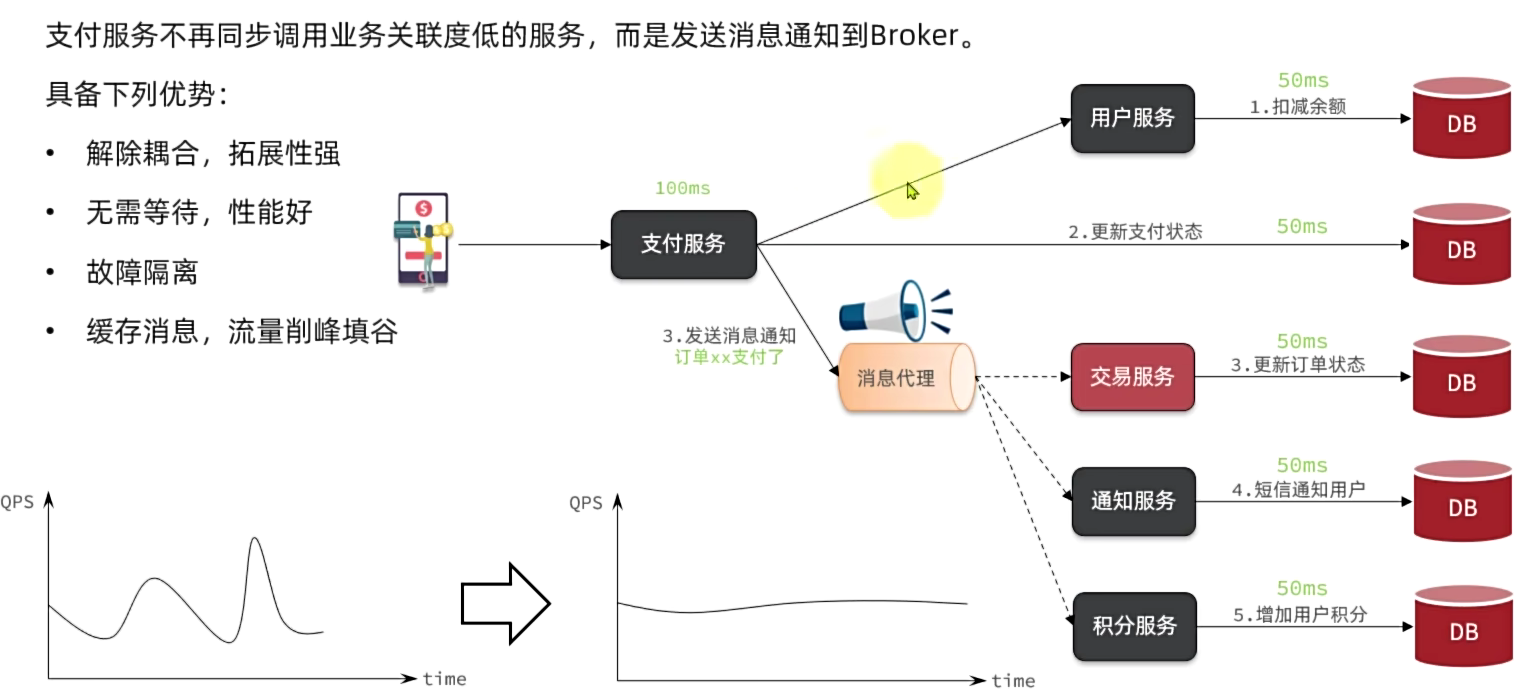
异调用的优势是什么?
- 耦合度低,拓展性强
- 异步调用,无需等待,性能好
- 故障隔离,下游服务故障不影响上游业务
- 缓存消息,流量削峰填谷
异步调用的问题是什么?
- 不能立即得到调用结果,时效性差
- 不确定下游业务执行是否成功
- 业务安全依赖于Broker的可靠性
MQ技术选型
MQ(MessageQueue),中文是消息队列,字面来看就是存放消息的队列。也就是异步调用中的Broker。
主流消息中间件对比表格
| 特征 | RabbitMQ | ActiveMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 公司/社区 | Rabbit | Apache | 阿里 | Apache |
| 开发语言 | Erlang | Java | Java | Scala&Java |
| 协议支持 | AMQP, XMPP, SMTP, STOMP | OpenWire, STOMP, REST, XMPP, AMQP | 自定义协议 | 自定义协议 |
| 可用性 | 高 | 一般 | 高 | 高 |
| 单机吞吐量 | 一般 | 差 | 高 | 非常高 |
| 消息延迟 | 微秒级 | 毫秒级 | 毫秒级 | 毫秒以内 |
| 消息可靠性 | 高 | 一般 | 高 | 一般 |
注意事项
- 强事务 & 高并发 → RocketMQ(优先学习)
- 大数据集成 → Kafka
- 轻量级 & 协议兼容 → RabbitMQ(优先学习)
RabbitMQ
RabbitMQ是基于Erlang语言开发的开源消息通信中间件,官网地址:
安装部署
1 | docker run \ |
可以看到在安装命令中有两个映射的端口:
- 15672:RabbitMQ提供的管理控制台的端口
- 5672:RabbitMQ的消息发送处理接口
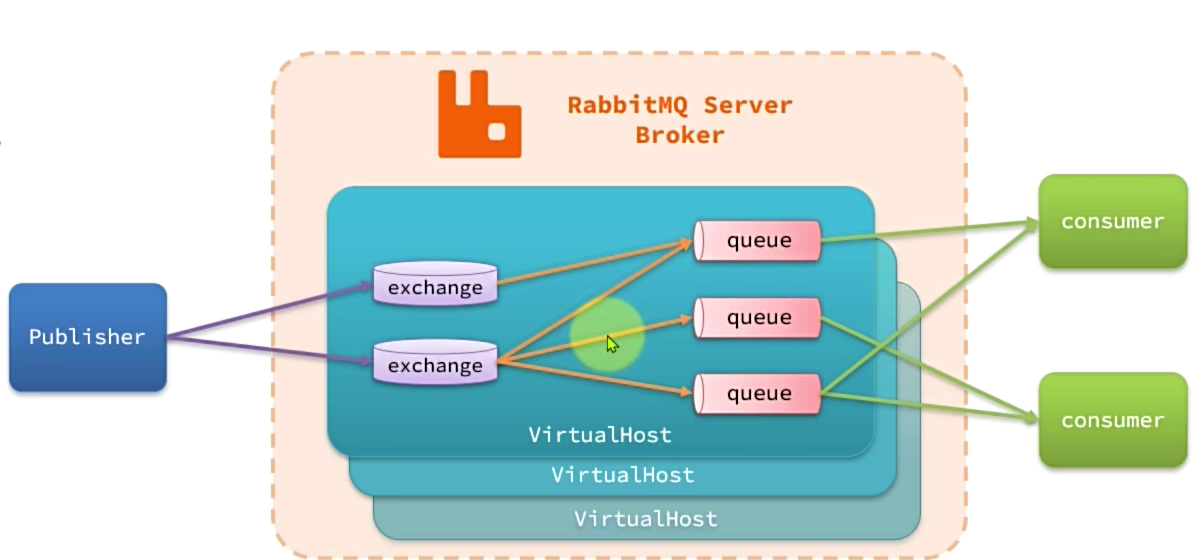
RabbitMQ的整体架构及核心概念:
virtual-host:虚拟主机,起到数据隔离的作用(类似于database)
publisher:消息发送者
consumer:消息的消费者
queue:队列,存储消息
exchange:交换机,负责路由消息
快速入门
需求:在RabbitMQ的控制台完成下列操作:
- 新建队列hello.queue1和hello.queue2
- 向默认的amp.fanout交换机发送一条消息
- 查看消息是否到达hello.queue1和hello.queue2
- 总结规律
注意事项
- 交换机只能路由消息,无法存储消息
- 交换机只会路由消息给与其绑定的队列,因此队列必须与交换机绑定
数据隔离
需求:在RabbitMQ的控制台完成下列操作:
- 新建一个用户hmall
- 为hmall用户创建一个virtualhost
- 测试不同virtualhost之间的数据隔离现象
Java客户端
快速入门
SpringAmqp的官方地址:hhttps://spring.io/projects/spring-amap
AMQP和SpringAMQP

需求如下(非正式):
- 利用控制台创建队列simple.queue
- 在publisher服务中,利用SpringAMQP直接向simple.queue发送消息
- 在consumer服务中,利用SpringAMQP编写消费者,监听simple.queue队列

步骤
1.引入spring-amqp依赖
在父工程中引入spring-amqp依赖,这样publisher和consumer服务都可以使用:
1 | <!--AMQP依赖,包含RabbitMQ--> |
2.配置RabbitMQ服务端信息
在每个微服务中引I入MQ服务端信息,这样微服务才能连接到RabbitMQ
1 | spring: |
3.发送消息
SpringAMQP提供了RabbitTemplate工具类,方便我们发送消息。发送消息代码如下:
1 |
|
4.接收消息
SpringAMQP提供声明式的消息监听,我们只需要通过注解在方法上声明要监听的队列名称,将来
SpringAMQP就会把消息传递给当前方法:
1 |
|
WorkQueues
Workqueues,任务模型。简单来说就是让多个消费者绑定到一个队列,共同消费队列中的消息。
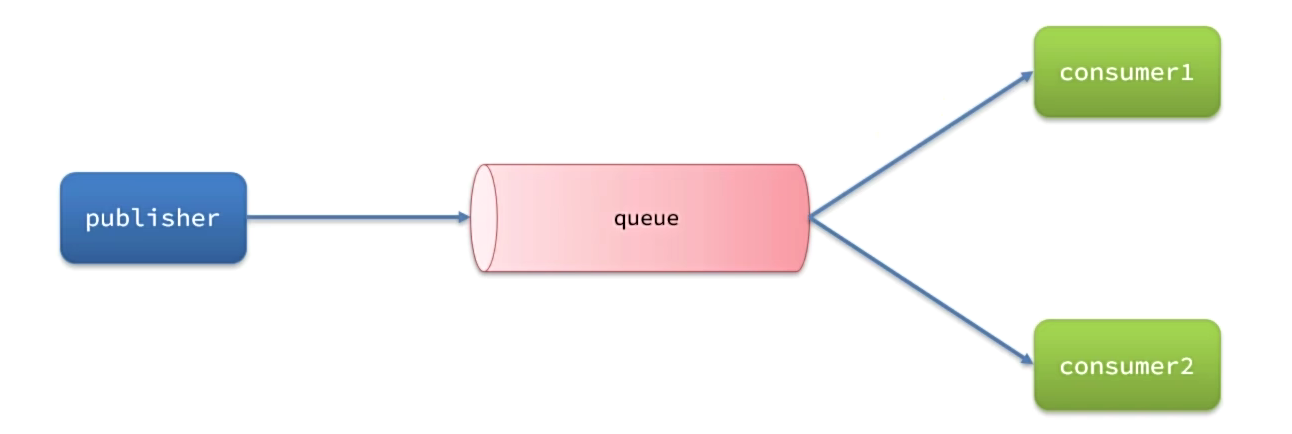
模拟WorkQueue,实现一个队列绑定多个消费者
基本思路如下:
- 在RabbitMQ的控制台创建一个队列,名为work.queue
- 在publisher服务中定义测试方法,发送50条消息到work.queue
- 在consumer服务中定义两个消息监听者,都监听work.queue队列
- 消费者1每秒处理40条消息,消费者2每秒处理5条消息
消费者消息推送限制
默认情况下,RabbitMQ的会将消息依次轮询投递给绑定在队列上的每一个消费者。但这并没有考虑到消费者是否已经处理完消息,可能出现消息堆积。
因此我们需要修改application.yml,设置preFetch值为1,确保同一时刻最多投递给消费者1条消息:
1 | spring: |
Work模型的使用:
- 多个消费者绑定到一个队列,可以加快消息处理速度
- 同一条消息只会被一个消费者处理
- 通过设置prefetch来控制消费者预取的消息数量,处理完一条再处理下一条,实现能者多劳
交换机
交换机的作用主要是接收发送者发送的消息,并将消息路由到与其绑定的队列。
常见交换机的类型有以下三种:
- Fanout:广播
- Direct:定向
- Topic:话题
交换机的作用是什么?
- 接收publisher发送的消息
- 将消息按照规则路由到与之绑定的队列
- FanoutExchange的会将消息路由到每个绑定的队列
Fanout交换机(广播)
FanoutExchange会将接收到的消息路由到每一个跟其绑定的queue,所以也叫广播模式
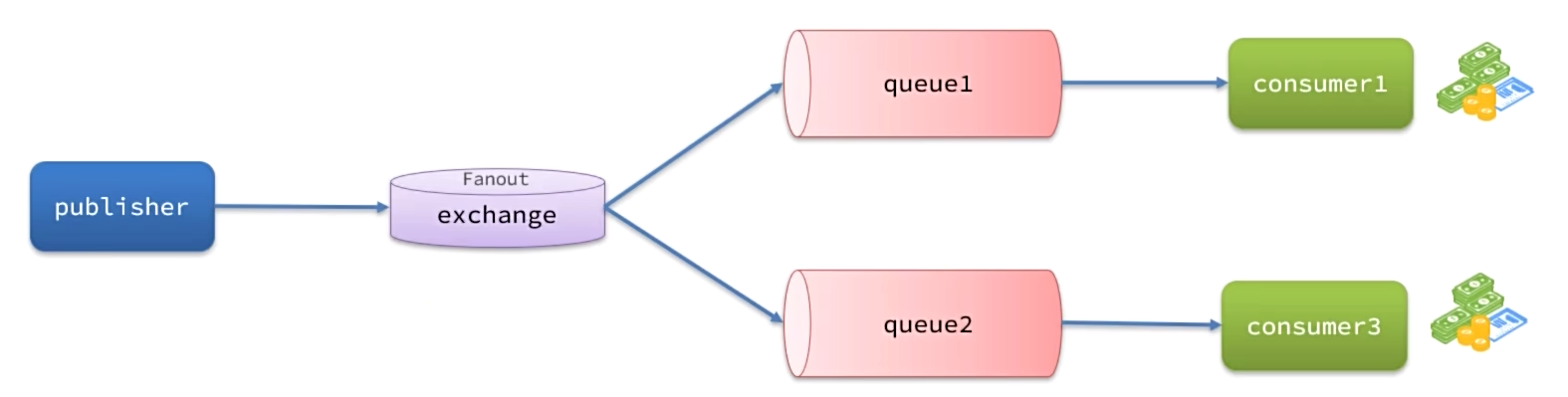
利用SpringAMQP演示FanoutExchange的使用
实现思路如下:
- 在RabbitMQ控制台中,声明队列fanout.queue1和fanout.queue2
- 在RabbitMQ控制台中,声明交换机hmall.fanout,将两个队列与其绑定
- 在consumer服务中,编写两个消费者方法,分别监听fanout.queue1和fanout.queue2
- 在publisher中编写测试方法,向hmall.fanout发送消息
1 |
|
Direct交换机(定向)(Fanout升级版)
DirectExchange会将接收到的消息根据规则路由到指定的Queue,因此称为定向路由。
- 每一个Queue都与Exchange设置一个BindingKey(对暗号)
- 发布者发送消息时,指定消息的RoutingKey
- Exchange将消息路由到BindingKey与消息RoutingKey一致的队列
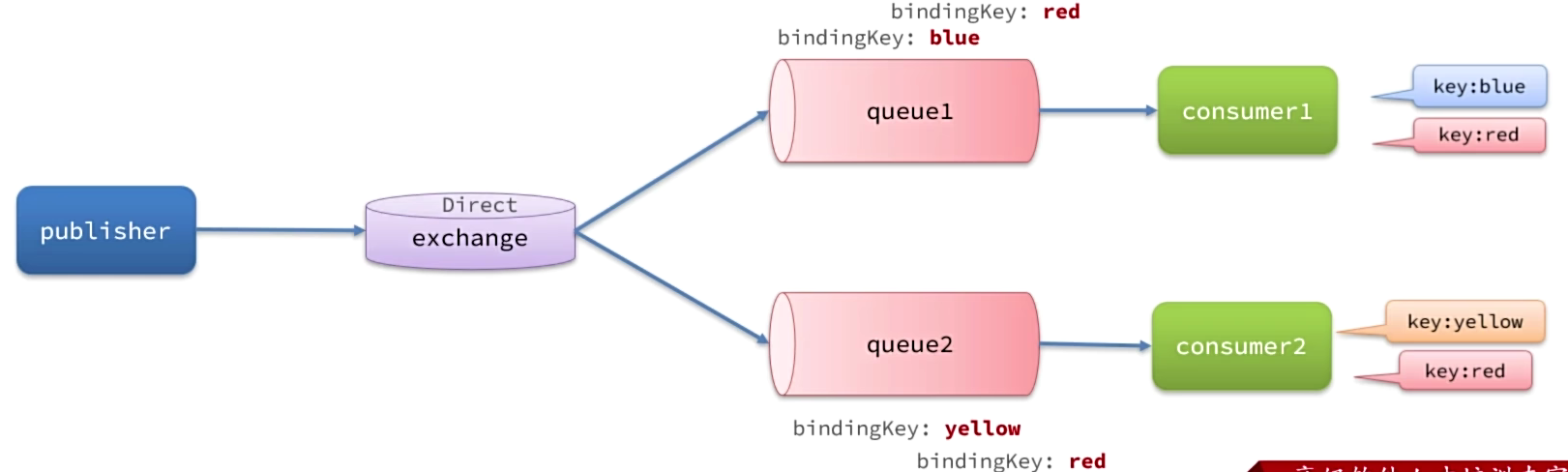
利用SpringAMQP演示DirectExchange的使用
- 在RabbitMQ控制台中,声明队列direct.queue1和direct.queue2
- 在RabbitMQ控制台中,声明交换机hmall.direct,将两个队列与其绑定
- 在consumer服务中,编写两个消费者方法,分别监听direct.queue1和direct.queue2
- 在publisher中编写测试方法,利用不同的RoutingKey向hmall.direct发送消息
1 |
|
描述下Direct交换机与Fanout交换机的差异?
- Fanout交换机将消息路由给每一个与之绑定的队列
- Direct交换机根据RoutingKey判断路由给哪个队列
- 如果多个队列具有相同RoutingKey,则与Fanout功能类似
Topic交换机(话题)
TopicExchange也是基于RoutingKey做消息路由,但是routingKey通常是多个单词的组合,并且以.分割。
Queue与Exchange指定BindingKey时可以使用通配符:
- #:代指0个或多个单词
- *:代指一个单词
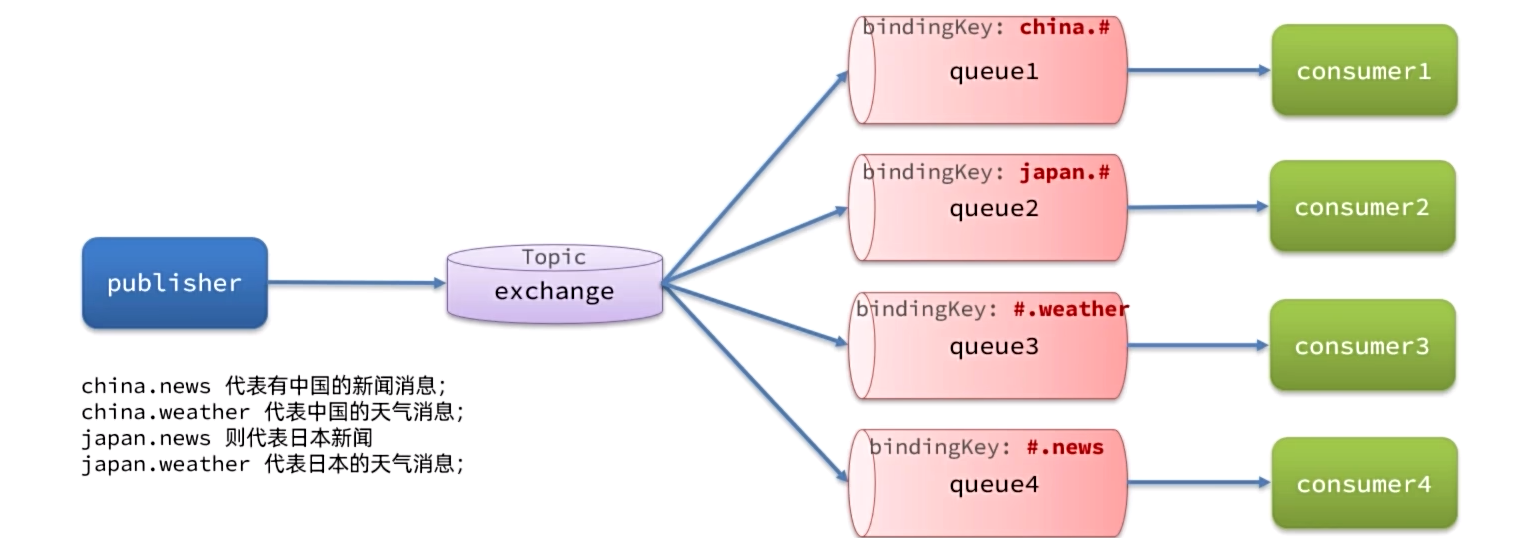
利用SpringAMQP演示DirectExchange的使用
需求如下:
- 在RabbitMQ控制台中,声明队列topic.queue1和topic.queue2
- 在RabbitMQ控制台中,声明交换机hmall.topic,将两个队列与其绑定
- 在consumer服务中,编写两个消费者方法,分别监听topic.queue1和topic.queue2
- 在publisher中编写测试方法,利用不同的RoutingKey向hmall.topic发送消息
1 |
|
描述下Topic交换机相比Direct交换机的差异?
- Topic的RoutingKey和bindingKey可以是多个单词,以.分割
- Topic交换机与队列绑定时的bindingKey可以指定通配符
- #:代表0个或多个词
- *:代表1个词
声明队列和交换机
SpringAMQP提供了几个类,用来声明队列、交换机及其绑定关系:
- Queue:用于声明队列,可以用工厂类QueueBuilder构建
- Exchange:用于声明交换机,可以用工厂类ExchangeBuilder构建
- Binding:用于声明队列和交换机的绑定关系,可以用工厂类BindingBuilder构建
基于Bean声明队列交换机
例如,声明一个Fanout类型的交换机,并且创建队列与其绑定:
1 |
|
基于注解声明队列交换机
利用SpringAMQP声明DirectExchange并与队列绑定
需求如下:
- 在consumer服务中,声明队列direct.queue1和direct.queue2
- 在consumer服务中,声明交换机hmall.direct,将两个队列与其绑定
- 在consumer服务中,编写两个消费者方法,分别监听direct.queue1和direct.queue2
SpringAMQP还提供了基于@RabbitListener注解来声明队列和交换机的方式:
1 |
|
消息转换器(默认JDK序列化)
需求:测试利用SpringAMQP发送对象类型的消息
- 声明一个队列,名为object.queue
- 编写单元测试,向队列中直接发送一条消息,消息类型为Map
- 在控制台查看消息,总结你能发现的问题
1 | //准备消息 |
Spring的对消息对象的处理是由org.springframework.amqp.support.converter.MessageConverter来处理的。而默认实现是SimpleMessageConverter,基于JDK的objectOutputStream完成序列化。
存在下列问题:
- JDK的序列化有安全风险
- JDK序列化的消息太大
- JDK序列化的消息可读性差
建议采用JSON序列化代替默认的JDK序列化,号要做两件事情:
在publisher和consumer中都要引入jackson依赖:
1 | <dependency> |
在publisher和consumer中都要配置MessageConverter:
1 |
|
业务改造
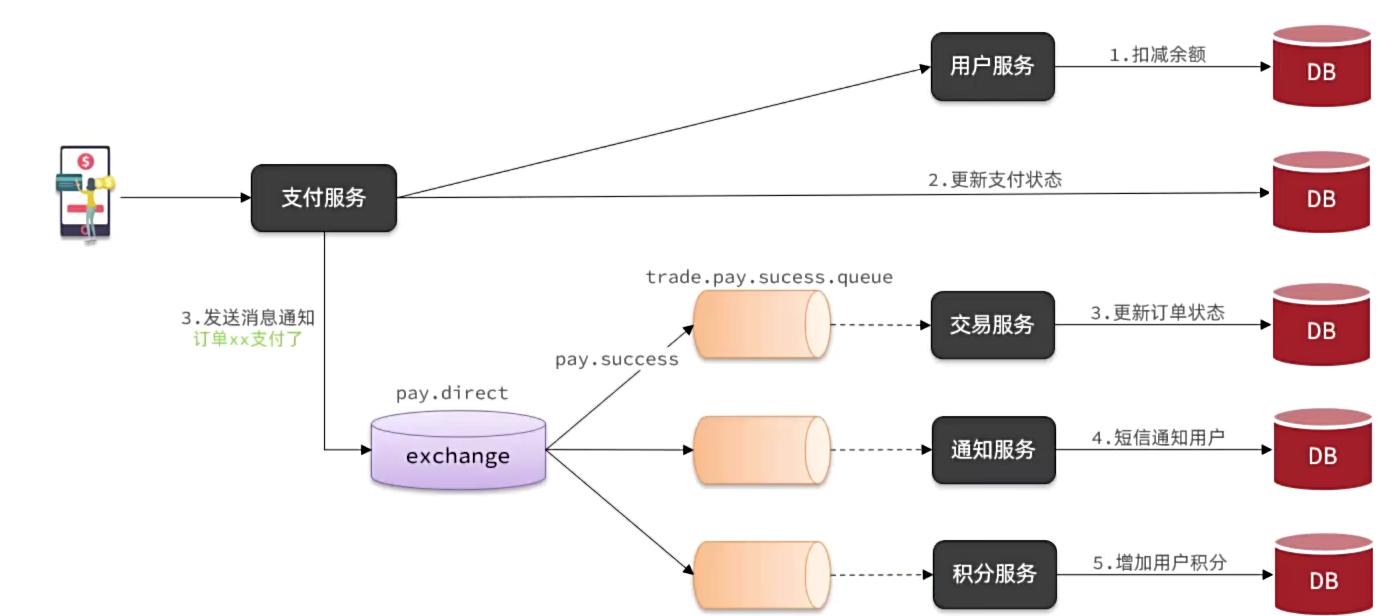
需求:改造余额支付功能,不再同步调用交易服务的OpenFeign接口,而是采用异步MQ通知交易服务更新订单状态
MQ高级
消息可靠性问题
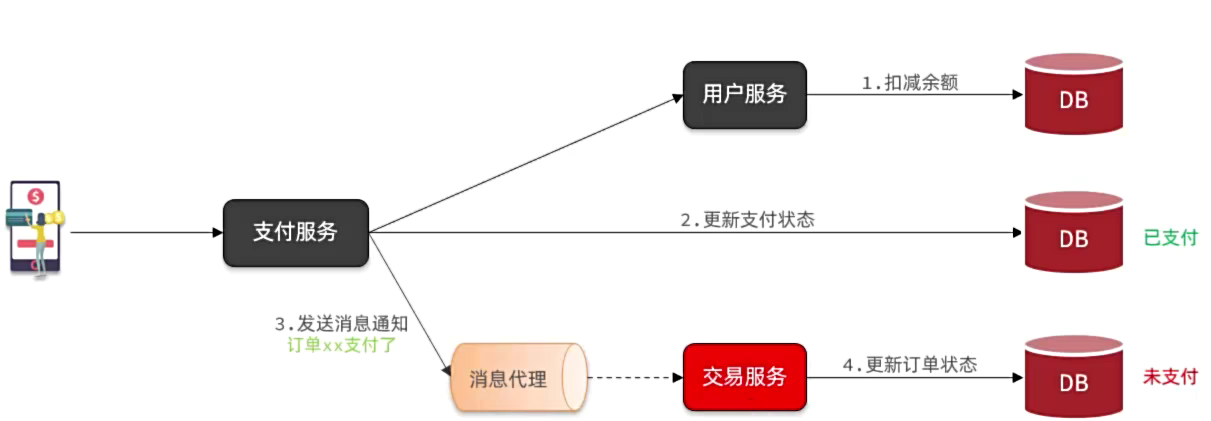
发送者可靠性
发送者重连
有的时候由于网络波动,可能会出现发送者连接MQ失败的情况。通过配置我们可以开启连接失败后的重连机制:
1 | spring: |
注意
当网络不稳定的时候,利用重试机制可以有效提高消息发送的成功率。不过SpringAMQP提供的重试机制是阻塞式的重试,也就是说多次重试等待的过程中,当前线程是被阻塞的,会影响业务性能。
如果对于业务性能有要求,建议禁用重试机制。如果一定要使用,请合理配置等待时长和重试次数,当然也可以考虑使用异步线程来执行发送消息的代码。
发送者确认机制
SpringAMQP提供了PublisherConfirm和PublisherReturn两种确认机制。开启确机制认后,当发送者发送消息给MQ后,MQ会返回确认结果给发送者。返回的结果有以下几种情况:
消息投递到了MQ,但是路由失败。此时会通过PublisherReturn返回路由异常原因,然后返回AcK,告知投递成功
临时消息投递到了MQ,并且入队成功,返回ACK,告知投递成功
持久消息投递到了MQ,并且入队完成持久化,返回ACK,告知投递成功
其它情况都会返回NACK,告知投递失败
SpringAMQP实现发送者确认
1.在publisher这个微服务的application.yml中添加配置:
1 | spring: |
配置说明:
这里publisher-confirm-type有三种模式可选:
- none:关闭confirm机制
- simple:同步阻塞等待MQ的回执消息
- coKrelated:MQ异步回调方式返回回执消息
2.每个RabbitTemplate只能配置一个ReturnCallback,因此需要在项目启动过程中配置:
1 |
|
3.发送消息,指定消息iD、消息ConfirmCallback
1 |
|
注意一般不会开启,因为影响效率
MQ可靠性
在默认情况下,RabbitMQ会将接收到的信息保存在内存中以降低消息收发的延迟。这样会导致两个问题:
- 一旦MQ岩机,内存中的消息会丢失
- 内存空间有限,,当消费者故障或处理过慢时,会导致消息积压,引发MQ阻塞
数据持久化
RabbitMQ实现数据持久化包括3个方面:
- 交换机持久化(初设置时为默认)
- 队列持久化(初设置时为默认)
- 消息持久化

- 信息持久化远远比信息非持久化要快
- Spring的代码默认信息持久化
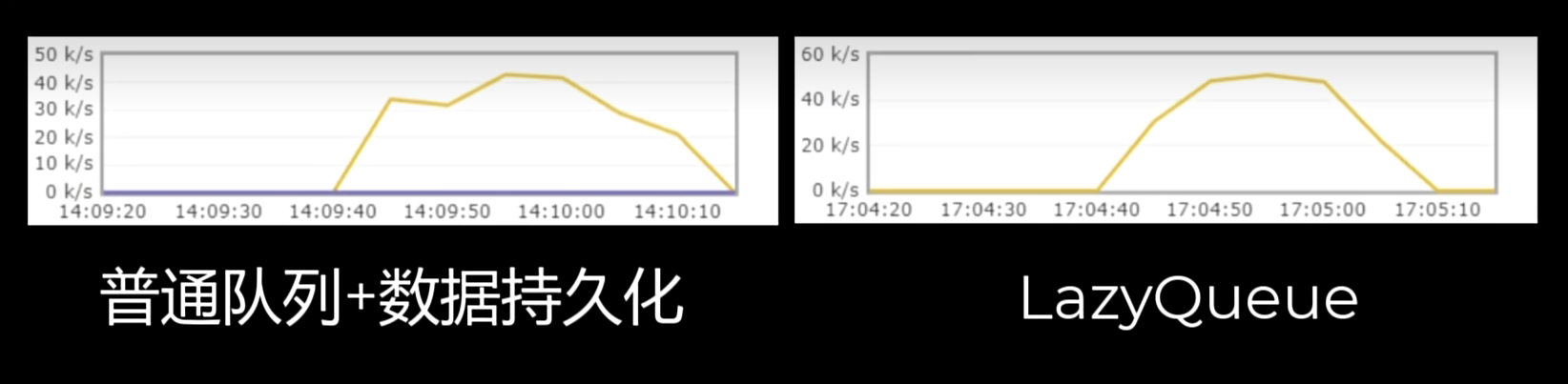
LazyQueue
从RabbitMQ的3.6.0版本开始,就增加了LazyQueue的概念,也就是惰性队列。
惰性队列的特征如下:
- 接收到消息后直接存入磁盘,不再存储到内存
- 消费者要消费消息时才会从磁盘中读取并加载到内存(可以提前缓存部分消息到内存,最多2048条)
在3.12版本后,所有队列都是LazyQueue模式,无法更改。
要设置一个队列为惰性队列,只需要在声明队列时,指定x-queue-mode属性为lazy即可:
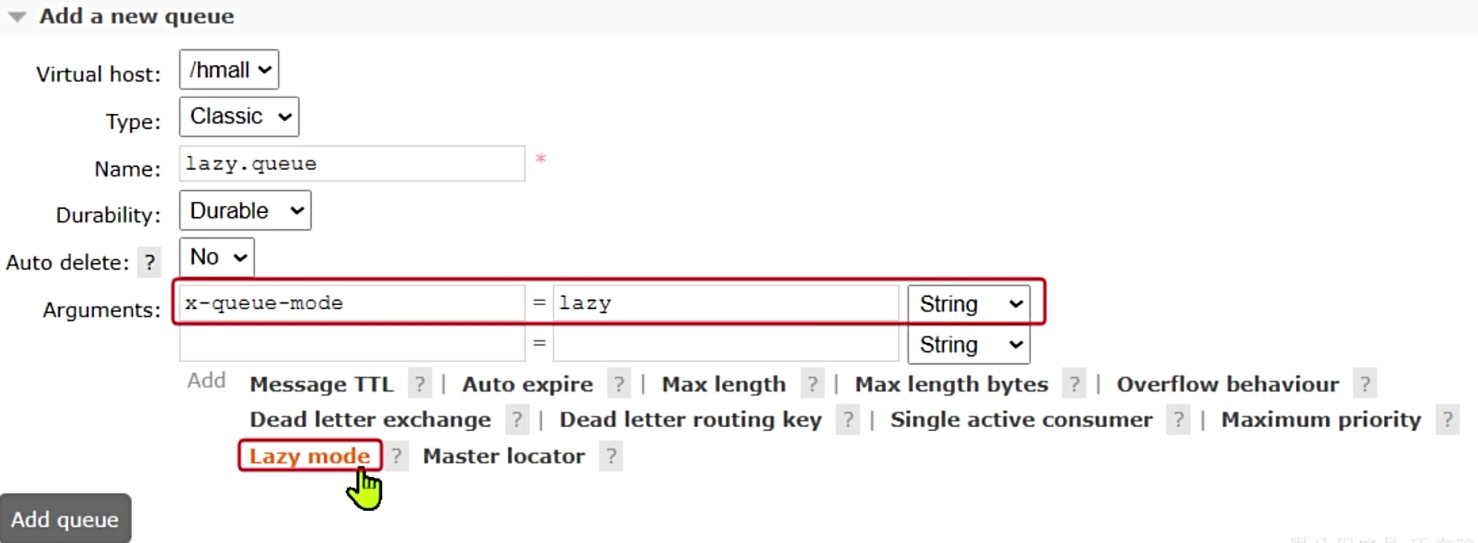
1 |
|
1 |
|
RabbitMQ如何保证消息的可靠性
- 首先通过配置可以让交换机、队列、以及发送的消息都持久化。这样队列中的消息会持久化到磁盘,MQ重启消息依然存在。
- RabbitMQ在3.6版本引l入了LazyQueue,并且在3.12版本后会称为队列的默认模式。LazyQueue会将所有消息都持久化。
- 开启持久化和生产者确认时,RabbitMQ只有在消息持久化完成后才会给生产者返回ACK回执
消费者可靠性
消费者确认机制(ConsumerAcknowledgement)是为了确认消费者是否成功处理消息。当消费者处理消息结束后,应该向RabbitMQ发送一个回执,告知RabbitMQ自己消息处理状态:
- ack:成功处理消息,RabbitMQ从队列中删除该消息
- nack:消息处理失败,RabbitMQ需要再次投递消息
- reject:消息处理失败并拒绝该消息,RabbitMQ从队列中删除该消息
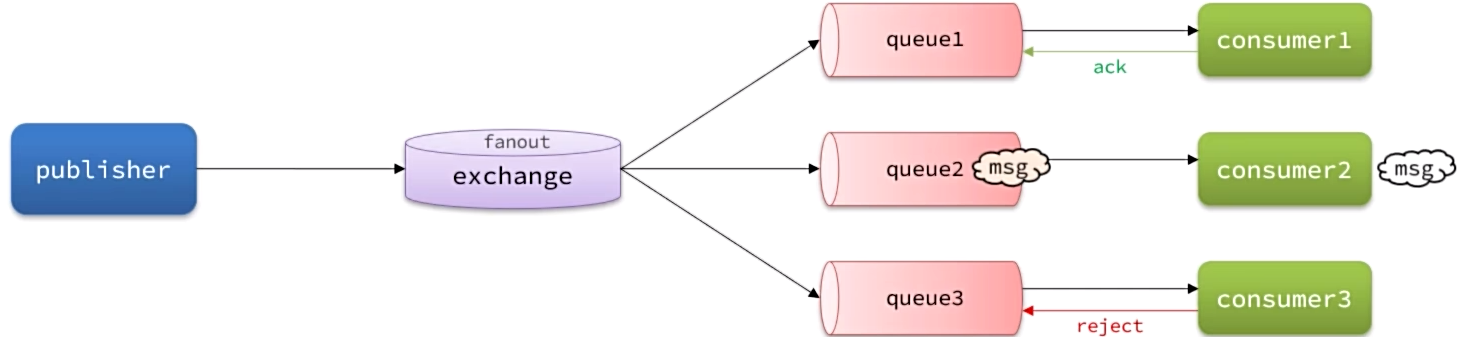
消费者确认机制
SpringAMQP已经实现了消息确认功能。并允许我们通过配置文件选择ACK处理方式,有三种方式:
- none不处理。即消息投递给消费者后立刻ack,消息会立刻从MQ删除。非常不安全,不建议使用
- manual:手动模式。需要自己在业务代码中发送ack或reject,存在业务入侵,但更灵活
- auto:自动模式。SpringAMQP利用AO息处理逻辑做了环绕增强,当业务正常执行时则自动返回ack
当业务出现异常时,根据异常判断返回不同结果:
- 如果是业务异常,会自动返回nack
- 如果是消息处理或校验异常,自动返回reject
1 | spring: |
消费者失败重试策略
SpringAMQP提供了消费者失败重试机制,在消费者出现异常时利用本地重试,而不是无限的requeue到mq。我们可以通过在application.yaml文件中添加配置来开启重试机制:
1 | #这个是消费者的重试策略 |
在开启重试模式后,重试次数耗尽,如果消息依然失败,则需要有MessageRecoverer接口来处理,它包含三种不同的实现:
- RejectAndDontRequeueRecoverer:重试耗尽后,直接reject,丢弃消息。默认就是这种方式
- ImmediateRequeueMessageRecoverer:重试耗尽后,返回nack,消息重新入队(虽然还是踢皮球,但是频率不高)
- RepublishMessageRecoverer:重试耗尽后,将失败消息投递到指定的交换机(死信交换机)
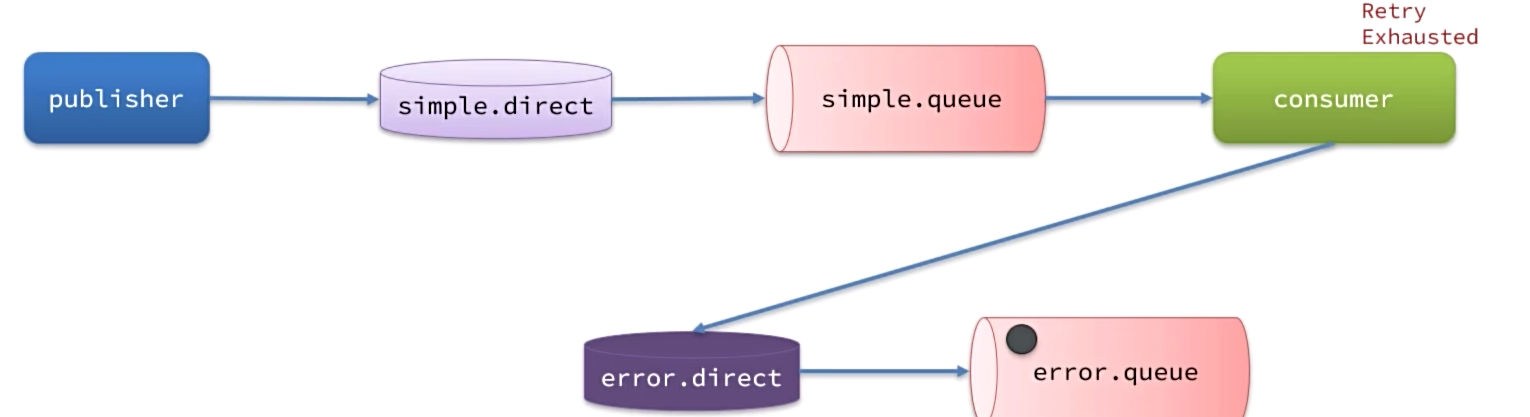
将失败处理策略改为RepublishMessageRecoverer:
- 首先,定义接收失败消息的交换机、队列及其绑定关系,此处略:
- 然后,定义RepublishMesSageRecoverer:
1 |
|
1 |
|
使用之后,在信息中会携带异常信息(报错)
业务幂等处理
幂等是一个数学概念,用函数表达式来描述是这样的:f(x)=f(f(x))。在程序开发中,则是指同一个业务,执行一次或多次对业务状态的影响是一致的。

唯一消息id
方案一,是给每个消息都设置一个唯一id,利用id区分是否是重复消息:
- 每一条消息都生成一个唯一的id,与消息一起投递给消费者。
- 消费者接收到消息后处理自己的业务,业务处理成功后将消息ID保存到数据库
- 如果下次又收到相同消息,去数据库查询判断是否存在,存在则为重复消息放弃处理,
1 |
|
不推荐,影响性能,有业务侵入
业务判断
方案二,是结合业务逻辑,,基于业务本身做判断。以我们的余额支付业务为例:
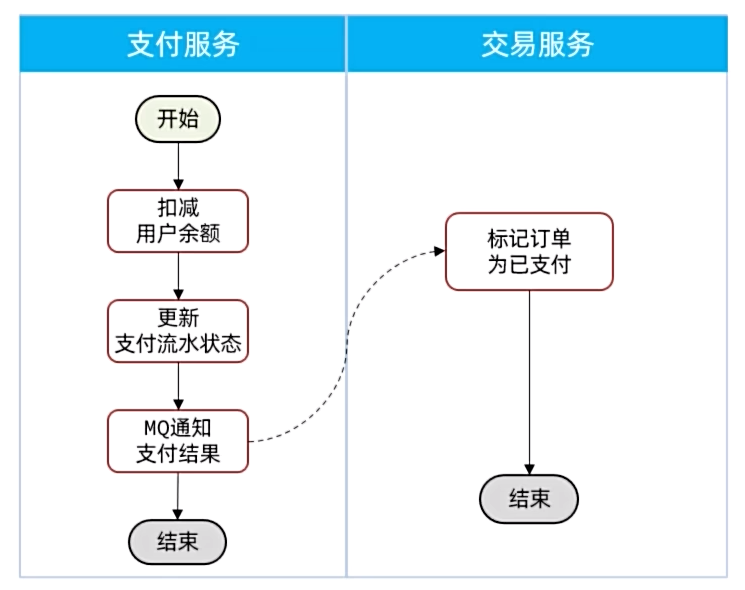
改进事务
1 |
|
如何保证支付服务与交易服务之间的订单状态一致性?
- 首先,支付服务会正在用户支付成功以后利用MQ消息通知交易服务,完成订单状态同步。
- 其次,为了保证MQ消息的可靠性,我们采用了生产者确认机制、消费者确认、消费者失败重试等策略,确保消息投递和处理的可靠性。同时也开启了MQ的持久化,避免因服务岩机导致消息丢失。
- 最后,我们还在交易服务更新订单状态时做了业务幂等判断,避免因消息重复消费导致订单状态异常。
如果交易服务消息处理失败,有没有什么兜底方案?
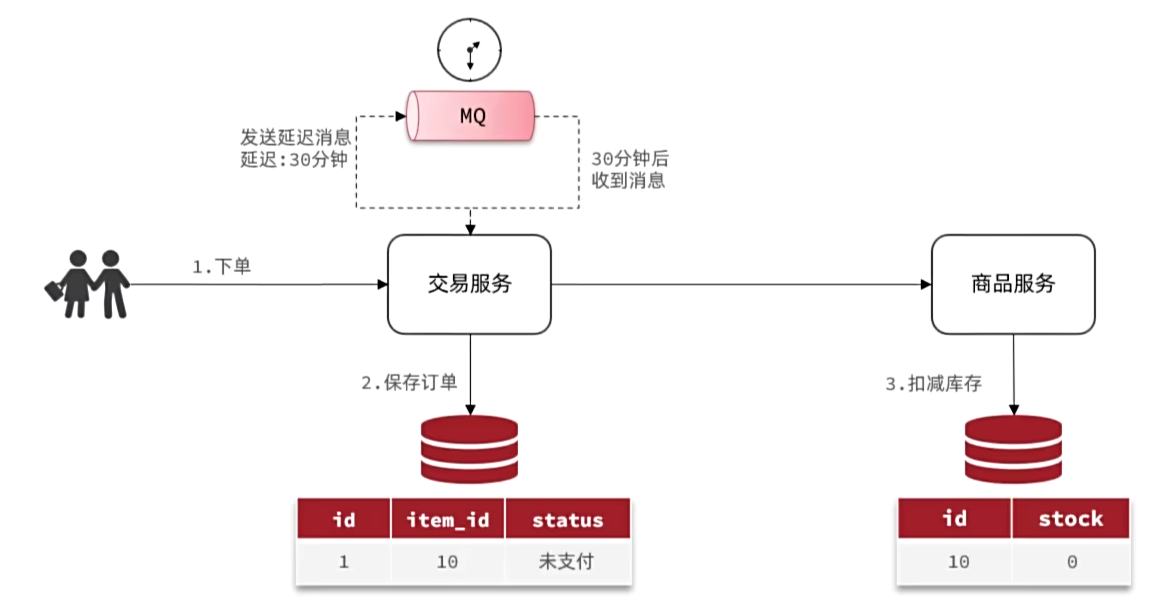
延迟消息
什么是延迟消息
延迟消息:发送者发送消息时指定一个时间,消费者不会立刻收到消息,而是在指定时间之后才收到消息。
延迟任务:设置在一定时间之后才执行的任务
死信交换机
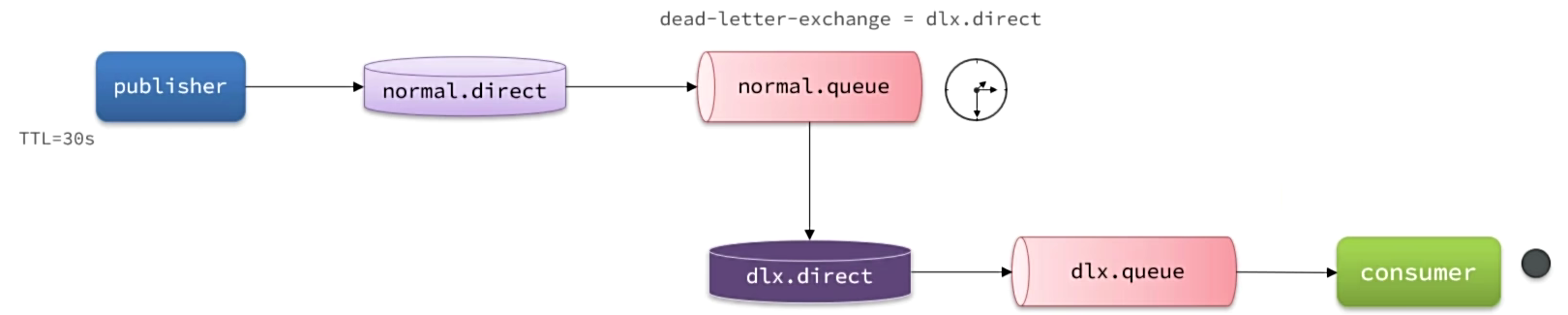
当一个队列中的消息满足下列情况之一时,就会成为死信(deadletter):
- 消费者使用basic.reject或basic.nack声明消费失败,并且消息的requeue参数设置为false
- 消息是一个过期消息(达到了队列或消息本身设置的过期时间),超时无人消费
- 要投递的队列消息堆积满了,最早的消息可能成为死信
如果队列通过dead-letter-exchange属性指定了一个交换机,那么该队列中的死信就会投递到这个交换机中。这个交换机称为死信交换机(DeadLetter Exchange,简称DLX)。
延迟消息插件
这个插件可以将普通交换机改造为支持延迟消息功能的交换机,当消息投递到交换机后可以暂存一定时间,到期后再投递到队列。

下载插件
在官网下载.ez包
安装
因为我们是基于Docker安装,所以需要先查看RabbitMQ的插件目录对应的数据卷。
1 | docker volume inspect mq-plugins |
结果如下:
1 | [ |
插件目录被挂载到了/var/lib/docker/volumes/mq-plugins/_data这个目录,我们上传插件到该目录下。
接下来执行命令,安装插件:
1 | docker exec -it mq rabbitmq-plugins enable rabbitmq_delayed_message_exchange |
运行结果如下:
1 | [root@localhost _data]# docker exec -it mq rabbitmq-plugins enable rabbitmq_delayed_message_exchange |
声明延迟交换机
这个插件可以将普通交换机改造为支持延迟消息功能的交换机,当消息投递到交换机后可以暂存一定时间,到期后再投递到队列。

**延迟时间不要过长,过长会导致CPU占用过高。**15秒以下
基于注解方式(delayed = “true”):
1 |
|
发送消息时需要通过消息头x-delay来设置过期时间:
1 |
|
取消超时订单
用户下单完成后,发送15分钟延迟消息,在15分钟后接收消息,检查支付状态:
- 已支付:更新订单状态为已支付
- 未支付:更新订单状态为关闭订单,恢复商品库存
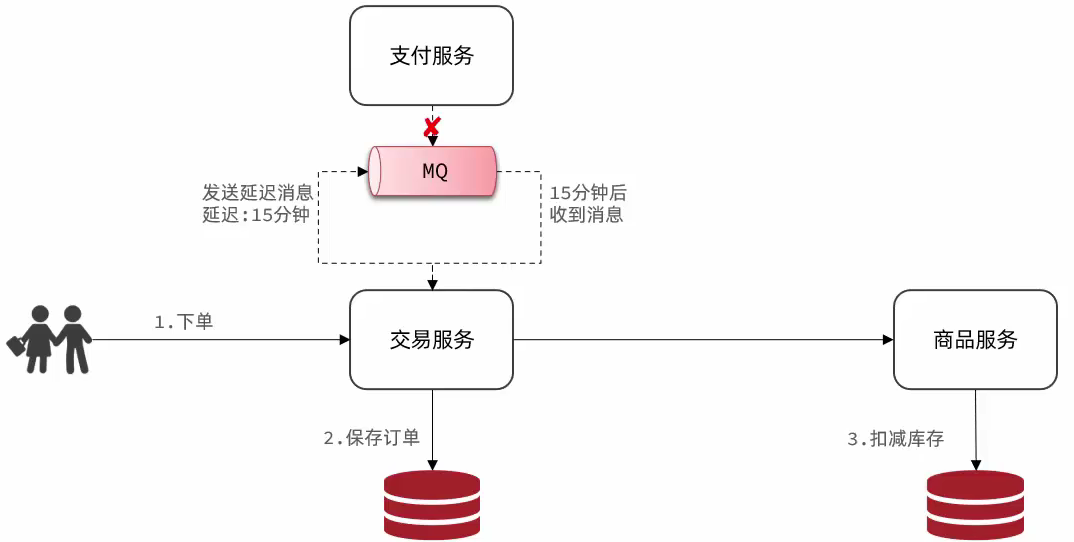
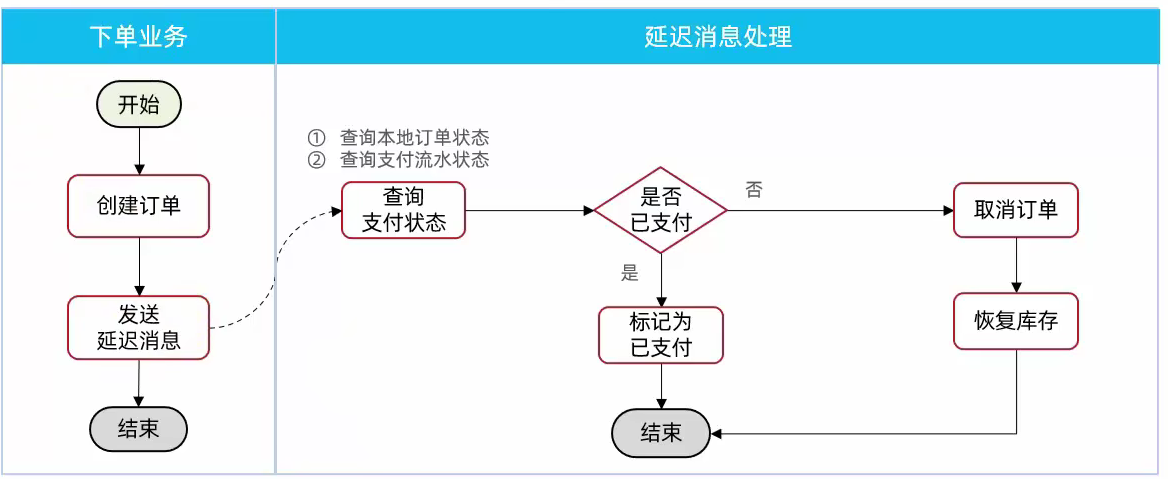
由于MQ消息处理时需要查询支付状态,因此我们要在pay-service模块定义一个这样的接口,并提供对应的FeignClient.
首先,在hm-api模块定义三个类:
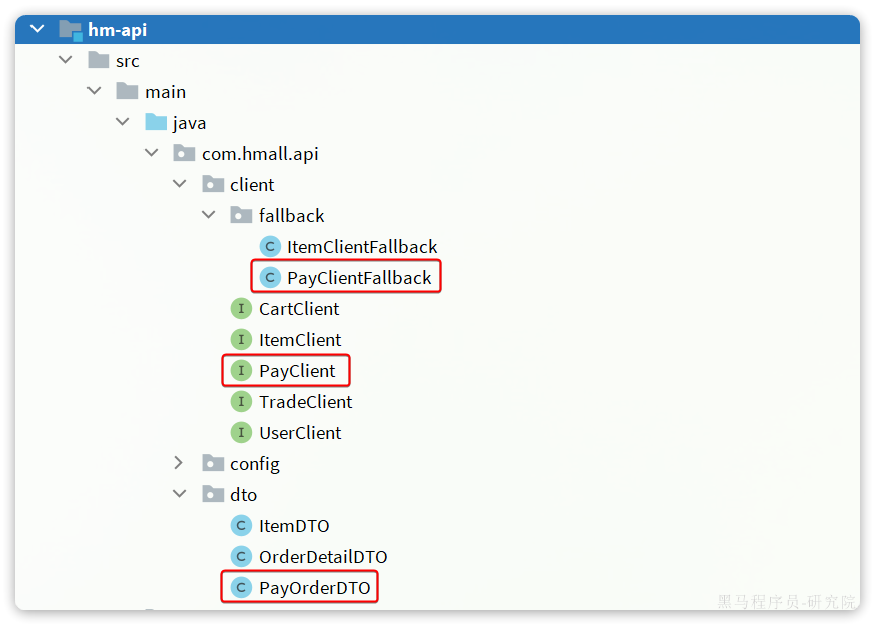
说明:
- PayOrderDTO:支付单的数据传输实体
- PayClient:支付系统的Feign客户端
- PayClientFallback:支付系统的fallback逻辑
PayOrderDTO代码如下:
1 | package com.hmall.api.dto; |
PayClient代码如下:
1 | package com.hmall.api.client; |
PayClientFallback代码如下:
1 | package com.hmall.api.client.fallback; |
注册Bean
1 | public class DefaultFeignConfig { |
最后,在pay-service模块的PayController中实现该接口:
1 |
|
Elasticsearch
数据库模糊搜索的性能不太好,高性能分布式搜索引擎
搜索引掌擎技术它的应用的场景非常广泛
初识ES
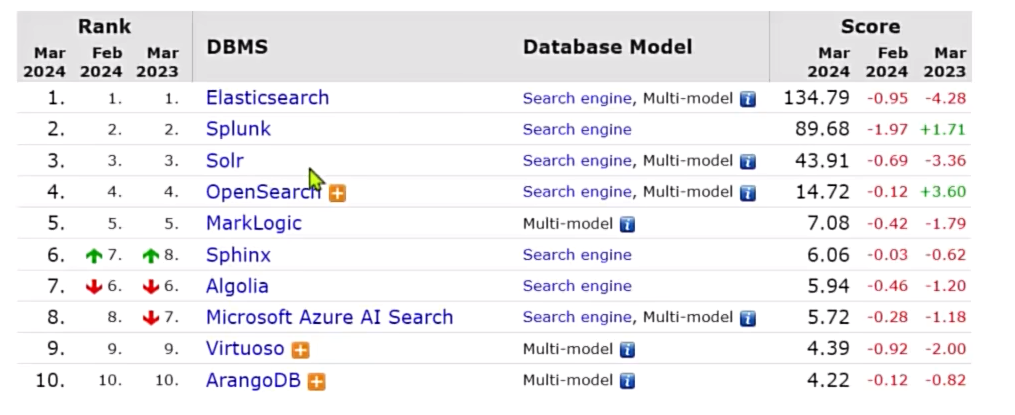
为什么学习elasticsearch
搜索引擎技术排名:
Elasticsearch:开源的分布式搜索引擎
Splunk:商业项目
Solr:Apache的开源搜索引擎
认识和安装ES
Lucene是一个Java语言的搜索引擎类库,是Apache公司的顶级项目,由DougCutting于1999年研发。官网地址:https://lucene.apache.org/
Lucene的优势:
- 易扩展
- 高性能(基于倒排索引)
2004年ShayBanon基于Lucene开发了Compass
2010年ShayBanon重写了Compas,取名为Elasticsearch。
官网地址:https://www.elastic.co/cn/,目前最新的版本是:8.X.X
elasticsearch具备下列优势:
- 支持分布式,可水平扩展
- 提供Restful接口,可被任何语言调用
企业现在一般使用多少版本
- 7.10(云兼容性及稳定性)
- 8.5/8.9/8.13(性能优化与功能扩展)
- 8.15/8.17(AI与向量搜索需求)
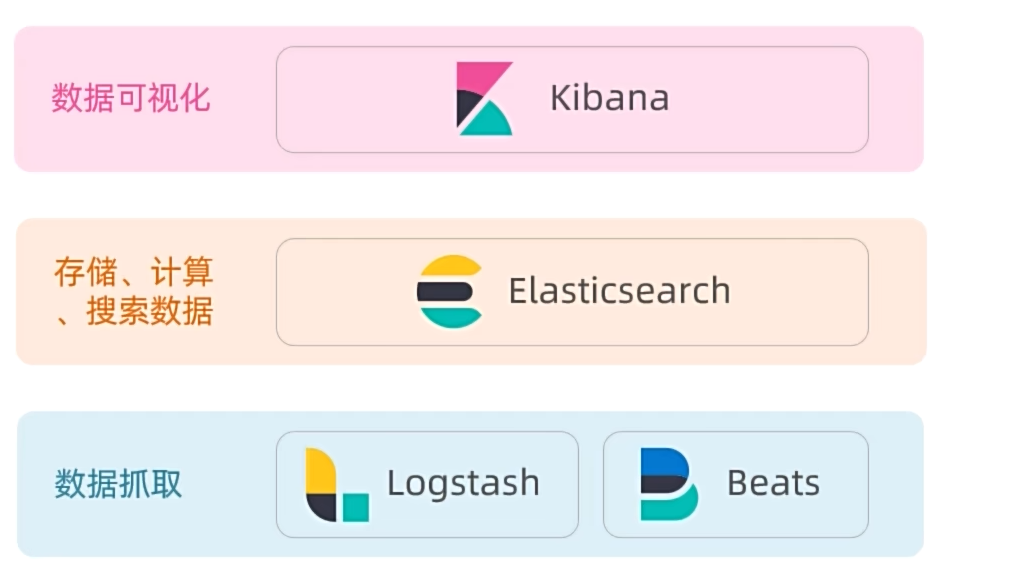
elasticsearch结合kibana、Logstash、Beats,是一整套技术栈,被叫做ELK。被广泛应用在日志数据分析、实时监控等领域。
一般只关注两部分
- elasticsearch:存储、搜索和运算
- kibana:图形化展示(只是用来操作)
安装elasticsearch
通过下面的Docker命令即可安装单机版本的elasticsearch:
1 | docker run -d \ |
上传安装包

1 | docker load -i es.tar |
安装Kibana
通过下面的Docker命令,即可部署Kibana:
1 | docker run -d \ |
倒排索引
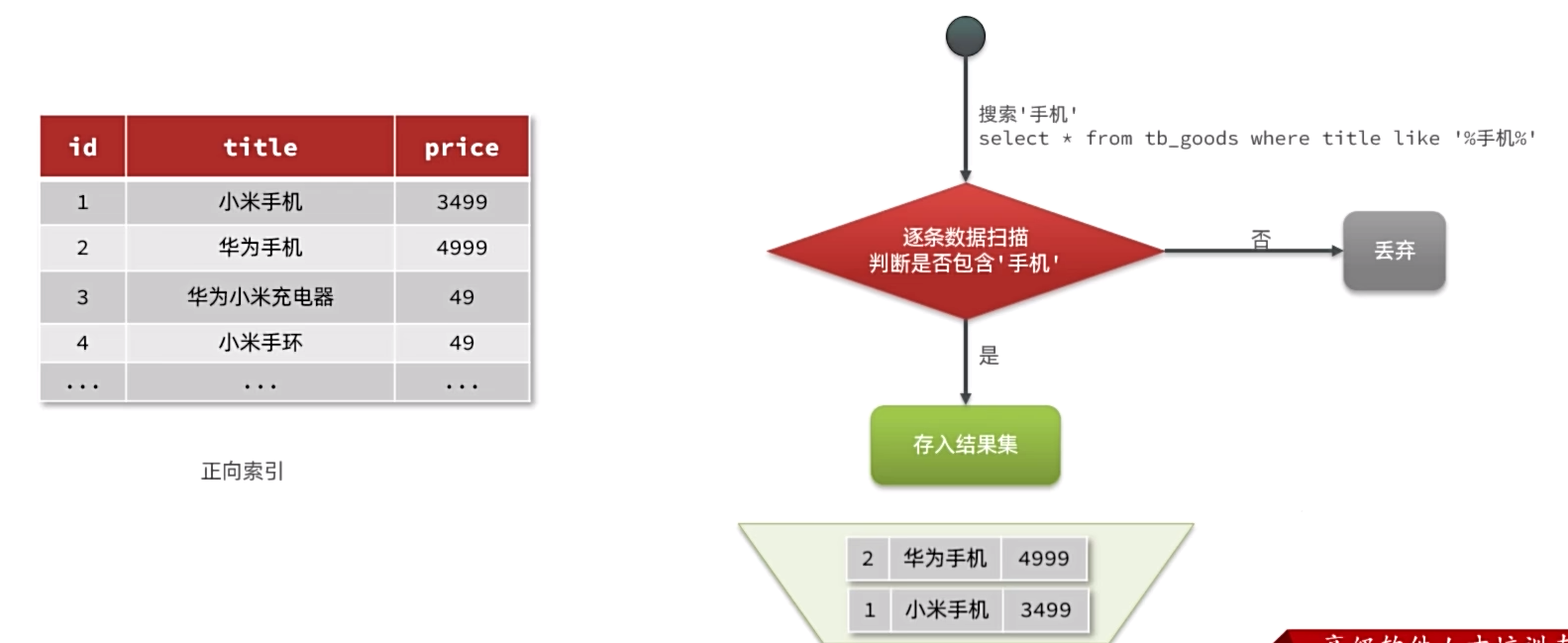
传统数据库(如MySQL)采用正向索引l,例如给下表(tb_goods)中的id创建索引:
elasticsearch采用倒排索引:
- 文档(document):每条数据就是一个文档
- 词条(term):文档按照语义分成的词语

正向索引:
基于文档id创建索引。根据id查询快,但是查询词条时必须先找到文档,而后判断是否包含词条
倒排索引:
对文档内容分词,对词条创建索引,并记录词条所在文档的id。查询时先根据词条查询到文档id,而后根据文档id查询文档
IK分词器(中文分词器)
中文分词往往需要根据语义分析,比较复杂,这就需要用到中文分词器,例如IK分词器。IK分词器是林良益在2006年开源发布的,其采用的正向迭代最细粒度切分算法一直沿用至今。
安装包在github,要安装对应版本
其安装的方式也比较简单,只要将分词器放入elasticsearch的插件目录即可:
在Kibana的DevTools中可以使用下面的语法来测试Ik分词器:
1 | POST /_analyze |
语法说明:
POST:请求方式
/_analyze:请求路径,这里省略了http://192.168.149.128:9200,有kibana帮我们补充
请求参数,json风格:
- analyzer:分词器类型,这里是默认的standard分词器
- text:要分词的内容
原理:内置了一个词典,不支持新的词汇
IK分词器允许我们配置拓展词典来增加自定义的词库:
1 |
|
停止词典是指要去掉的词
分词器的作用是什么?
- 创建倒排索引时,对文档分词
- 用户搜索时,对输入的内容分词
IK分词器有几种模式?
- ik_smart:智能切分,粗粒度
- ik_max_word:最细切分,细粒度lk分词器
如何拓展分词器词库中的词条?
- 利用config目录的ikAnalyzer.cfg.xml文件添加拓展词典
- 在词典中添加拓展词条
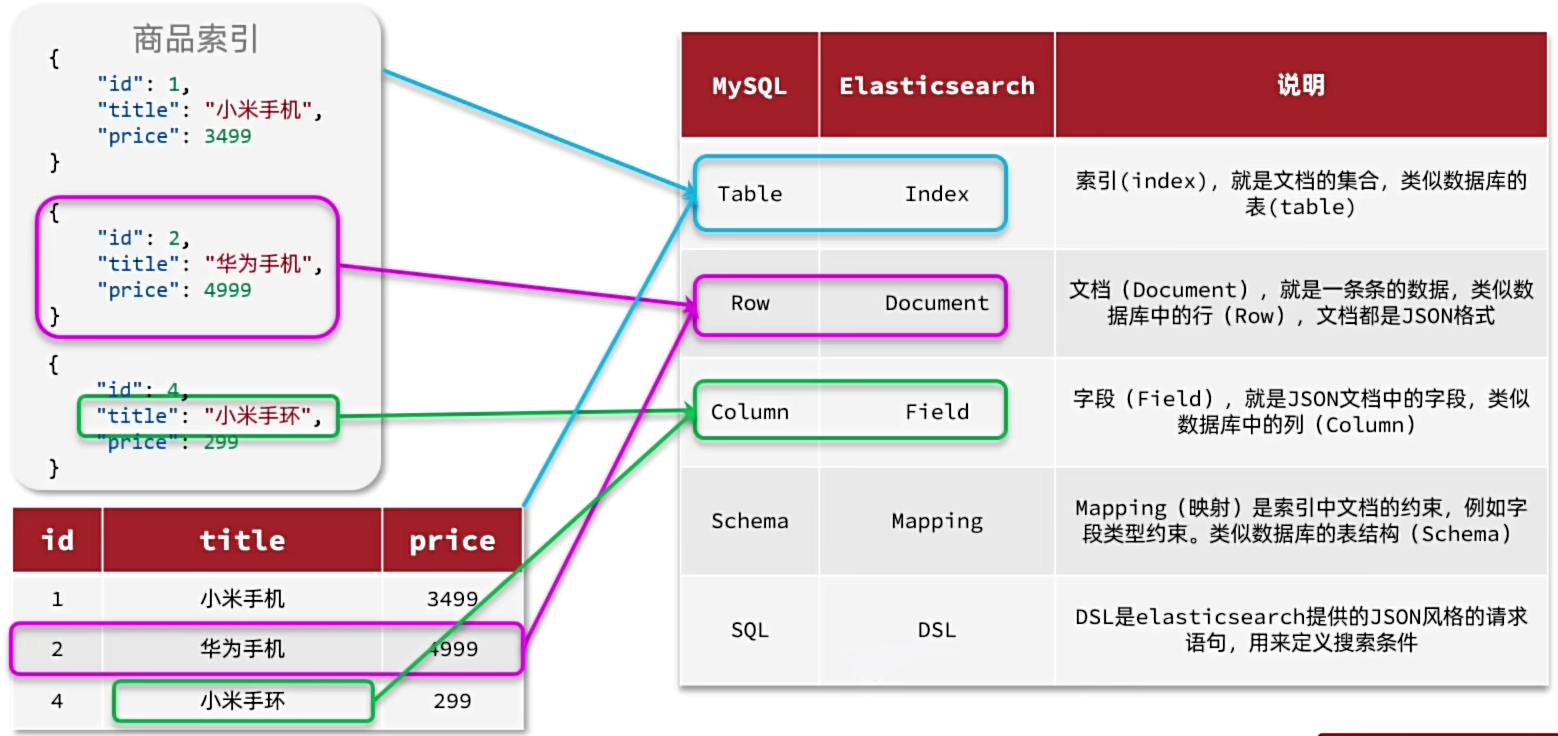
基本概念
elasticsearch中的文档数据会被序列化为json格式后存储在elasticsearch中
索引(index):相同类型的文档的集合(也可以叫做索引库)
映射(mapping):索引中文档的字段约束信息,类似表的结构约束
索引库操作
Mapping映射属性
mapping是对索引l库中文档的约束,常见的mapping属性包括:
type:字段数据类型,常见的简单类型有:
字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址等等不能拆的东西)
数值:long、integer、short、byte、double、float、
布尔:boolean
日期:date
对象:object
index:是否创建索引,默认为true
analyzer:使用哪种分词器
properties:该字段的子字段(嵌套的时候要用到)、

索引库的CRUD
Elasticsearch提供的所有APl都是Restful的接口,遵循Restful的基本规范:
| 接口类型 | 请求方式 | 请求路径 | 请求参数 |
|---|---|---|---|
| 查询用户 | GET | /users/{id} | • 路径中的id |
| 新增用户 | POST | /users | • json格式user对象 |
| 修改用户 | PUT | /users/{id} | • 路径中的id• json格式对象 |
| 删除用户 | DELETE | /users/{id} | • 路径中的id |
创建索引库和mapping的请求语法如下:
1 | PUT /索引库名称 |
示例
1 | PUT /heima |
1 | #查询索引库 |
索引库和mapping一旦创建无法修改,但是可以添加新的字段,语法如下:
索引库不支持修改
1 | PUT /索引库名/_mapping |
示例
1 | PUT /heima/_mapping |
文档操作
文档CRUD
新增文档的请求格式如下(要指定好id):
1 | POST /索引库名/_doc/文档id |
示例
1 | POST /heima/_doc/1 |
查询与删除
1 | #查询文档 |
修改
方式一:全量修改,会删除旧文档,添加新文档(填错id,会直接变新增)
1 | PUT /索引库名/_doc/文档id |
方式二:增量修改,修改指定字段值
1 | POST /索引库名/_update/文档id |
示例
1 | POST /heima/_update/1 |
批量处理
Elasticsearch中允许通过一次请求中携带多次文档操作,也就是批量处理,语法格式如下:
第一行为操作类型,第二行为要操作的数据
1 | POST /_bulk |
示例
1 | POST /_bulk |
批量删除:
1 | POST /_bulk |
JavaRestClient
客户端初始化
- 引入 RestHighLevelClient 依赖
在 pom.xml 中添加 ES 高级客户端依赖:
1 | <dependency> |
- 覆盖 Spring Boot 默认 ES 版本
Spring Boot 默认集成的 ES 版本为 7.17.0,需在 pom.xml 中指定项目所需版本(示例为 7.12.1):
1 | <properties> |
- 初始化 RestHighLevelClient 实例
通过 RestClient.builder 构建客户端,指定 ES 服务地址:
1 | RestHighLevelClient client = new RestHighLevelClient( |
商品的Mapping映射
我们要实现商品搜索,那么索引库的字段肯定要满足页面搜索的需求:
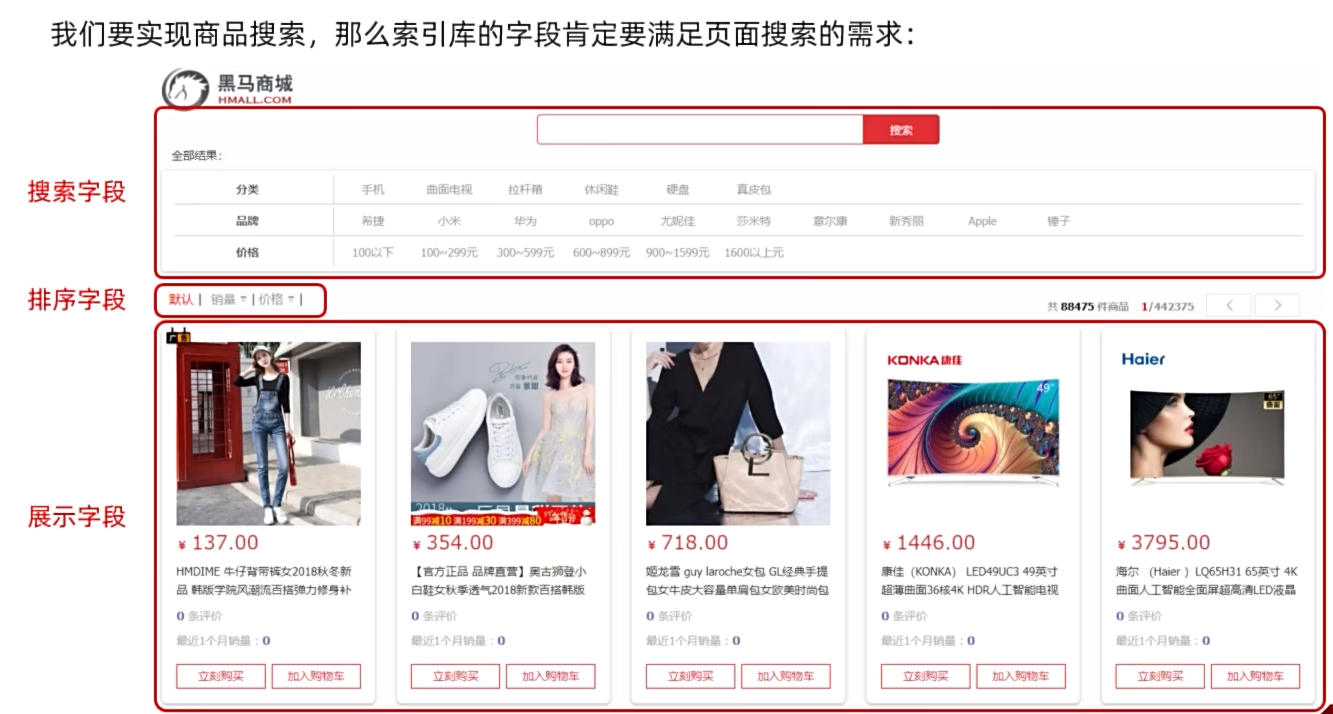
创建商品索引库
1 | PUT /items |
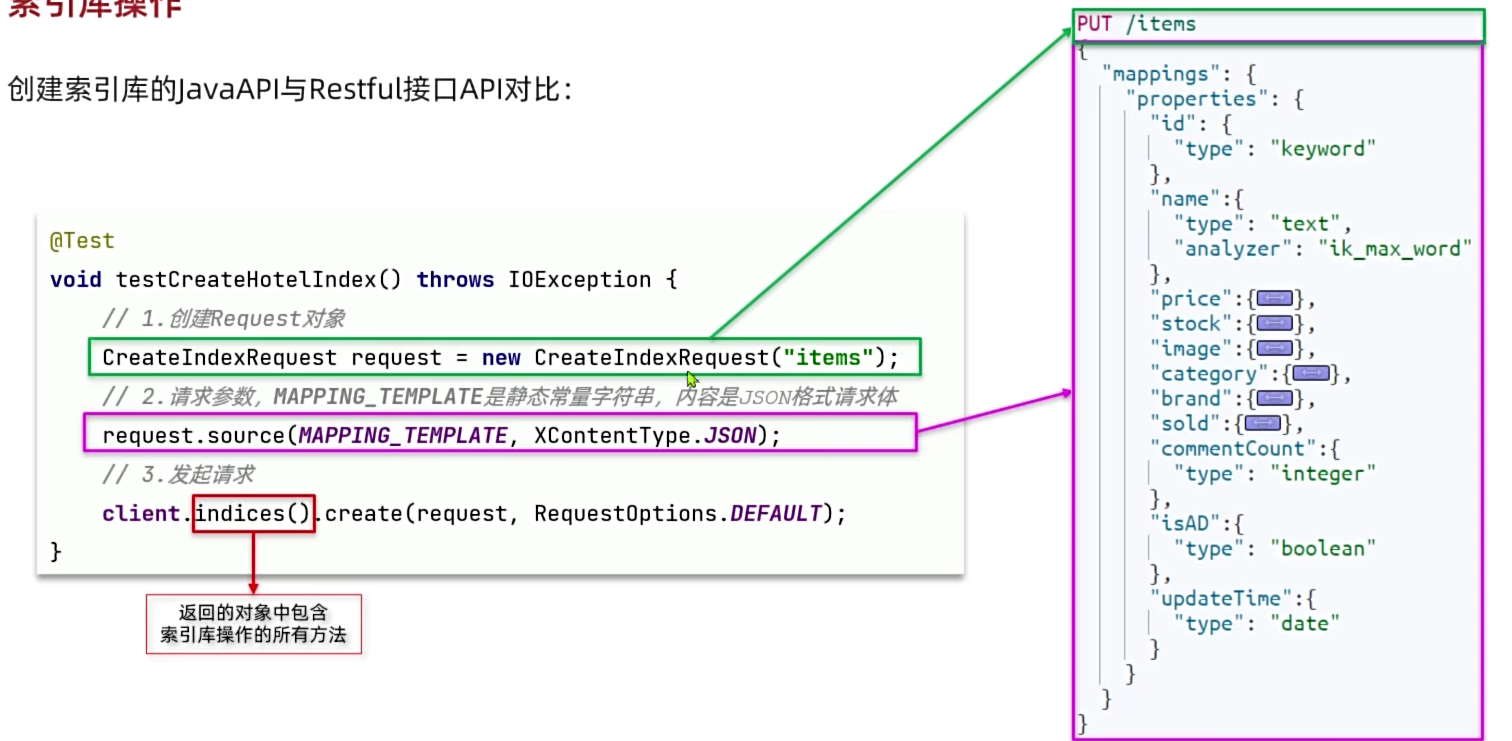
索引库操作
创建索引库的JaVaAPl与Restful接口API对比:
删除索引库
1 |
|
查询索引库信息
1 |
|
新增文档
新增文档的JavaAPl如下:

1 |
|
文档的CRUD
删除文档的JavaAPl如下:

查询文档包含查询和解析响应结果两部分。对应的JaVaAPI如下:

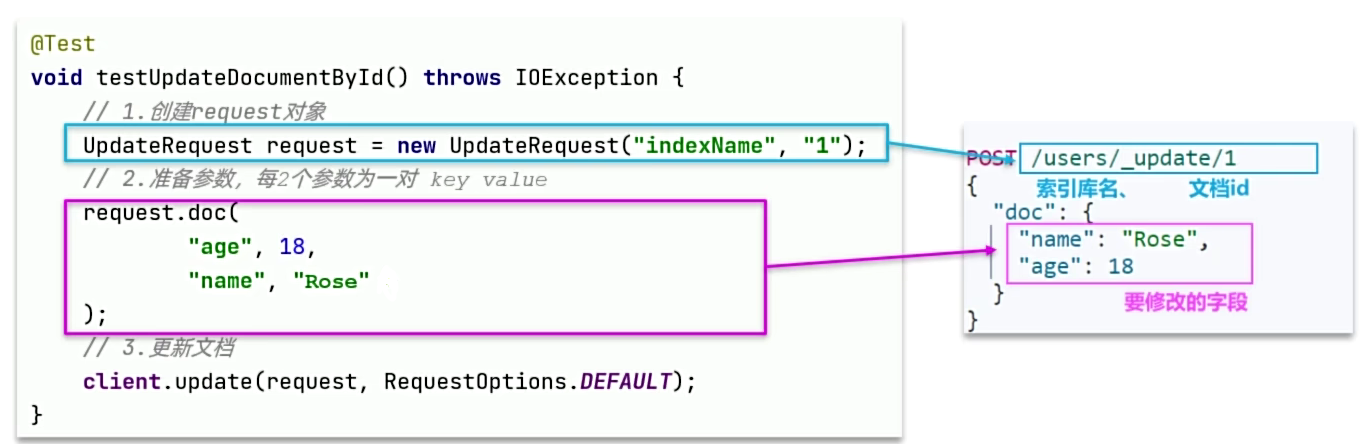
修改文档数据有两种方式:
方式一:全量更新。再次写入id一样的文档,就会删除旧文档,添加新文档。与新增的JavaAPl一致。
方式二:局部更新。只更新指定部分字段。
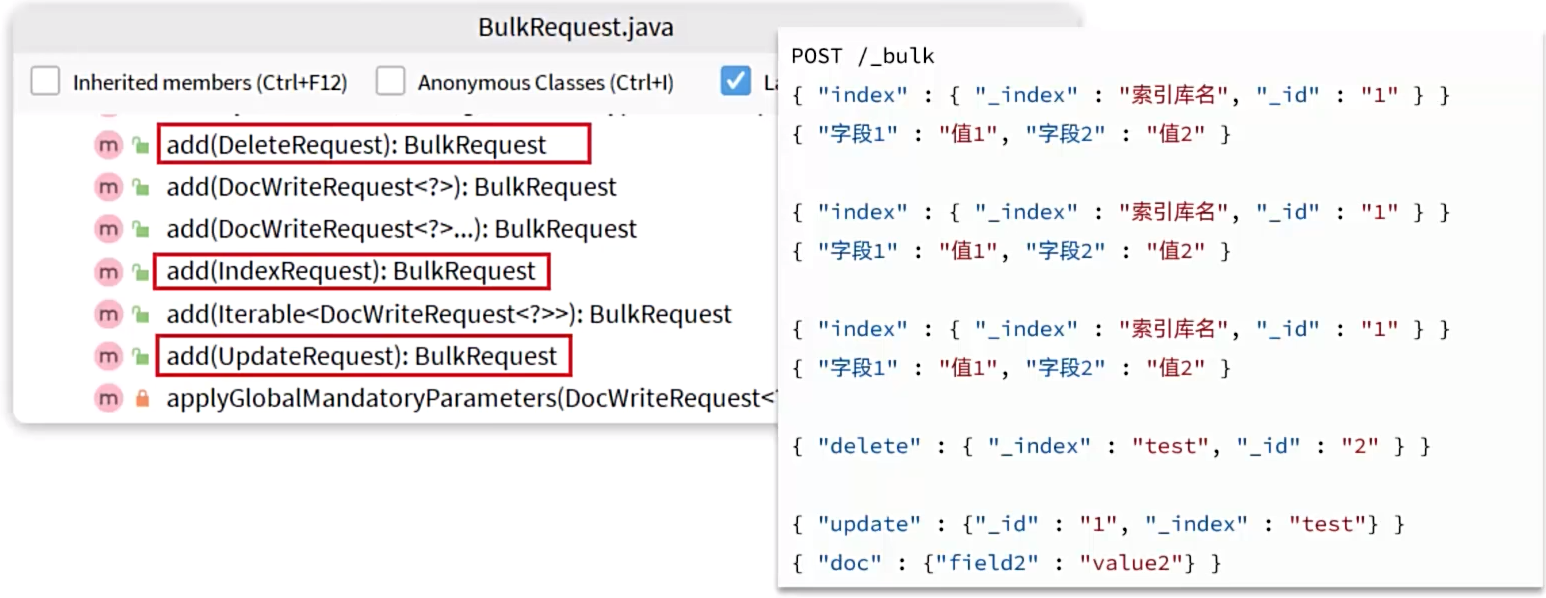
文档批处理
批处理代码流程与之前类似,只不过构建请求会用到一个名为BulkRequest来封装普通的CRUD请求:
1 |
|
1 |
|
DSL查询
Elasticsearch提供了DSL(Domain SpecificLanguage)查询,就是以JsON格式来定义查询条件。类似这样:
1 | POST _search |
DSL查询可以分为两大类:
- 叶子查询(Leaf query clauses):一般是在特定的字段里查询特定值,属于简单查询,很少单独使用。
- 复合查询(compoundqueryclauses):以逻辑方式组合多个叶子查询或者更改叶子查询的行为方式。
在查询以后,还可以对查询的结果做处理,包括:
排序:按照1个或多个字段值做排序
分页:根据from和size做分页,类似MySQL
高亮:对搜索结果中的关键字添加特殊样式,使其更加醒目
聚合:对搜索结果做数据统计以形成报表
快速入门
基于DSL的查询语法如下:
1 | GET /indexName/_search |
示例:
1 | // 查询所有 |
叶子查询
叶子查询还可以进一步细分,常见的有:
- 全文检索(fulltext)查询:利用分词器对用户输入内容分词,然后去词条列表中匹配。例如:
- match_query
- multi_match_query
- 精确查询:不对用户输入内容分词,直接精确匹配,一般是查找keyword、数值、日期、布尔等类型。例如:
- ids
- range
- term
- 地理(geo)查询:用于搜索地理位置,搜索方式很多。例如:
- geo_distance
- geo_bounding_box
match查询:全文检索查询的用户输入内容分词然后去倒排索引库检索,语法:
1 | GET /indexName/_search |
multi_match:与match查询类似,只不过允许同时查询多个字段,语法:
1 | GET /indexName/_search |
全文检索查询示例(按匹配度排序):
1 | GET /items/_search |
精确查询,英文是Term-level query,顾名思义,词条级别的查询。也就是说不会对用户输入的搜索条件再分词,而是作为一个词条,与搜索的字段内容精确值匹配。
因此推荐查找keyword、数值、日期、boolean类型的字段。例如id、price、城市、地名、人名等作为一个整体才有含义的字段。
1 | // term查询 |
示例:
1 | GET /items/_search |
查询范围的:
1 | // range查询 |
示例:
1 | GET /items/_search |
复合查询
复合查询大致可以分为两类:
- 第一类:基于逻辑运算组合叶子查询,实现组合条件,例如
- bool
- 第二类:基于某种算法修改查询时的文档相关性算分,从而改变文档排名。例如:
- function_score
- dis_max
布尔查询
布尔查询是一个或多个查询子句的组合。子查询的组合方式有:
- must:必须匹配每个子查询,类似“与”
- should:选择性匹配子查询,类似“或’
- must_not:必须不匹配,不参与算分,类似“非”
- filter:必须匹配,不参与算分
1 | GET /items/_search |
需求:我们要搜索”智能手机”,但品牌必须是华为,价格必须是900~1599
1 | GET /items/_search |
- lt:less than 小于
- lte : less than equal 小于等于
- gt : greater than 大于
- gte : greater then equal 大于等于
算分查询
排序和分页
elasticsearch支持对搜索结果排序,默认是根据相关度算分(_score)来排序,也可以指定字段排序。可以排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等。
1 | GET /indexName/_search |
需求:搜索商品,按照销量排序,销量一样则按照价格升序
1 | GET /items/_search |
elasticsearch 默认情况下只返回toplo的数据。而如果要查询更多数据就需要修改分页参数了。elasticsearch中通过修改from、size参数来控制要返回的分页结果:
- from:从第几个文档开始
- size:总共查询几个文档
1 | GET /items/_search |
深度分页问题
elasticsearch的数据一般会采用分片存储,也就是把一个索引l中的数据分成N份,存储到不同节点上。查询数据时需要汇总各个分片的数据。
1 | GET/hotel/_search |
实现思路:
- 对数据排序
- 找出第990~1000名
聚合所有结果
重新排序选取前1000个
针对深度分页,ES提供了两种解决方案,官方文档:
- searchafter:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式(记住排列的第一页的最后一个的序列值,然后根据这个序列值去查询接下来的数据)
- scroll:原理将排序数据形成快照,保存在内存。官方已经不推荐使用。
searchafter模式:
- 优点:没有查询上限,支持深度分页
- 缺点:只能向后逐页查询,不能随机翻页
- 场景:数据迁移、手机滚动查询
一般不会使用这个深度查询,除非有业务需求
高亮显示
高亮显示:就是在搜索结果中把搜索关键字突出显示
1 | GET /items/_search |
通常情况下你是不需要去指定高亮的标签,它默认是< em >的
完整的总结式的搜索语法:
1 | GET /items/_search |
JavaRestClient查询
快速入门
数据搜索的Java代码我们分为两部分:
- 构建并发起请求
1 |
|
- 解析查询结果
1 |
|
构建复杂查询条件
在JavaRestAPl中,所有类型的query查询条件都是由QueryBuilders来构建的:
全文检索的查询条件构造API如下:
代码:
1 | //单字段查询 |
结果:
1 | GET /items/_search |
精确查询的查询条件构造API如下:
代码:
1 | //词条查询 |
结果:
1 | GET /items/_search |
布尔查询的查询条件构造API如下:
代码:
1 | //创建布尔查询 |
结果:
1 | GET /items/_search |
案例-构建复杂查询条件的搜索
需求:利用JavaRestClient实现搜索功能,条件如下:
- 搜索关键字为脱脂牛奶
- 品牌必须为德亚
- 价格必须低于300
1 |
|
排序和分页
与query类似,排序和分页参数都是基于request.source()来设置:
代码:
1 | //查询 |
结果:
1 | GET /indexName/_search |
高亮显示
高亮显示的条件构造API如下:
代码:
1 | // 3.得到_source,也就是原始json文档 |
结果:
1 | { |
数据聚合(数据分析)
聚合的分类
聚合(aggregations)可以实现对文档数据的统计、分析、运算。聚合常见的有三类:
- 桶(Bucket)聚合:用来对文档做分组
- TermAggregation:按照文档字段值分组
- DateHistogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
- 度量(Metric)聚合:用以计算一些值,比如:最大值、最小值、平均值等
- Avg:求平均值
- Max:求最大值
- Min:求最小值
- Stats:同时求max、min、avg、sum等
- 管道(pipeline)聚合:其它聚合的结果为基础做聚合
注意
参与聚合的字段必须是Keyword、数值、日期、布尔的类型的字段
DSL实现聚合
我们要统计所有商品中共有哪些商品分类,其实就是以分类(category)字段对数据分组。category值一样的放在同一组,属于Bucket聚合中的Term聚合。
1 | GET /items/_search |
terms是对数据分组,所以返回的是buckets
默认情况下,Bucket聚合是对索引库的所有文档做聚合,我们可以限定要聚合的文档范围,只要添加query条件即可。
例如,我想知道价格高于3000元的手机品牌有哪些:
1 | GET /items/_search |
除了对数据分组(Bucket)以外,我们还可以对每个Bucket内的数据进一步做数据计算和统计。
例如:我想知道手机有哪些品牌,每个品牌的价格最小值、最大值、平均值。
1 | GET /items/_search |
Java客户端实现聚合
我们以品牌聚合为例:
查询:
1 |
|
解析:
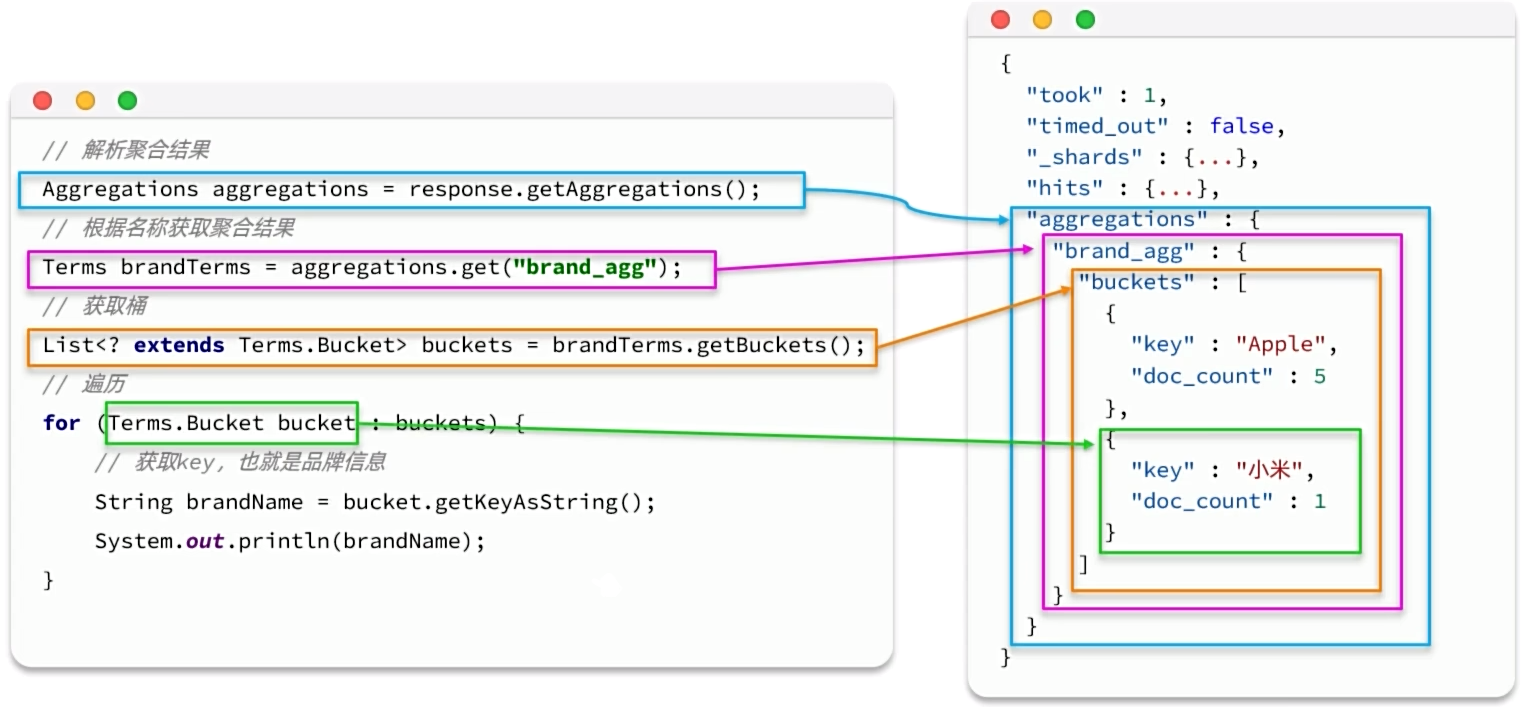
1 | // 4.解析聚合结果 |
Redis的面试
Redis主从
搭建主从集群
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。
下图就是一个简单的Redis主从集群结构:
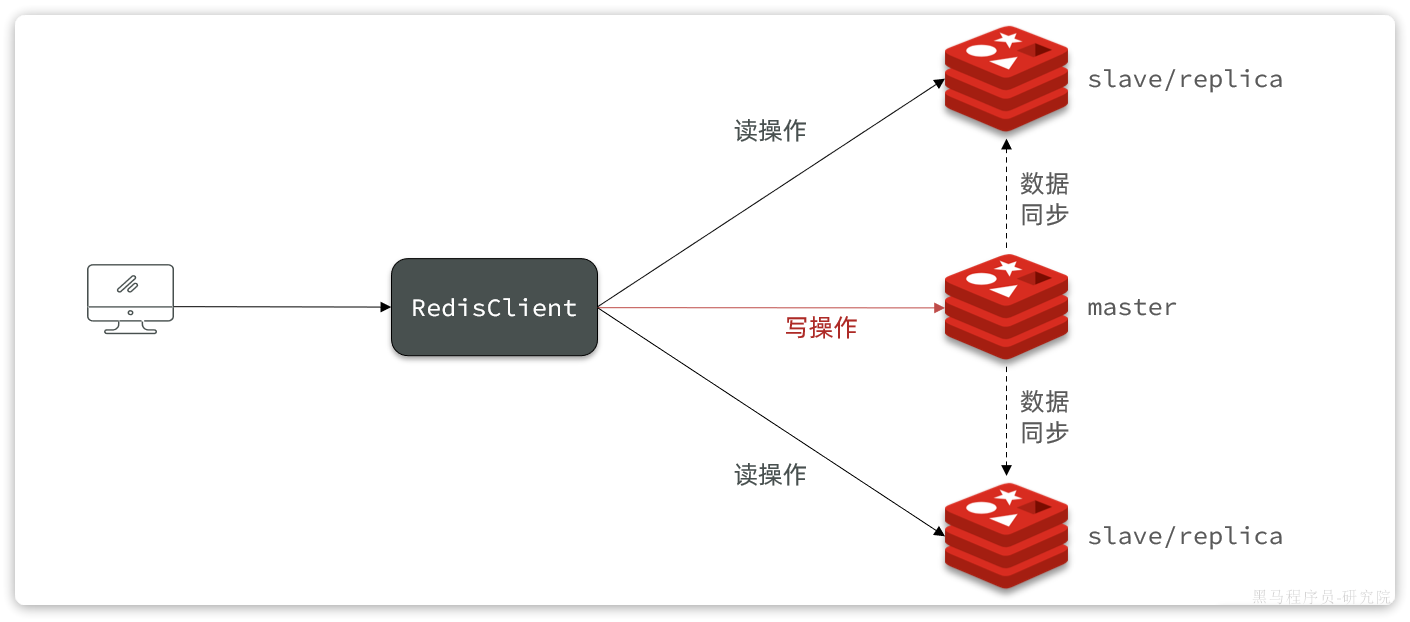
如图所示,集群中有一个master节点、两个slave节点(现在叫replica)。当我们通过Redis的Java客户端访问主从集群时,应该做好路由:
- 如果是写操作,应该访问master节点,master会自动将数据同步给两个slave节点
- 如果是读操作,建议访问各个slave节点,从而分担并发压力
搭建主从集群
我们会在同一个虚拟机中利用3个Docker容器来搭建主从集群,容器信息如下:
| 容器名 | 角色 | IP | 映射端口 |
|---|---|---|---|
| r1 | master | 虚拟机IP地址 | 7001 |
| r2 | slave | 虚拟机IP地址 | 7002 |
| r3 | slave | 虚拟机IP地址 | 7003 |
启动多个Redis实例
使用docker-compose文件来构建主从集群
1 | version: "3.2" |
将其上传至虚拟机的/root/redis目录下
执行命令,运行集群:
1 | docker compose up -d |
建立集群
虽然我们启动了3个Redis实例,但是它们并没有形成主从关系。我们需要通过命令来配置主从关系:
1 | # Redis5.0以前 |
要先与从的redis建立连接
1 | docker exec -it r2 redis-cli -p 7002 |
查看主从关系
1 | info replication |
连接r2,让其以r1为master
1 | # 连接r2 |
同样操作用于r3
测试
依次在r1、r2、r3节点上执行下面命令:
1 | set num 123 |
你会发现,只有在r1这个节点上可以执行set命令(写操作),其它两个节点只能执行get命令(读操作)。也就是说读写操作已经分离了。
主从同步原理
当主从第一次同步连接或断开重连时,从节点都会发送psync请求,尝试数据同步:
replicationlD:每一个master节点都有自己的唯一id,简称replid
offset:repl_backlog中写入过的数据长度,写操作越多,offset值越大,主从的offset一致代表数据一致

主从集群优化
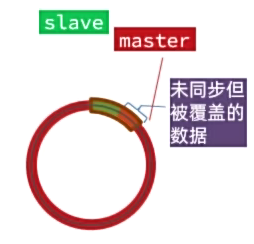
repl_backlog的大小有限,默认只有1M,是一个环型数组,会有数据覆盖
可以从以下几个方面来优化Redis主从就集群:
- 在master中配置repl-diskless-syncyes启用无磁盘复制,避免全量同步时的磁盘lO。
- Redis单节点上的内存占用不要太大,次减少RDB导致的过多磁盘IO(一般不要超过8G)
- 适当提高repl_baklog的大小,发现slave岩机时尽快实现故障恢复,尽可能避免全量同步
- 限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力
- 其实一主一从能满足大部分情况,一主三从也行
哨兵原理
Redis提供了哨兵(Sentinel)机制来实现主从集群的自动故障恢复。哨兵的具体作用如下:
哨兵作用:
- 监控:Sentinel会不断检查您的master和slave是否按预期工作
- 自动故障切换:如果master故障,Sentinel会将一个slave提升为master。当故障实例恢复后也以新的master为主
- 通知:当集群发生故障转移时,Sentinel会将最新节点角色信息推送给Redis的客户端
哨兵的服务状态监控:
Sentinel基于心跳机制监测服务状态,每隔1秒向集群的每个实例发送ping命令:
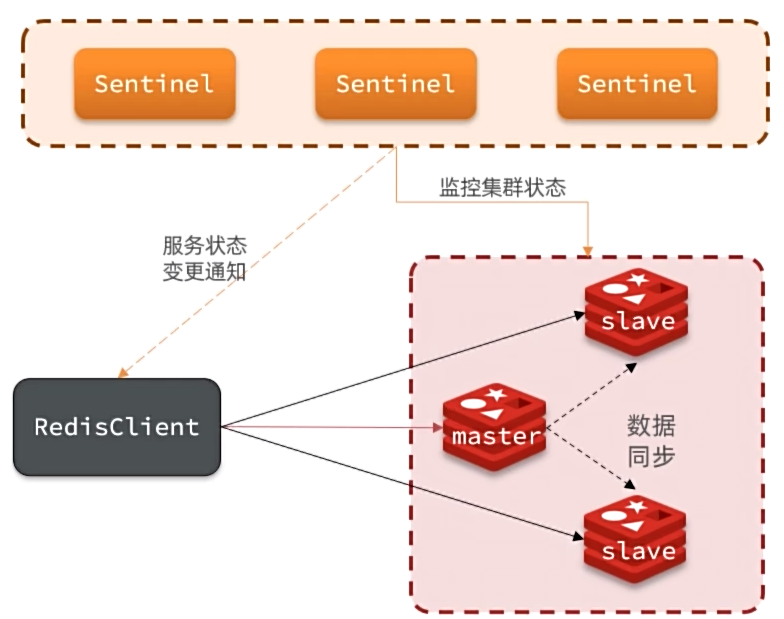
主观下线:如果某sentinel节点发现某实例未在规定时间响应,则认为该实例主观下线。
客观下线:若超过指定数量(quorum)的sentinel都认为该实例主观下线,则该实例客观下线。quorum值最好超过Sentinel实例数量的一半。
选举新的master
一旦发现master故障,sentinel需要在salve中选择一个作为新的master,选择依据是这样的:
- 首先会判断slave节点与master节点断开时间长短,如果超过指定值(down-after-milliseconds*10)则会排除该slave节点
- 然后判断slave节点的slave-priority值,越小优先级越高,如果是o则永不参与选举
- 如果slave-prority一样,则判断slave节点的offset值,越大说明数据越新,优先级越高
- 最后是判断slave节点的运行id大小,越小优先级越高
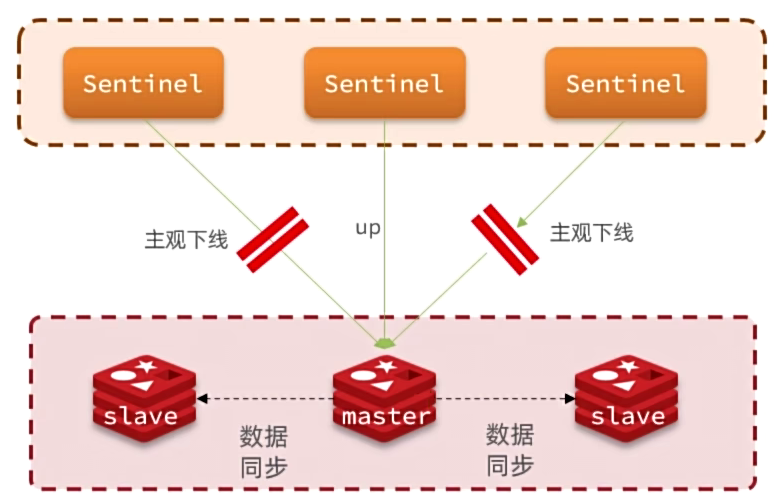
当选中了其中一个slave为新的master后(例如slave1),故障的转移的步骤如下:
sentinel给备选的slave1节点发送slaveofnoone命令,让该节点成为master
sentinel给所有其它slave发送slaveof 192.168.149.128 7002命令,让这些slave成为新master的从节点,开始从新的master上同步数据。
搭建哨兵集群
首先,我们停掉之前的redis集群:
1 | # 老版本DockerCompose |
然后,我们把sentinel.conf文件上传
其内容如下:
1 | sentinel announce-ip "192.168.149.128" |
说明:
sentinel announce-ip "192.168.149.128":声明当前sentinel的ipsentinel monitor hmaster 192.168.149.128 7001 2:指定集群的主节点信息hmaster:主节点名称,自定义,任意写192.168.149.128 7001:主节点的ip和端口2:认定master下线时的quorum值
sentinel down-after-milliseconds hmaster 5000:声明master节点超时多久后被标记下线sentinel failover-timeout hmaster 60000:在第一次故障转移失败后多久再次重试
我们在虚拟机的/root/redis目录下新建3个文件夹:s1、s2、s3
将课前资料提供的sentinel.conf文件分别拷贝一份到3个文件夹中。
接着修改docker-compose.yaml文件,内容如下:
1 | version: "3.2" |
直接运行命令,启动集群:
1 | docker compose up -d |
Redis分片集群
搭建分片集群(省去哨兵)
主从和哨兵可以解决高可用、高并发读的问题。但是依然有两个问题没有解决:
- 海量数据存储问题
- 高并发写的问题
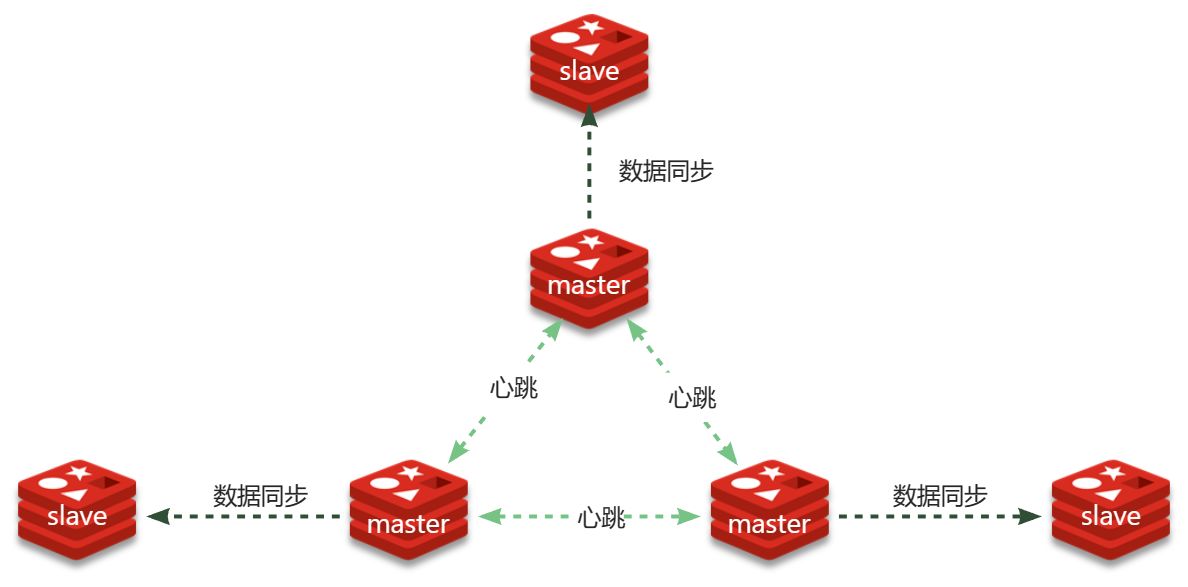
使用分片集群可以解决上述问题,分片集群特征:
- 集群中有多个master,每个master保存不同数据
- 每个master都可以有多个slave节点
- master之间通过ping监测彼此健康状态
计划部署的节点信息如下:
| 容器名 | 角色 | IP | 映射端口 |
|---|---|---|---|
| r1 | master | 192.168.149.128 | 7001 |
| r2 | master | 192.168.149.128 | 7002 |
| r3 | master | 192.168.149.128 | 7003 |
| r4 | slave | 192.168.149.128 | 7004 |
| r5 | slave | 192.168.149.128 | 7005 |
| r6 | slave | 192.168.149.128 | 7006 |
在虚拟机的/root目录下新建一个redis-cluster目录,然后在其中新建一个docker-compose.yaml文件,内容如下:
1 | version: "3.2" |
注意:使用Docker部署Redis集群,network模式必须采用host
进入/root/redis-cluster目录,使用命令启动redis:
1 | docker-compose up -d |
启动成功,可以通过命令查看启动进程:
1 | ps -ef | grep redis |
可以发现每个redis节点都以cluster模式运行。不过节点与节点之间并未建立连接。
接下来,我们使用命令创建集群:
1 | # 进入任意节点容器 |
命令说明:
redis-cli --cluster:代表集群操作命令create:代表是创建集群--cluster-replicas 1:指定集群中每个master的副本个数为1- 此时
节点总数 ÷ (replicas + 1)得到的就是master的数量n。因此节点列表中的前n个节点就是master,其它节点都是slave节点,随机分配到不同master
- 此时
接着,我们可以通过命令查看集群状态:
1 | redis-cli -p 7001 cluster nodes |
散列插槽
在Redis集群中,共有16384个hashslots,集群中的每一个master节点都会分配一定数量的hashslots:
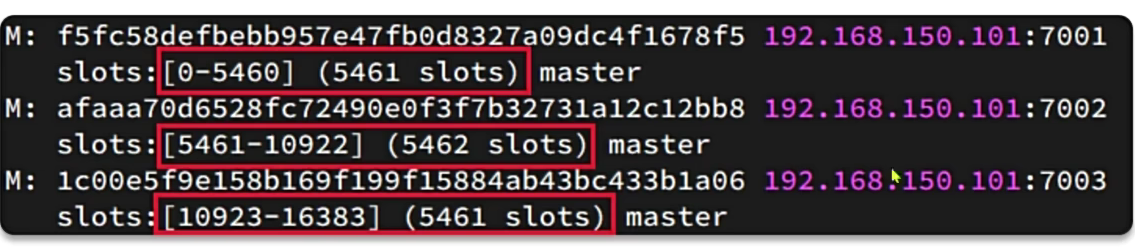
Redis数据不是与节点绑定,而是与插槽slot绑定。当我们读写数据时,Redis基于cRC16算法对key做hash运算,得到的结果与16384取余,就计算出了这个key的slot值。然后到slot所在的Redis节点执行读写操作。
redis在计算key的hash值是不一定是根据整个key计算,分两种情况:
- 当key中包含{}时,根据{之间的字符串计算hashslot
- 当key中不包含{}时,则根据整个key字符串计算hashslot
例如:key是num,那么就根据num计算,如果是{itcast}num,则根据itcast计算。
Redis数据结构
RedisObject
Redis中的任意数据类型的键和值都会被封装为一个RedisObject,也叫做Redis对象,源码如下:
16个字节
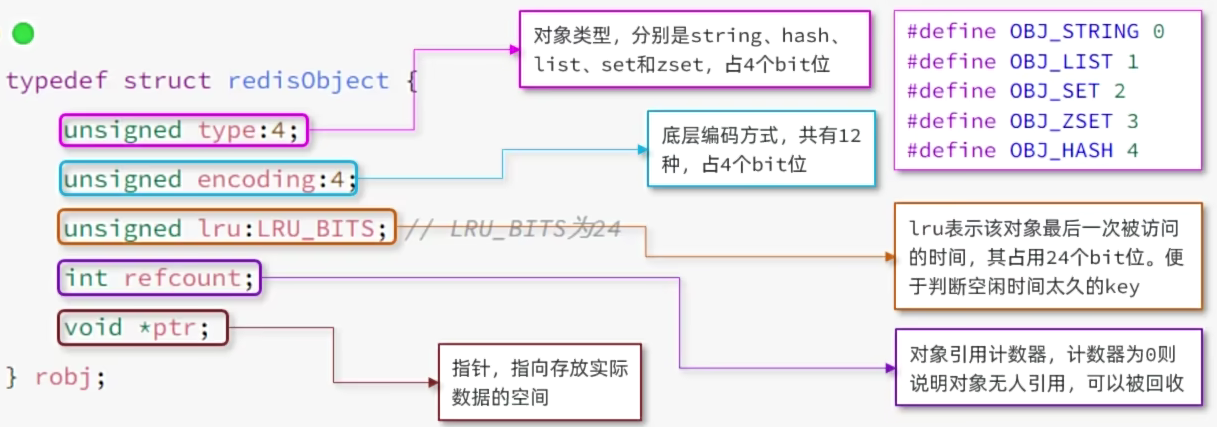
存储的数据的时候尽量使用除了String的其他类型,因为会出现多个key和vule的键值对,导致浪费
Redis中会根据存储的数据类型不同,选择不同的编码方式,共包含12种不同类型:
| 编号 | 编码方式 | 说明 |
|---|---|---|
| 0 | OBJ_ENCODING_RAW | raw编码动态字符串 |
| 1 | OBJ_ENCODING_INT | long类型的整数的字符串 |
| 2 | OBJ_ENCODING_HT | 哈希表(字典dict) |
| 3 | OBJ_ENCODING_ZIPMAP | 已废弃 |
| 4 | OBJ_ENCODING_LINKEDLIST | 双端链表 |
| 5 | OBJ_ENCODING_ZIPLIST | 压缩列表 |
| 6 | OBJ_ENCODING_INTSET | 整数集合 |
| 7 | OBJ_ENCODING_SKIPLIST | 跳表 |
| 8 | OBJ_ENCODING_EMBSTR | embstr的动态字符串 |
| 9 | OBJ_ENCODING_QUICKLIST | 快速列表 |
| 10 | OBJ_ENCODING_STREAM | Stream流 |
| 11 | OBJ_ENCODING_LISTPACK | 紧凑列表 |
Redis中会根据存储的数据类型不同,选择不同的编码方式。每种数据类型的使用的编码方式如下:
| 数据类型 | 编码方式 |
|---|---|
| OBJ_STRING | int、embstr、raw |
| OBJ_LIST | LinkedList和ZipList(3.2以前)、QuickList(3.2以后) |
| OBJ_SET | intset、HT |
| OBJ_ZSET | ZipList(7.0以前)、Listpack(7.0以后)、HT、SkipList |
| OBJ_HASH | ZipList(7.0以前)、Listpack(7.0以后)、HT |
SkipList
SkipList(跳表)首先是链表,但与传统链表相比有几点差异:
- 元素按照升序排列存储
- 节点可能包含多个指针,指针跨度不同。
- 最多32级指针,第32级的跨度达到了2的32次方
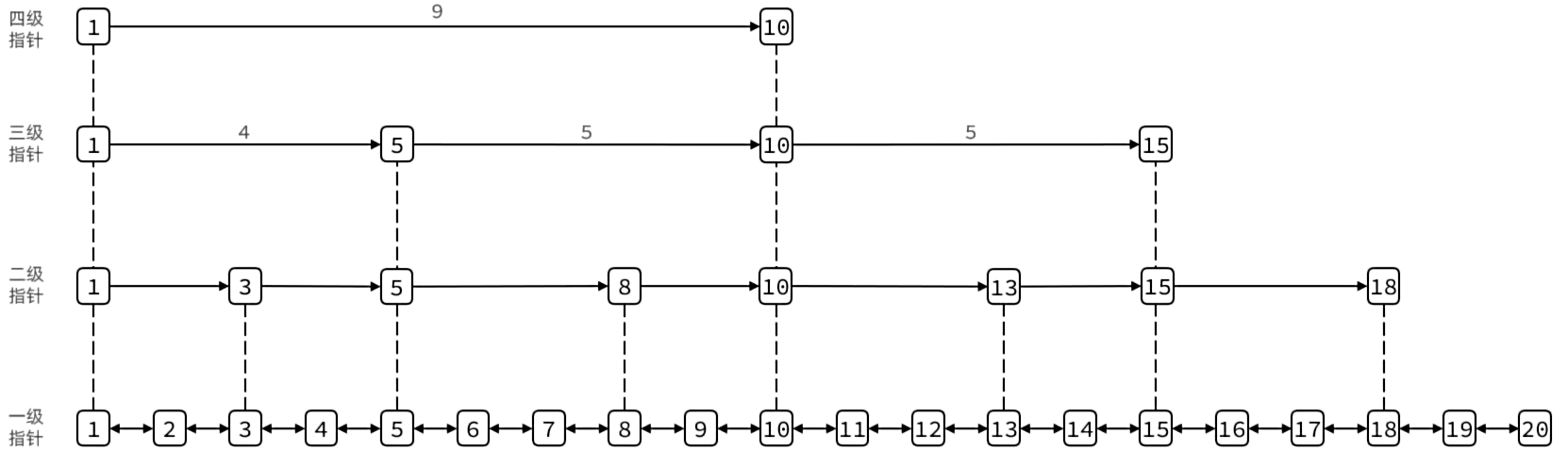
特点:
- 跳跃表是一个有序的双向链表
- 每个节点都可以包含多层指针,层数是1到32之间的随机数
- 不同层指针到下一个节点的跨度不同,层级越高,跨度越大
- 增删改查效率与红黑树基本一致,实现却更简单。但空间复杂度更高
SortedSet
Sortedset数据结构的特点是:
- 每组数据都包含score和member(类似键值对结构)
- member唯一
- 可根据score排序
- 底层既有跳表也有哈希表
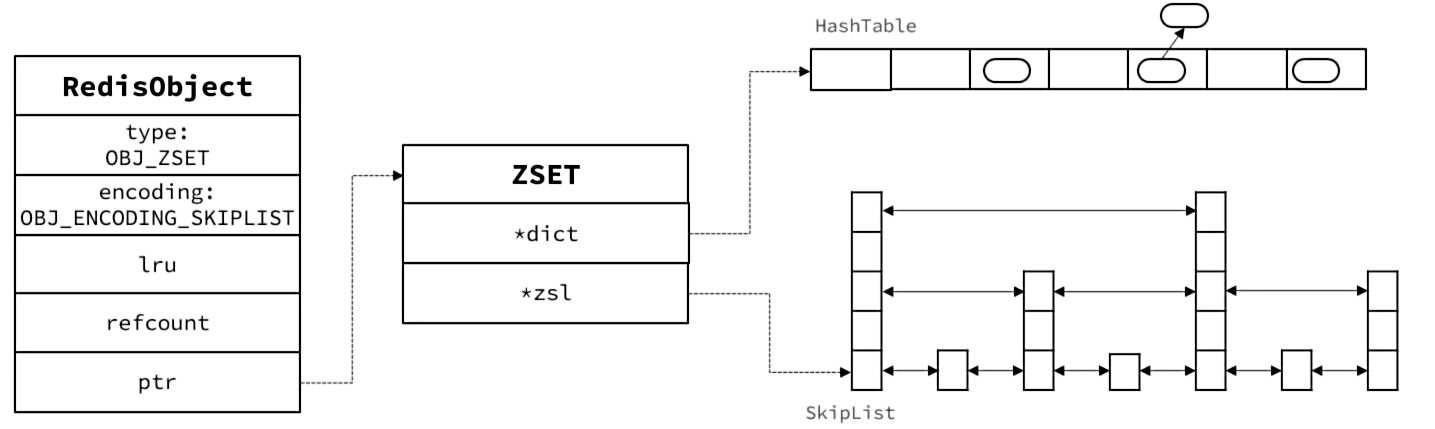
SortedSet的底层数据结构是怎样的?
- 首先SortedSet需要能存储score和member值,而且要快捷的根据member查询score,因此底层有一个哈希表,以member为键,以score为value
- 其次sortedSet还需要能根据score排序,因此底层还维护了一个跳表。
- 当需要根据member查询score时,就去哈希表中查询;
- 当需要根据score排序查询时,则基于跳表查询
Redis内存回收
过期KEY处理
Redis提供了expire命令,给key设置TTL(存活时间):
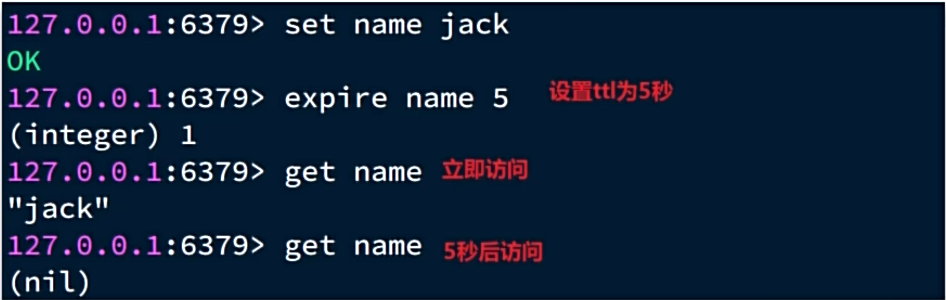
可以发现,当key的TTL到期以后,再次访问name返回的是nil,说明这个key已经不存在了,对应的内存也得到释放。从而起到内存回收的目的。
这里有两个问题需要我们思考:
- Redis是如何知道一个key是否过期呢?
- 是不是TTL到期就立即删除了呢?
Redis的本身是键值型数据库,其所有数据都存在一个redisDB的结构体中,其中包含两个哈希表:
- dict:保存Redis中所有的键值对
- expires:保存Redis中所有的设置了过期时间的KEY及其到期时间(写入时间+TTL)
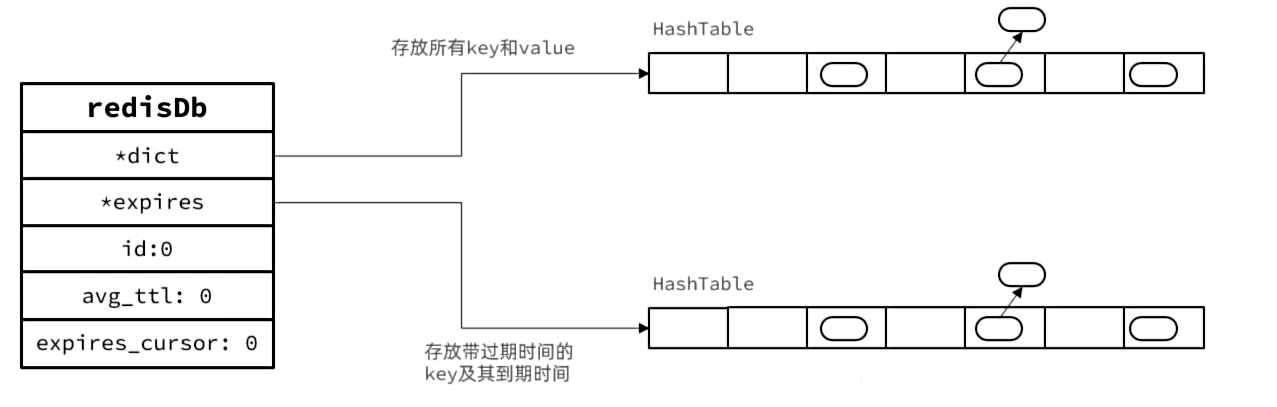
Redis并不会实时监测key的过期时间,在key过期后立刻删除。而是采用两种延迟删除的策略:
- 惰性删除:当有命令需要操作一个key的时候,检查该key的存活时间,如果已经过期才执行删除。
- 周期删除:通过一个定时任务,周期性的抽样部分有TTL的key,如果过期则执行删除。
周期删除的定时任务执行周期有两种:
- SLOW模式:默认执行频率为每秒10次,但每次执行时长不能超过25ms,受server.hz参数影响。
- FAST模式:频率不固定,跟随Redis内部IO事件循环执行。两次任务之间间隔不低于2ms,执行时长不超过1ms
Redis 采用 单线程 + Reactor 的模型,整个循环在 aeMain 中不断轮询并处理 文件事件(I/O)和 时间事件(定时任务)。循环每轮先处理 文件事件,再处理 时间事件
内存淘汰策略
内存淘汰:就是当Redis内存使用达到设置的阈值时,Redis主动挑选部分key删除以释放更多内存的流程。
Redis会在每次处理客户端命令时都会对内存使用情况做判断,如果必要则执行内存淘汰。内存淘汰的策略有:
普通:
- noeviction:不淘汰任何key,但是内存满时不允许写入新数据,默认就是这种策略。(废物)
- volatile-ttl:对设置了TTL的key,比较key的剩余TTL值,TTL越小越先被淘汰
随机:
- allkeys-random:对全体key,随机进行淘汰。也就是直接从db->dict中随机挑选(太危险)
- volatile-random:对设置了TTL的key,随机进行淘汰。也就是从db->expires中随机挑选。(太危险)
LRU算法(有概率问题):
LRU(LeastRecentlyUsed),最近最少使用。用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高。
- allkeys-lru:对全体key,基于LRU算法进行淘汰
- volatile-Lru:对设置了TTL的key,基于LRU算法进行淘汰
LFU算法(最为推荐):
LFU(LeastFrequentlyUsed),最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高。
- allkeys-lfu:对全体key,基于LFU算法进行淘汰
- volatile-lfu:对设置了TTL的key,基于LFU算法进行淘汰
使用:
优先考虑淘汰带TTL的key
Redis的数据都会被封装为RedisObject结构:
1 | typedef struct redisObject { |
LFU的访问次数之所以叫做逻辑访问次数,是因为并不是每次key被访问都计数,而是通过运算:
- 生成[0~1)之间的随机数R
- 计算1/(l日次数*lfu_log_factor+1),记录为P,lfu_log_factor默认为10
- 如果R<P,则计数器+1,且最大不超过255
- 访问次数会随时间衰减,距离上一次访问时间每隔lfu_decay_time分钟(默认1),计数器-1
这个算法的意思是只有频率高的使用,计数器才会去增长,而且使用频率越高,几率越低
Redis缓存
缓存一致性
三种模式:
Cache Aside Pattern(对原有代码有侵入,但是一致性更好 )
由业务开发者,在更新数据库的同时更新缓存
Read/Write Through Pattern(只管调用,不需要关业务,但是这样的服务需要自己去开发,使用比较少 )
缓存与数据库整合为一个服务由服务来维护一致性。业务升发者直接调用该服务接口,无需关心缓存一致性问题。
Write Behind Caching Pattern(去开发一个异步任务把缓存的数据保存到持久化数据库中,但是流程复杂,而且没有办法保证强的一致性,只有最终一致性;性能要求高的业务可以使用)
增删改查业务直接基于缓存,由其它线程异步的将缓存数据持久化到数据库,保证最终一致。
企业中第一种方案用的最多
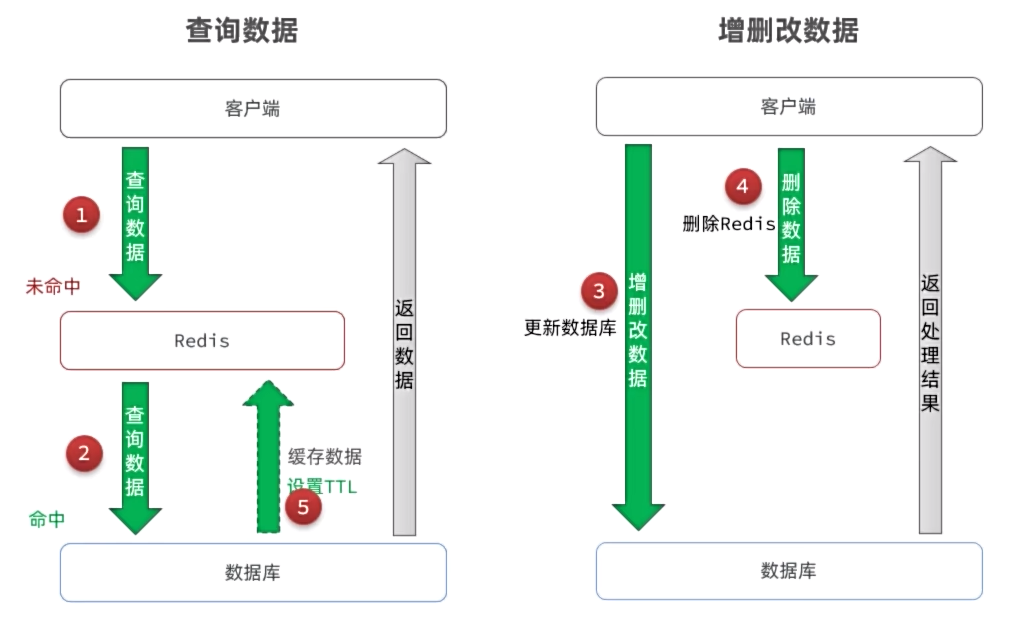
有些企业会做延时双删(删两次)
缓存一致性策略的最佳实践方案:
- 低一致性需求:使用Redis的key过期清理方案
- 高一致性需求:主动更新,并以超时剔除作为兜底方案
- 读操作:
- 缓存命中则直接返回
- 缓存未命中则查询数据库,并写入缓存,设定超时时间
- 写操作:
- 先写数据库,然后再删除缓存
- 要确保数据库与缓存操作的原子性
缓存穿透
缓存穿透是指客户端请求的数据在数据库中根本不存在,从而导致请求穿透缓存,直接打到数据库的问题。
常见的解决方案有两种:
- 缓存空对象(最常见的方案)
- 优点:实现简单,维护方便
- 缺点:额外的内存消耗
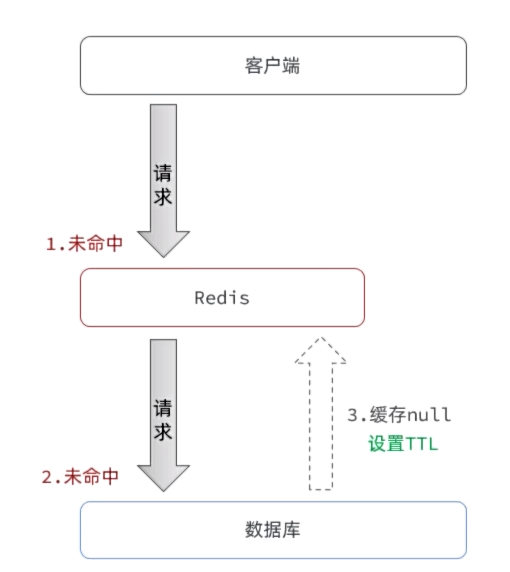
- 布隆过滤
- 优点:内存占用较少,没有多余key
- 缺点:
- 实现复杂
- 存在误判可能
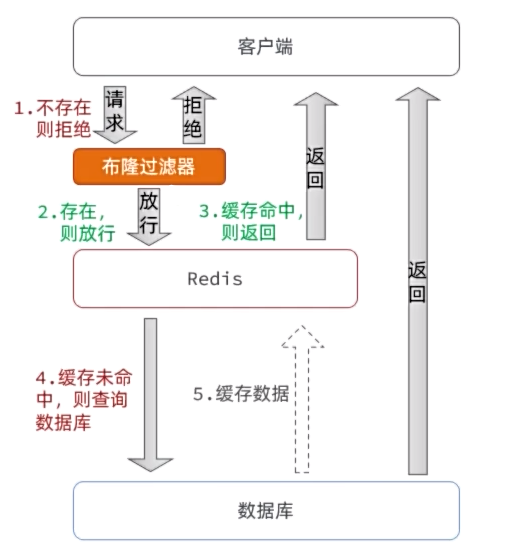
布隆过滤是一种数据统计的算法,用于检索一个元泰是否存在一个集合中。但是布隆过滤无需存储元素到集合,而是把元素映射到一个很长的二进制数位上。
(有误差)
- 首先需要一个很长很长的二进制数,默认每一位都是0
- 然后需要N个不同算法的哈希函数
- 将集合中的元素根据N个哈希函数做运算,得到N个数字,然后将每个数字对应的bit位标记为1
- 要判断某个元素是否存在,只需要把元素按照上述方式运算,判断对应的bit位是否是1即可
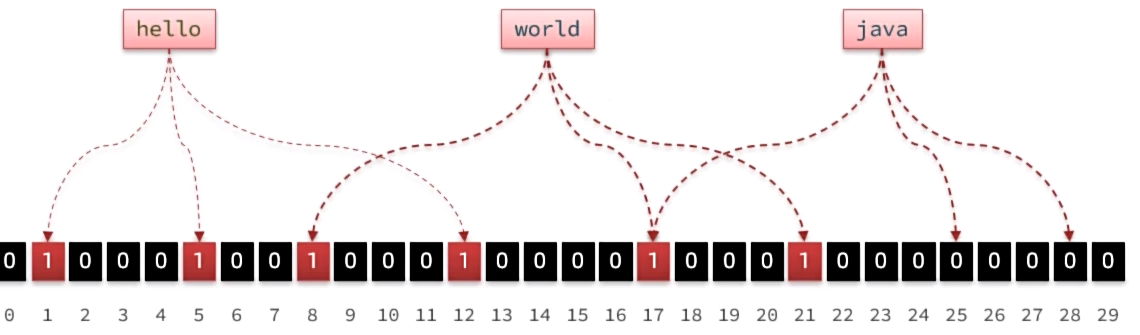
缓存雪崩
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务岩机,导致大量请求到达数据库,带来巨大压力。
解决方案:
给不同的Key的TTL添加随机值(同时失效的概率就会低很多)
利用Redis集群提高服务的可用性(集群+哨兵)
给缓存业务添加降级限流策略
给业务添加多级缓存:添加浏览器缓存(主要是本地静态资源)、nginx里面建立缓存(更新来会比较麻烦,要求是一致性要求低的数据)、在微服务内部建立JVM本地缓存,接着是redis,最后是数据库。
流程为:浏览器–>nginx–>jvm–>redis–>数据库
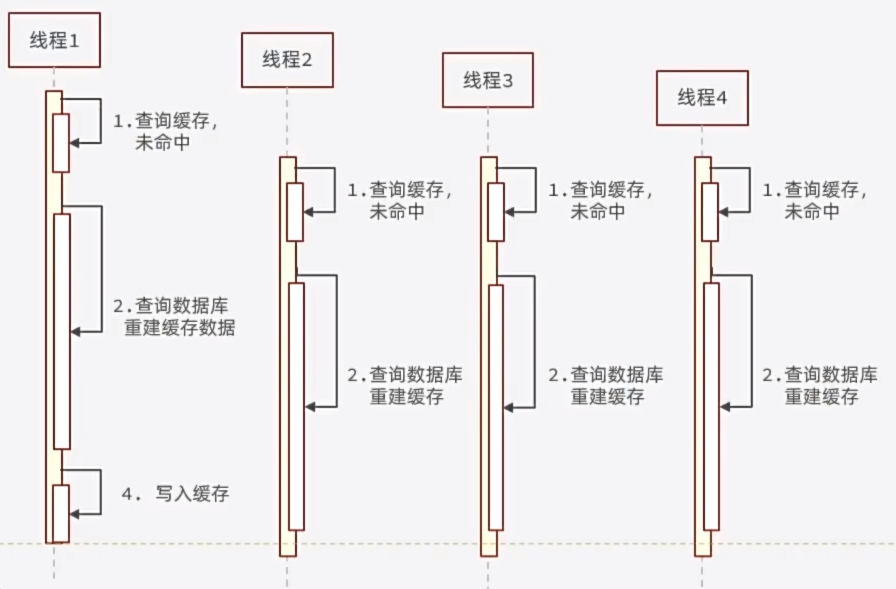
缓存击穿
缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
常见的解决方案有两种:
- 互斥锁(会导致阻塞)
- 逻辑过期
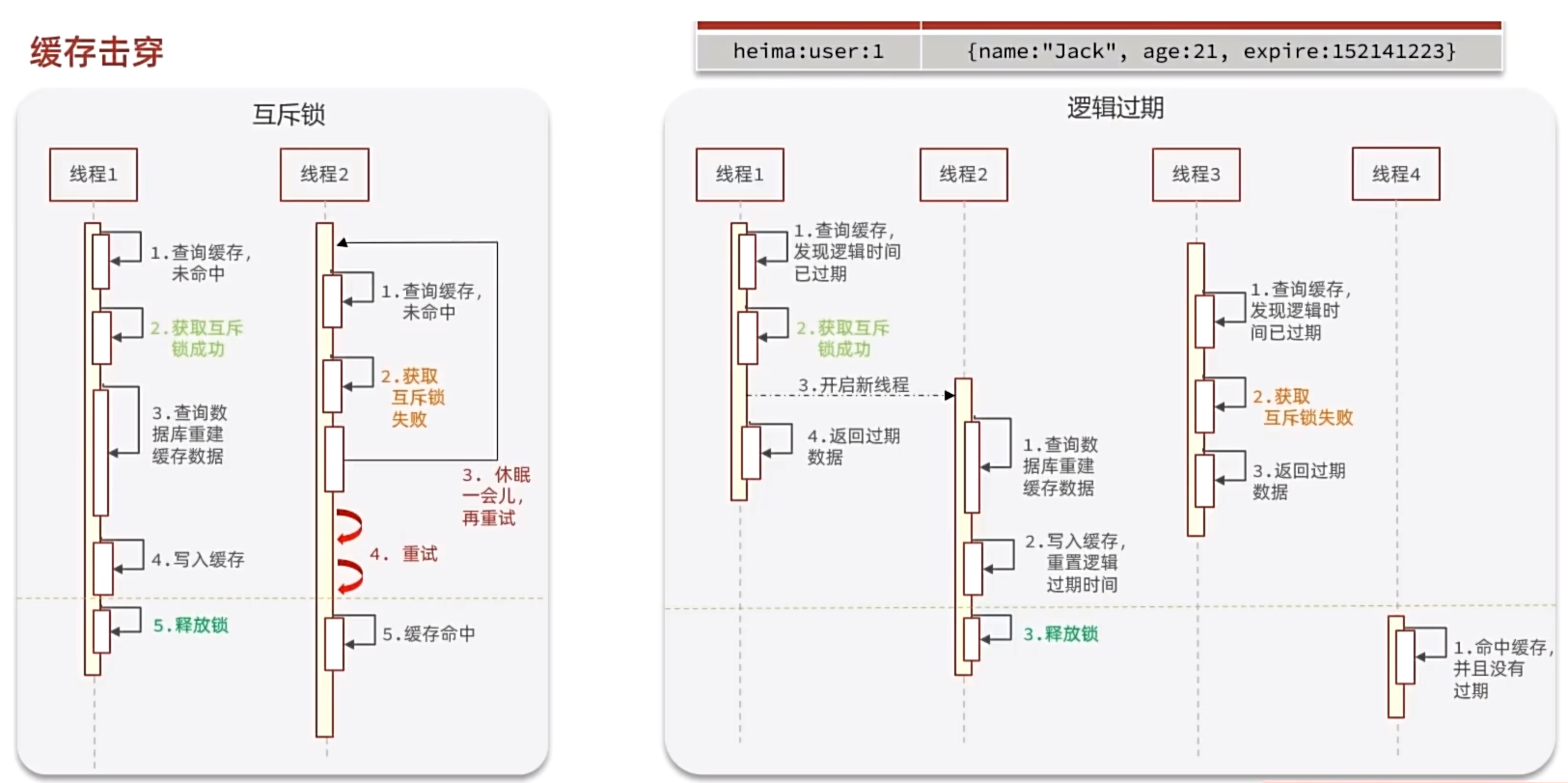
| 解决方案 | 优点 | 缺点 |
|---|---|---|
| 互斥锁 | • 没有额外的内存消耗• 保证一致性• 实现简单 | • 线程需要等待,性能受影响• 可能有死锁风险 |
| 逻辑过期 | • 线程无需等待,性能较好 | • 不保证一致性• 有额外内存消耗• 实现复杂 |
微服务的面试
分布式事务
- Consistency(一致性)
- Availability (可用性)
- Partitiontolerance(分区容错性)
EricBrewer说,分布式系统无法同时满足这三个指标。这个结论就叫做CAP定理。
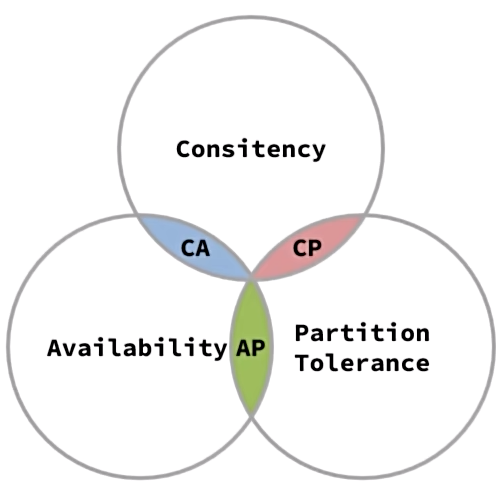
CAP和BASE
CAP定理-Consistency
Consistency(一致性):用户访问分布式系统中的任意节点,得到的数据必须一致
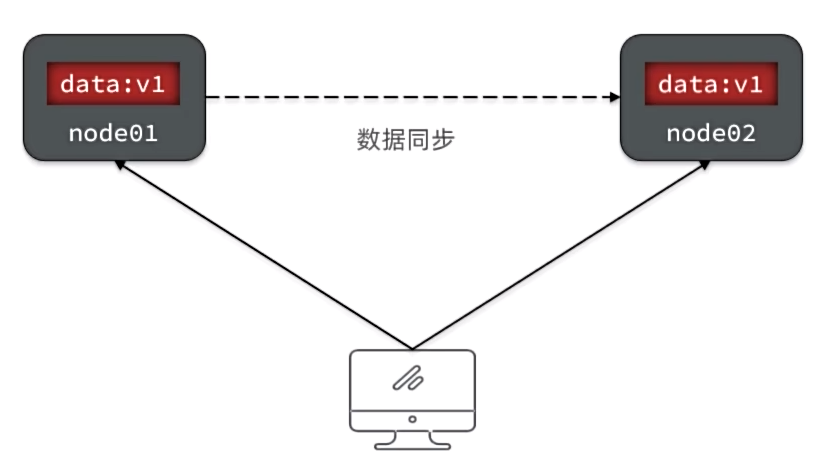
CAP定理-Availability
Availability(可用性):用户访问分布式系统时,读或写操作总能成功。只能读不能写,或者只能写不能读,或者两者都不能执行,就说明系统弱可用或不可用。
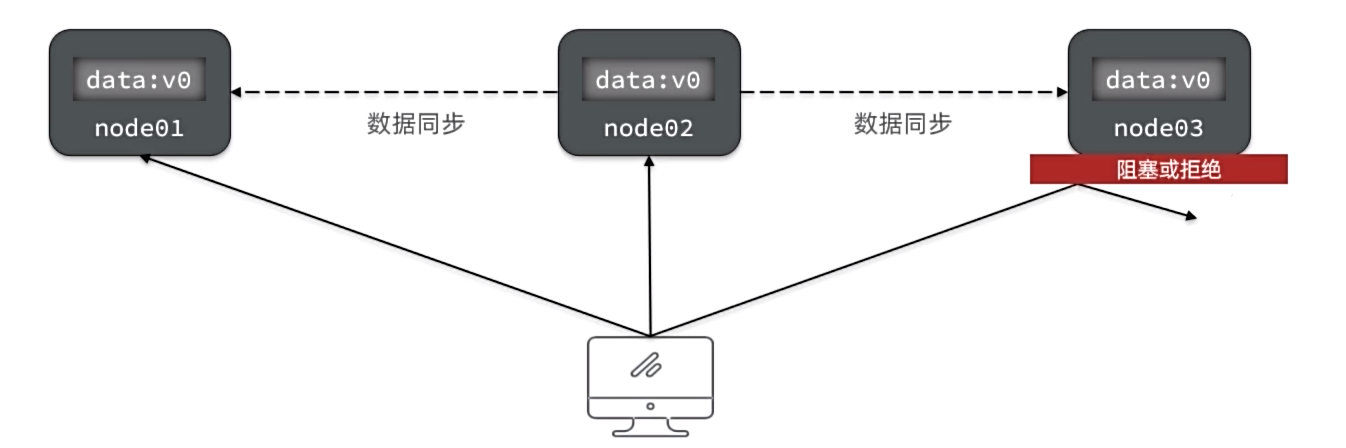
CAP定理-Partition tolerance
Partition(分区):因为网络故障或其它原因导致分布式系统中的部分节点与其它节点失去连接,形成独立分区。
Tolerance(容错):系统要能容忍网络分区现象,出现分区时,整个系统也要持续对外提供服务
- 如果此时只允许读,不允许写,满足所有节点一致性。但是牺牲了可用性。符合CP
- 如果此时允许任意读写,满足了可用性。但由于node3无法同步,与导致数据不一致,牺牲了一致性。符合AP
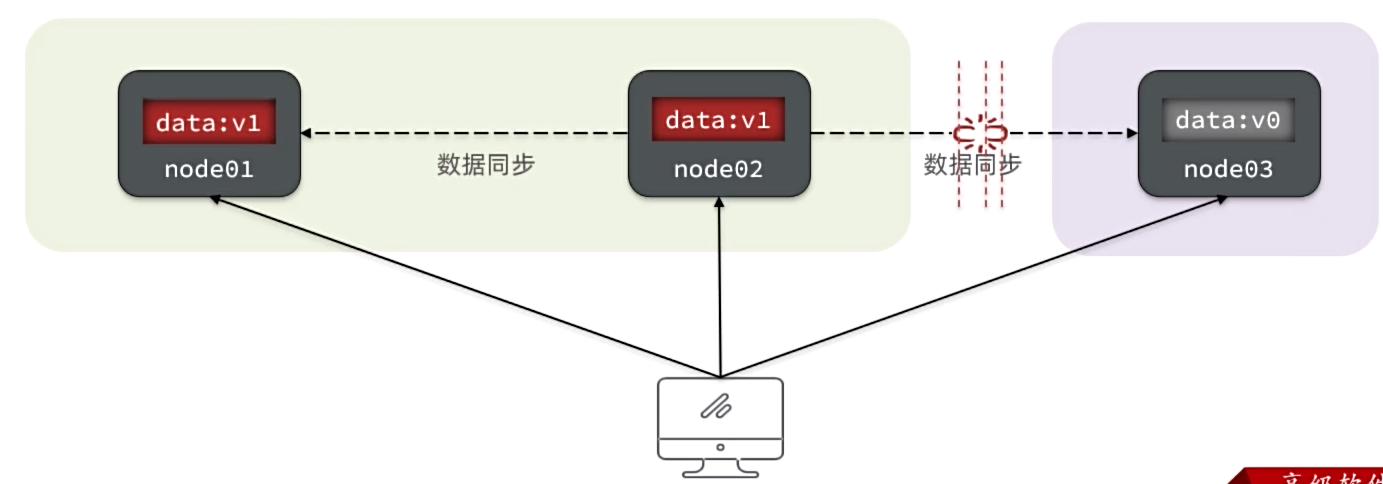
BASE理论
BASE理论是对CAP的一种解决思路,包含三个思想:
- BasicallyAvailable(基本可用):分布式系统在出现故障时,允许损失部分可用性,即保证核心可用。
- SoftState(软状态):在一定时间内,允许出现中间状态,比如临时的不一致状态。
- EventuallyConsistent(最终一致性):虽然无法保证强一致性,但是在软状态结束后,最终达到数据一致。
而分布式事务最大的问题是各个子事务的一致性问题,因此可以借鉴CAP定理和BASE理论:
- CP模式:各个子事务执行后互相等待,同时提交,同时回滚,达成强一致。但事务等待过程中,处于弱可用状态。(XA模式)
- AP模式:各子事务分别执行和提交,允许出现结果不一致,然后采用弥补措施恢复数据即可,实现最终一致。(AT模式)
AT模式脏写问题
AT模式是最常用的模式
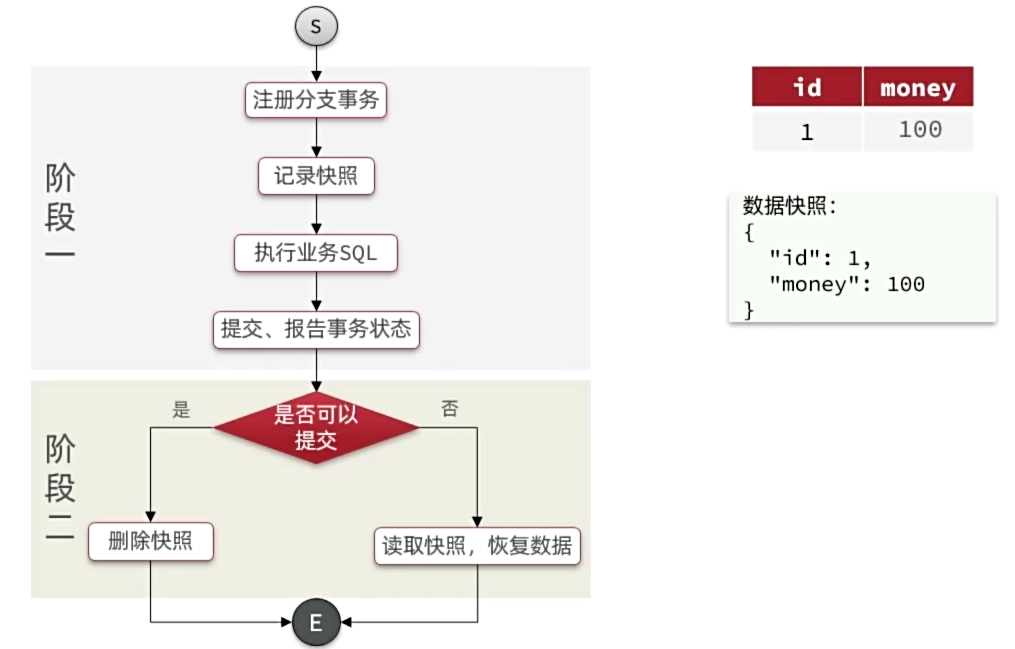 全局锁:由TC记录当前正在操作某行数据的事务该事务持有全局锁,具备执行权。
全局锁:由TC记录当前正在操作某行数据的事务该事务持有全局锁,具备执行权。


TCC模式(性能优于前面两种)
- Try:资源的检测和预留;
- Confirm:完成资源操作业务;要求Try成功Confirm一定要能成功。
- Cancel:预留资源释放,可以理解为try的反向操作。
举例,一个扣减用户余额的业务。假设账户A原来余额是100,需要余额扣减30元。
阶段一(Try):检查余额是否充足,如果充足则冻结金额增加30元,可用余额扣除30

阶段二:假如要提交(Confirm),则冻结金额扣减30

阶段二:如果要回滚(Cancel),则冻结金额扣减30,可用余额增加30

Try、Confirm、Cancel这三个阶段都需要自己去编写代码
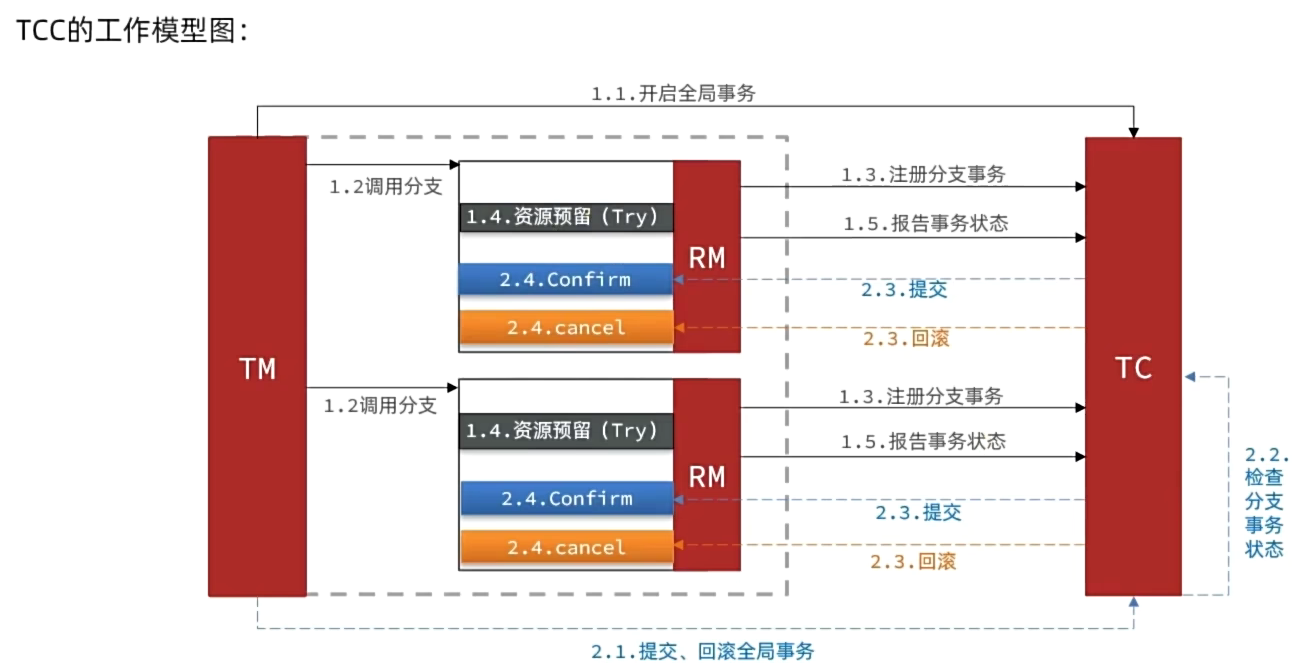
TCC的优点是什么?
- 一阶段完成直接提交事务,释放数据库资源,性能好
- 相比AT模型,无需生成快照,无需使用全局锁,性能最强
- 不依赖数据库事务,而是依赖补偿操作,可以用于非事务型数据库
TCC的缺点是什么?
- 有代码侵入,需要人为编写try、Confirm和Cancel接口,太麻烦
- 软状态,事务是最终一致
- 需要考虑Confirm和Cancel的失败情况,做好幂等处理
最大努力通知(大多数企业喜欢的解决方法)
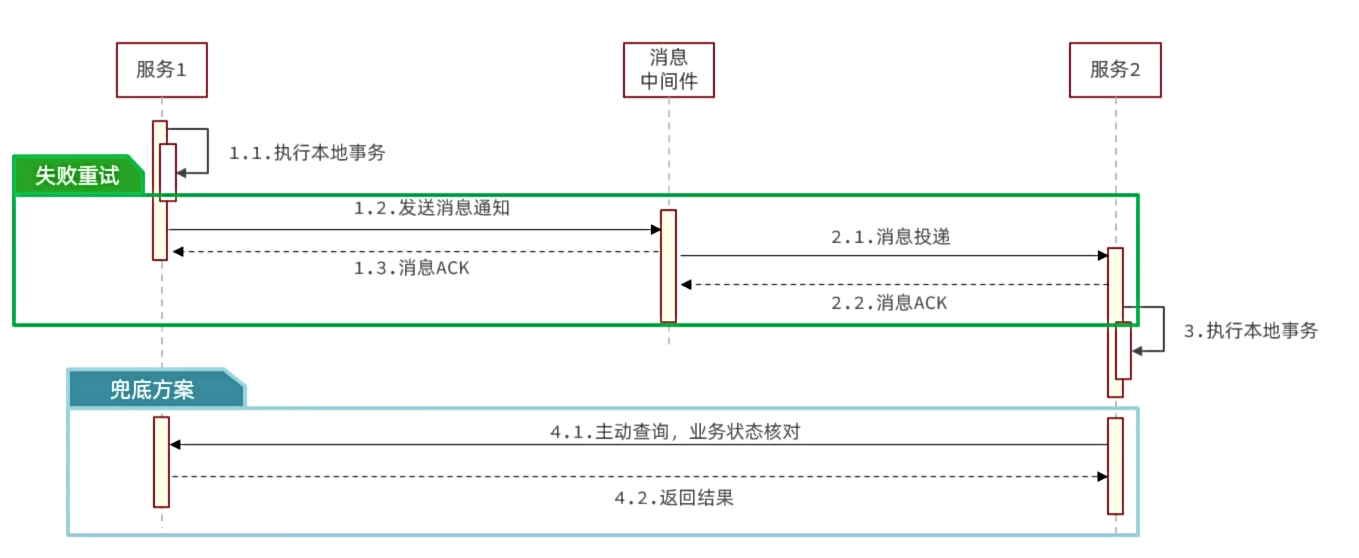
最大努力通知是一种最终一致性的分布式事务解决方案。顾明思议,就是通过消息通知的方式来通知事务参与者完成业务执行,如果执行失败会多次通知。无需任何分布式事务组件介入。有些公司连消息中间件都省了,因为依赖的事务中间件越少就越可靠
注册中心
环境隔离
企业实际开发中,往往会搭建多个运行环境,例如:开发环境、测试环境、发布环境。不同环境之间需要隔离。或者不同项目使用了一套Nacos,不同项目之间要做环境隔离。
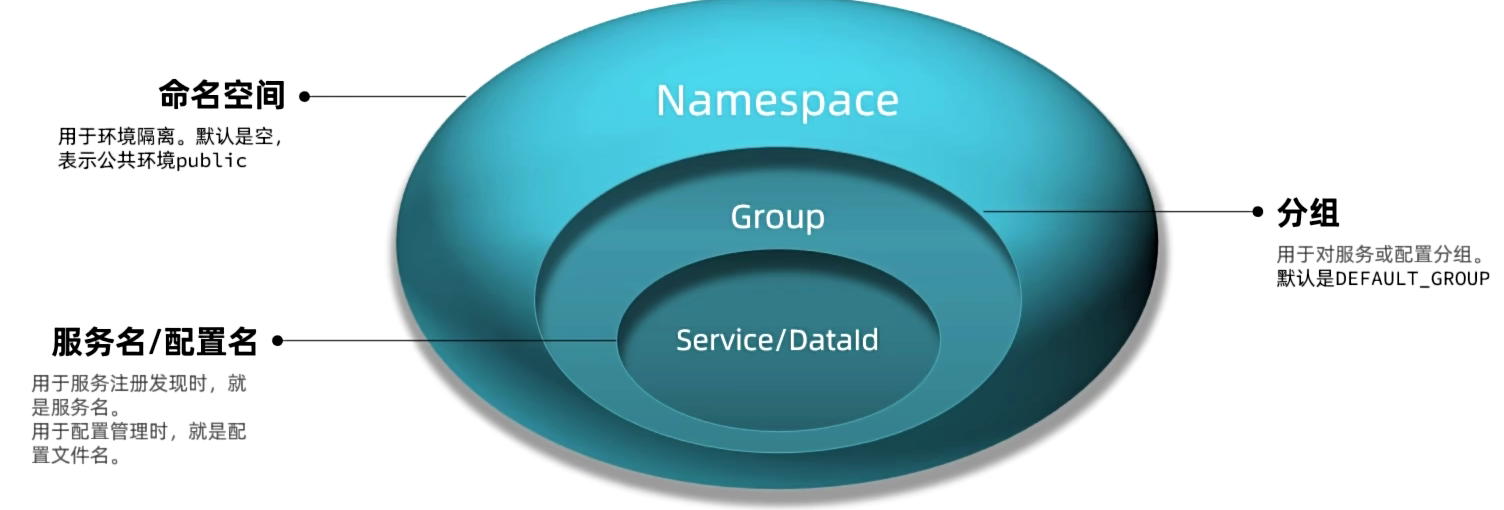
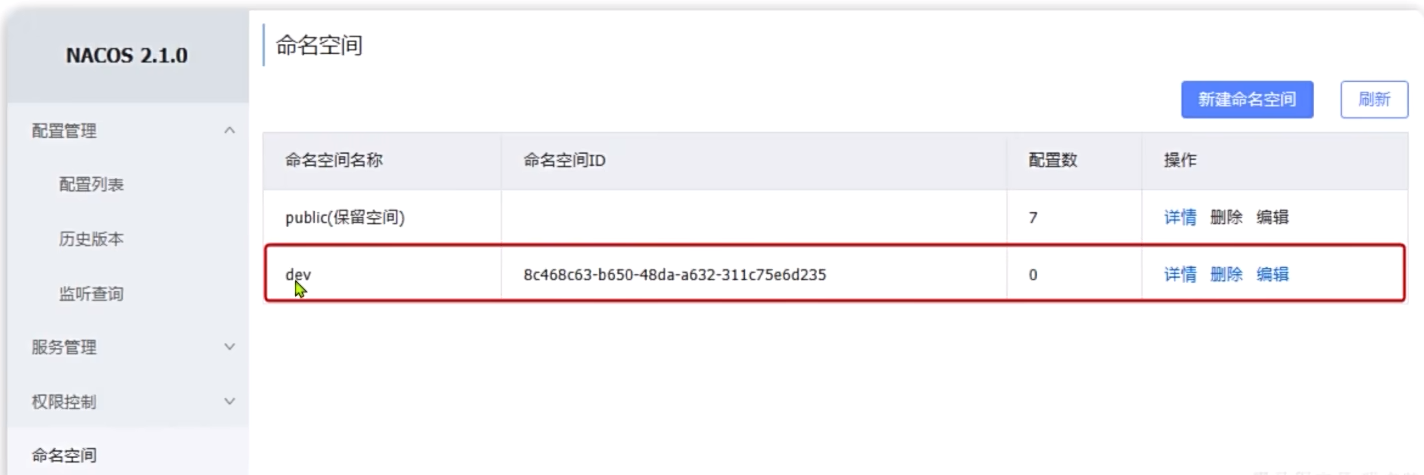
在Nacos控制台可以创建namespace,用来隔离不同环境
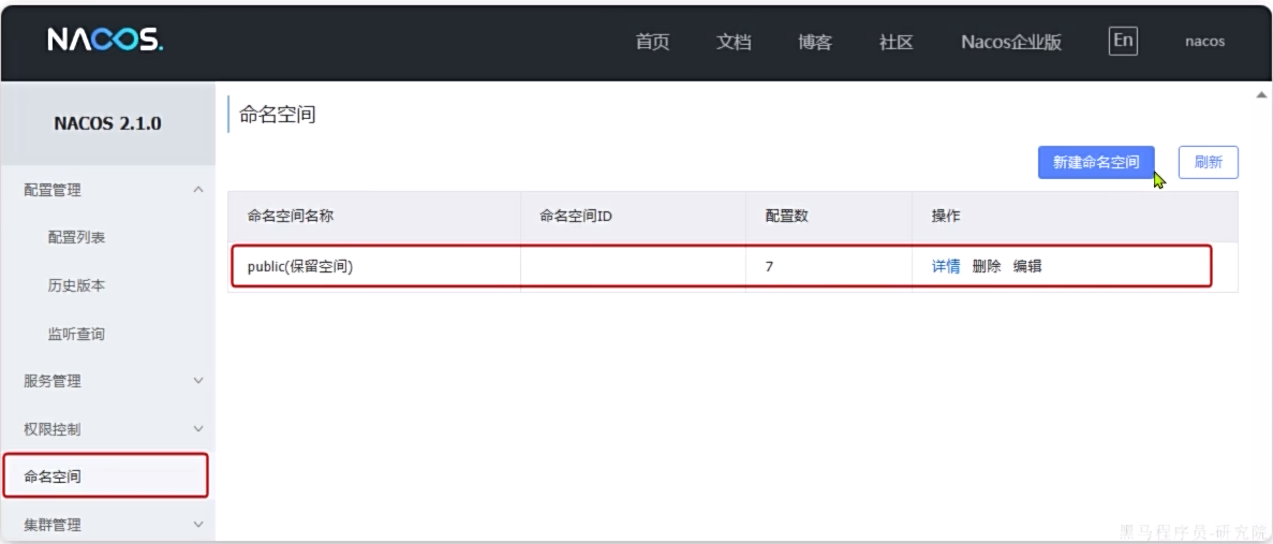
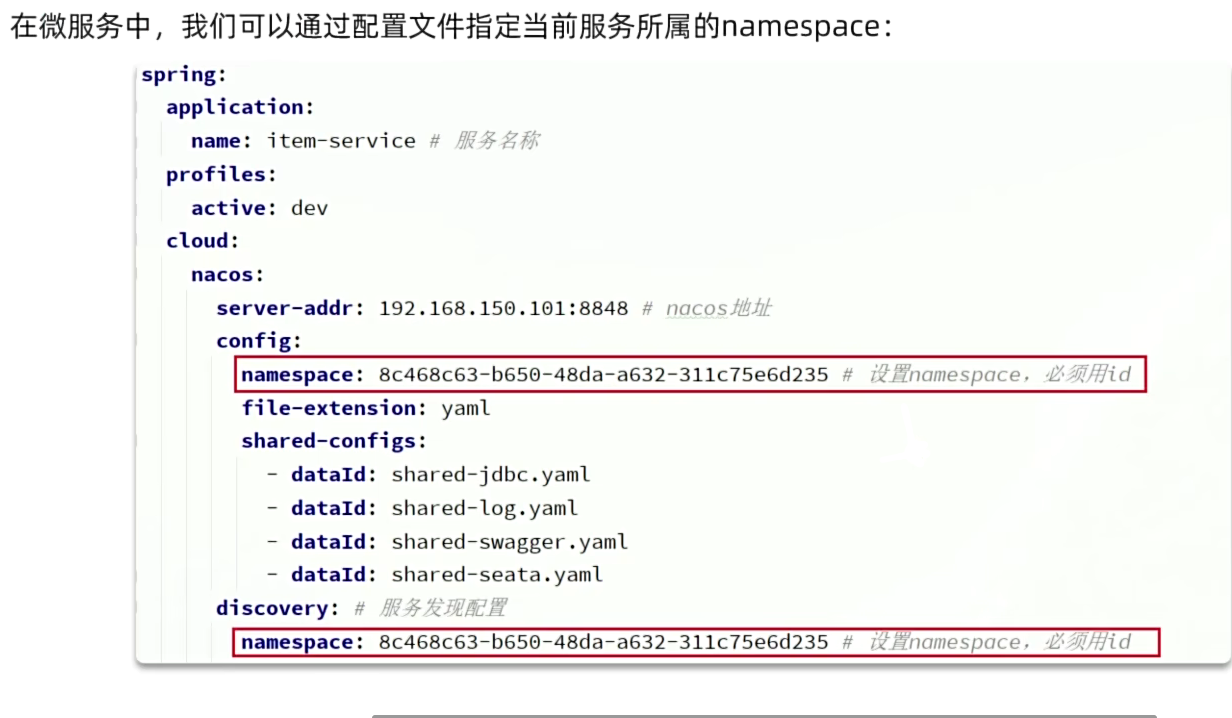
在微服务中,我们可以通过配置文件指定当前服务所属的namespace:
隔离之后要在同一个命名空间才可以互相连接
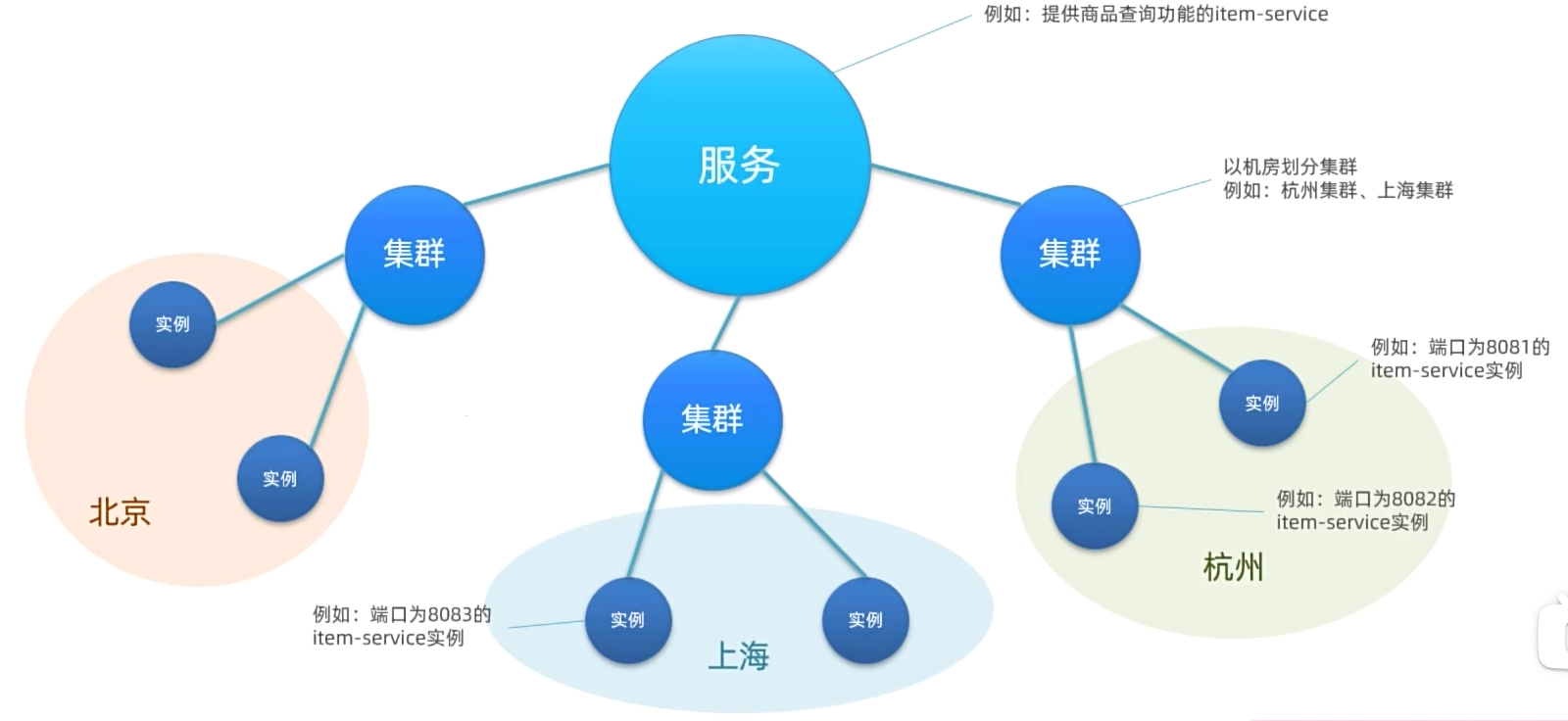
服务分级模型
大厂的服务可能部署在多个不同机房,物理上被隔离为多个集群。Nacos支持对于这种集群的划分。
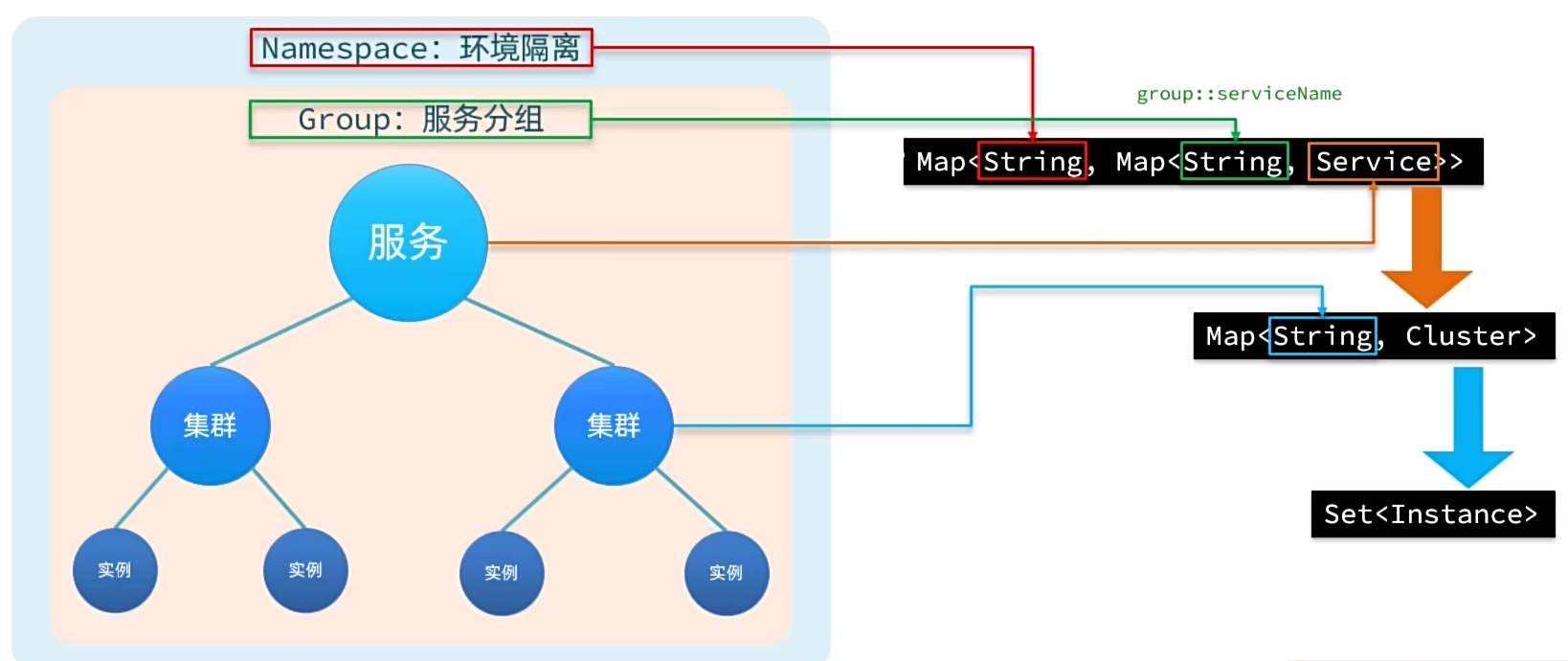
Map嵌套+Set
Eureka和Nacos
Eureka是Netflix公司开源的一个注册中心组件,目前被集成在SpringCloudNetflix这个模块下。它的工作原理与Nacos类似:
Eureka的服务端是需要人工编写的,可以通过解包Nacos的jar包来学习底层逻辑
Eureka和Nacos的原理差不多,但是功能有区别

Nacos开启主动监测要将服务改为永久实例(但是这样会导致实例挂了,都还在实例列表里,所以不好,一般不用)
区别:
- Nacos与eureka的共同点
- 都支持服务注册和服务拉取
- 都支持服务提供者心跳方式做健康检测
- Nacos与Eureka的区别
- Nacos支持服务端主动检测提供者状态:临时实例采用心跳模式,非临时实例采用主动检测模式
- 临时实例心跳不正常会被剔除,非临时实例则不会被剔除
- Nacos支持服务列表变更的消息推送模式,服务列表更新更及时
- Nacos集群默认采用AP方式,但也支持CP;Eureka采用AP方式
远程调用
源码跟踪及负载均衡
自SpringCloud2020版本开始,SpringCloud弃用Ribbon,改用Spring自己开源的Spring Cloud LoadBalancer了,我们使用的OpenFeign、Gateway都已经与其整合。
OpenFeign在整合SpringCloudLoadBalancer时,与我们手动服务发现、复杂均衡的流程类似。
- 获取serviceld,也就是服务名称
- 根据serviceld拉取服务列表
- 利用负载均衡算法选择一个服务
- 重构请求的URL路径,发起远程调用
1 | // 服务拉取的客户端 |
看源码:
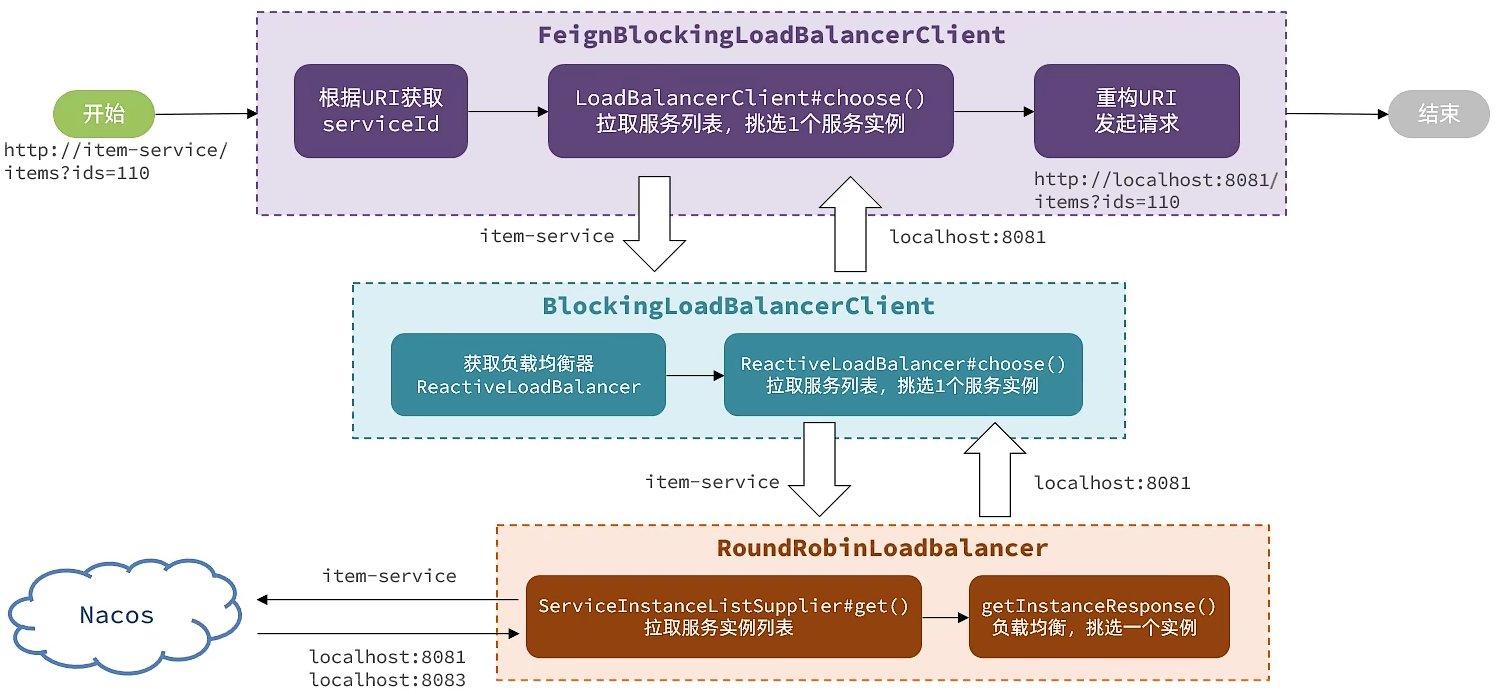
切换负载均衡算法
分析源码的时候我们发现负载均衡的算法是有ReactiveLoadBalancer来定义的,我们发现它的实现类有三个:

其中RoundRobinLoadBalancer和RandomLoadBalancer是由Spring-Cloud-Loadbalancer模块提供的,而NacosLoadBalancer则是由Nacos-Discorvery模块提供的。
默认的策略是RoundRobinLoadBalancer,即轮询负载均衡。
要修改负载均衡策略则需要覆盖SpringCloudLoadBalancer中的自动装配配置:
1 | public class LoadBalancerConfiguration { |
1 |
|
同时,在nacos中有关于配重的配置,配重的数值越高就越容易被调用到
服务保护
线程隔离方案对比
线程隔离有两种方式实现:
- 线程池隔离(Hystix默认采用)(Cloud原本的)
- 信号量隔离(Sentinel默认采用)(阿里巴巴的)
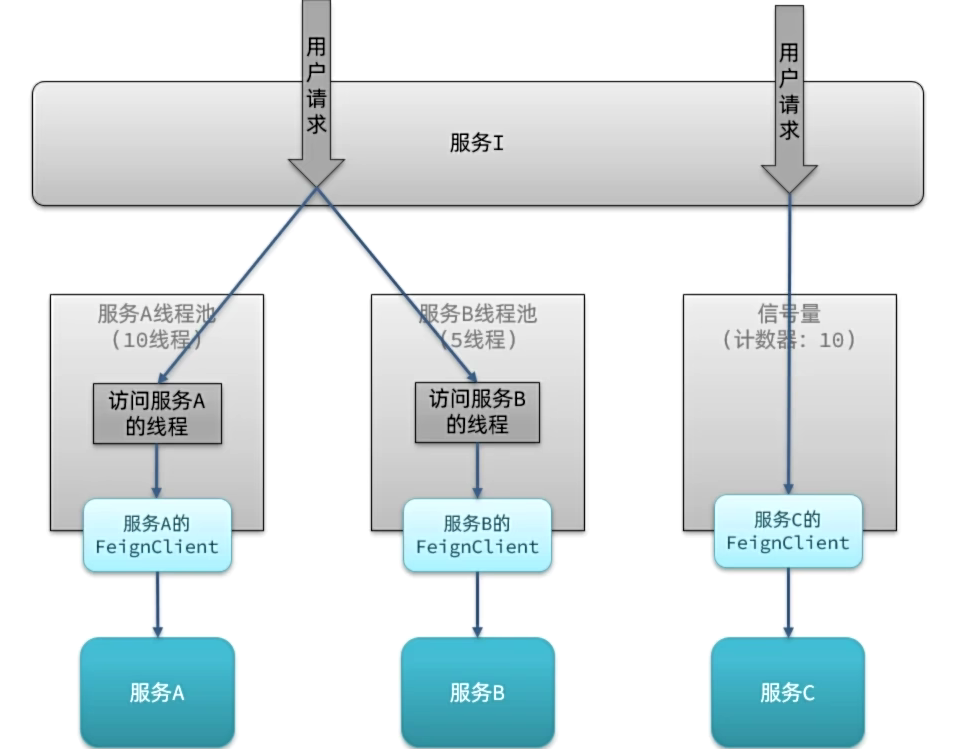
隔离是指当某个接口阻塞时,切断该接口的资源消耗,也就是阻断访问
Sentinel的线程隔离与Hystix的线程隔离有什么差别?
问题说明:考察对线程隔离方案的掌握情况
难易程度:一般
参考话术:
答:线程隔离可以采用线程池隔离或者信号量隔离。
Hystix默认是基于线程池实现的线程隔离,每一个被隔离的业务都要创建一个独立的线程池,线程过多会带来额外的CPU开销,性能一般,但是隔离性更强。
Sentinel则是基于信号量隔离的原理,这种方式不用创建线程池,性能较好,但是隔离性一般。
滑动窗口计数器算法
固定窗口计数器算法(滑动窗口计数器算法由此改进的)
固定窗口计数器算法概念如下:
- 将时间划分为多个窗口,窗口时间跨度称为Interval,本例中为1000ms;
- 每个窗口分别计数统计,每有一次请求就将计数器加一,限流就是设置计数器阈值,本例为3
- 如果计数器超过了限流阈值,则超出阈值的请求都被丢弃。
- 会出现问题
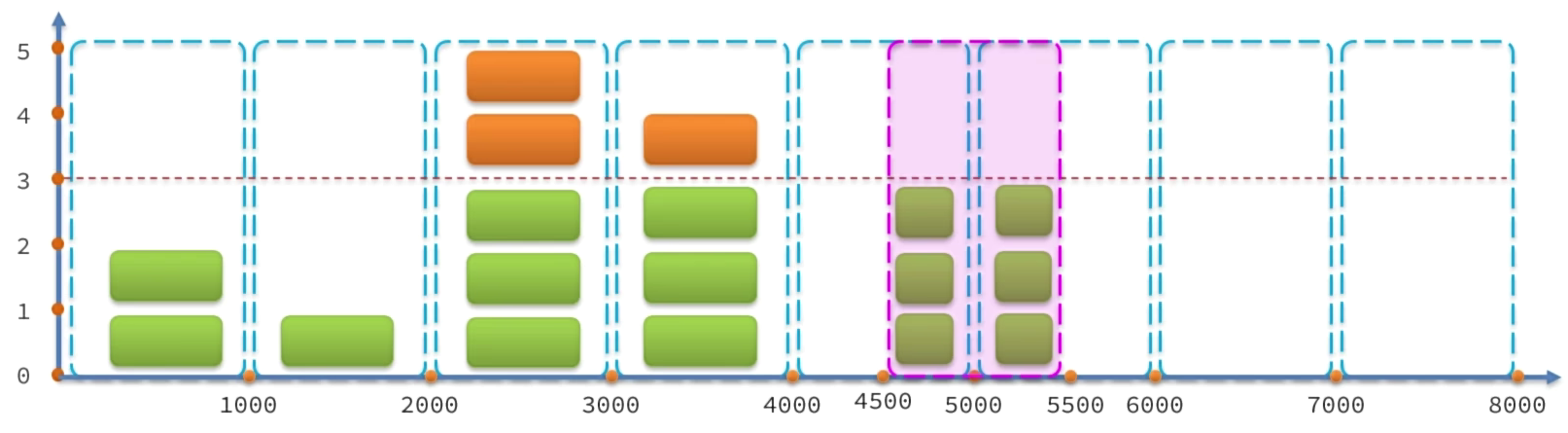
滑动窗口计数器算法
滑动窗口计数器算法会将一个窗口划分为n个更小的区间,例如
- 窗口时间跨度Interval为1秒;区间数量n=2,则每个小区间时间跨度为500ms,每个区间都有计数器
- 限流阈值依然为3,时间窗口(1秒)内请求超过阈值时,超出的请求被限流
- 窗口会根据当前请求所在时间(currentTime)移动,窗口范围是从(currentTime-Interval)之后的第一个时区开始,到currentTime所在时区结束。
- 还是有问题,出现问题就添加区间数量,保证更加精细
漏桶算法
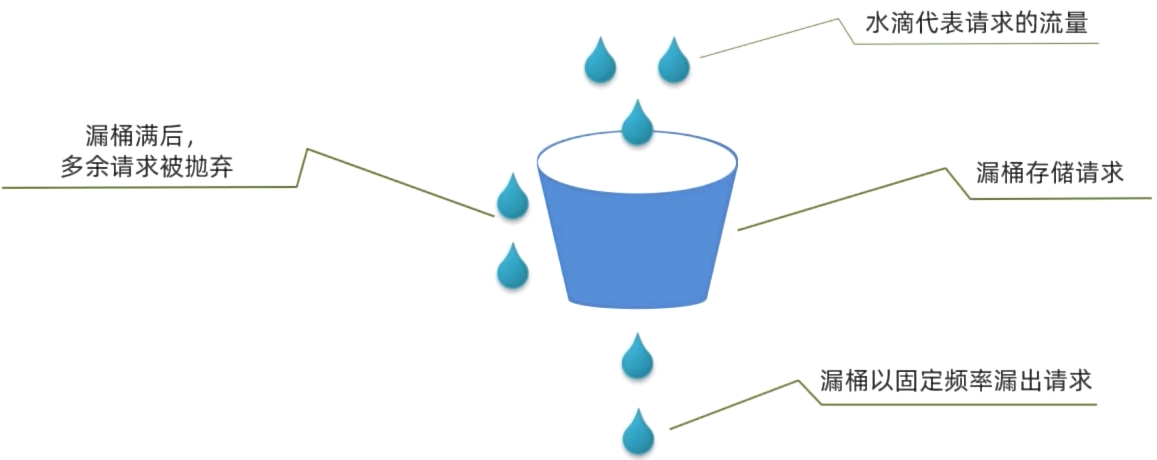
漏桶算法说明:
- 将每个请求视作”水滴”放入”漏桶”进行存储;
- “漏桶”以固定速率向外”漏”出请求来执行,如果”漏桶”空了则停止”漏水”;
- 如果“漏桶”满了则多余的”水滴“会被直接丢弃
- 可以理解成请求在桶内排队等待
Sentinel内部基于漏桶算法实现了排队等待效果,桶的容量取决限流的QPS阈值以及允许等待的最大超时时间:
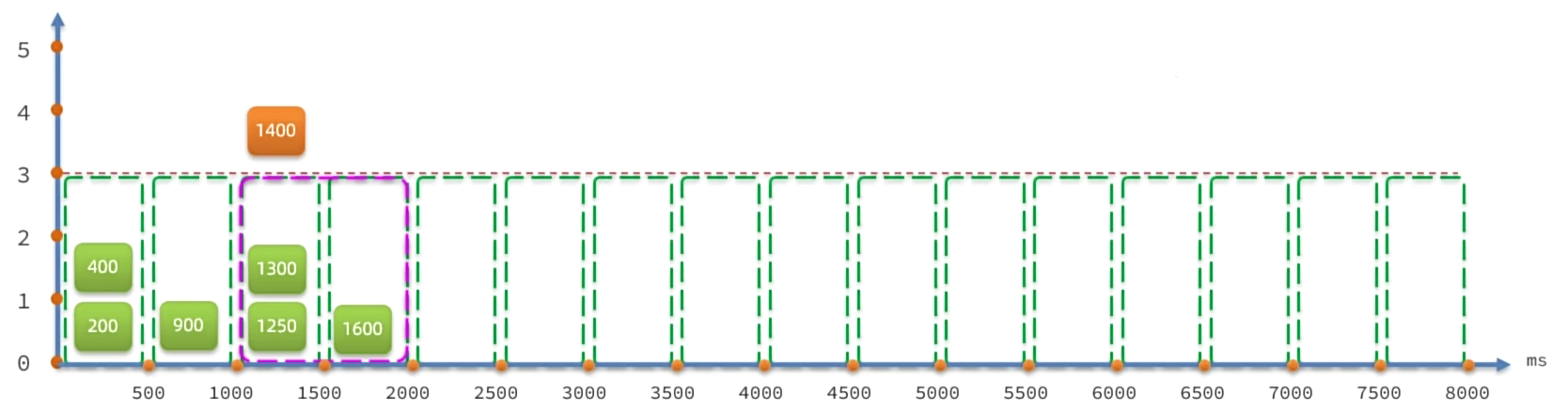
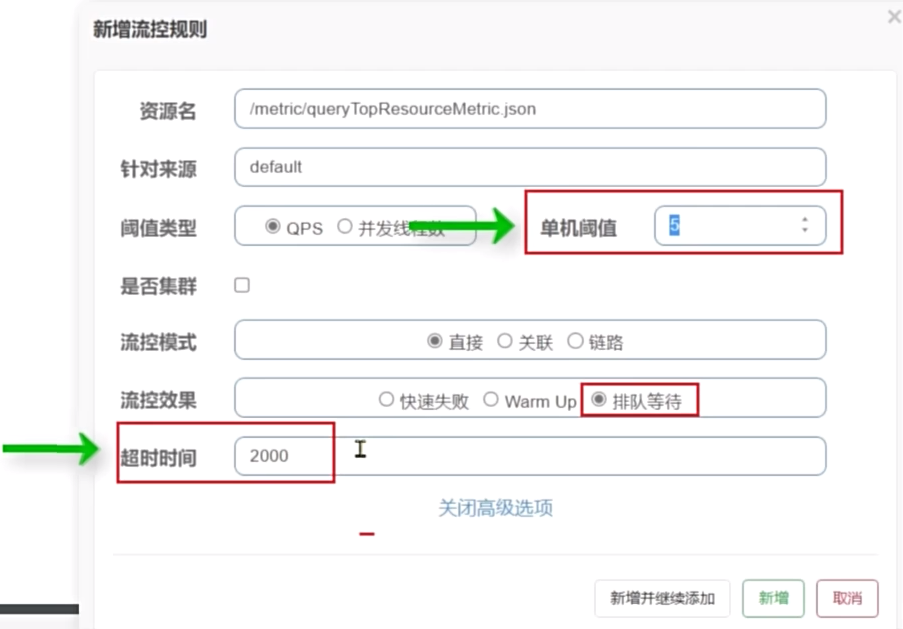
例如:限流QPS=5,队列超时时间为2000ms。我们让所有请求进入一个队列中,如同进入漏桶中。由于漏桶是固定频率执行,因此QPS为5就是每200ms执行一个请求。那第N个请求的预期的执行时间是第(N-1)*200ms。如果请求预期的执行时间超出最大时长2000ms,说明“桶满了”,新的请求则会被拒绝。
令牌桶算法(不麻烦的限流方法)
令牌桶算法说明:
- 以固定的速率生成令牌,存入令牌桶中,如果令牌桶满了以后,停止生成
- 请求进入后,必须先尝试从桶中获取令牌,获取到令牌后才可以被处理
- 如果令牌桶中没有令牌,则请求等待或丢弃
- 生成令牌的速度不能超过等于服务器的能力上限
- 可以适用于秒杀商品,是对于单个的参数去做限流的
Sentinel的限流与Gateway的限流有什么差别?
- 问题说明:考察对限流算法的掌握情况
- 难易程度:难
- 参考话术:
限流算法常见的有三种实现:滑动时间窗口、令牌桶算法、漏桶算法。Gateway则采用了基于Redis实现的令牌桶算法而Sentinel内部却比较复杂:
- 默认限流模式是基于滑动时间窗口算法,另外Sentinel中断路器的计数也是基于滑动时间窗口算法
- 限流后可以快速失败和排队等待,其中排队等待基于漏桶算法
- 而热点参数限流则是基于令牌桶算法
